生成AIを業務に取り入れる相談が増える一方で、「どこまでなら社内データを入力してよいのか」「法的に問題はないのか」といった不安の声も多く聞きます。
特に受託開発のようにクライアント固有の情報を取り扱う業務では、社内のNDA(秘密保持契約)や委託契約に加えて、生成AIサービスの利用規約やデータ処理契約(DPA)を含めた複眼的な確認が必須です。
この記事では、機密情報・営業秘密・限定提供データの定義を押さえたうえで、生成AIに入力する際のリスクと、最低限チェックしたい契約・規約のポイントをまとめます。これから生成AIの活用を検討する初心者にもわかりやすい形で整理しました。
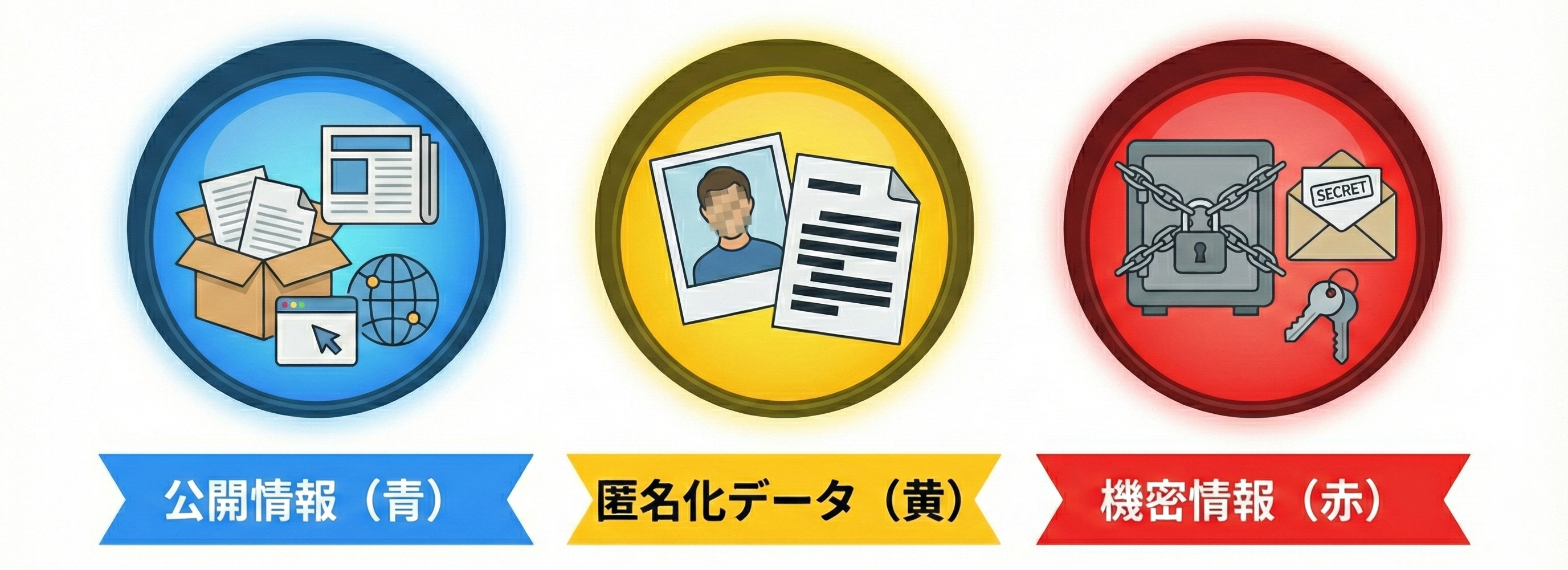
まずは、守るべき情報の定義を整理しましょう。
法律上に定義がある概念ではありませんが、社内規程や契約書で「第三者に開示しない」と定められているような、外部への開示や公表が想定されていない情報全般を指します。
顧客名簿、設計資料、価格表、NDA対象資料など、公開すると事業に不利益が生じる情報が該当し、機密レベルに応じた管理を行っている場合が多いと思われます。
不正競争防止法2条6項で定義される法的用語です。以下の3要件を満たす情報が対象で、製造ノウハウや独自のアルゴリズム、ソースコードなどが典型例です。漏えい時には民事・刑事での責任が問われることがあります。
不正競争防止法2条7項で定義される法的用語です。以下の5要件を満たす情報が対象で、ID/PWで管理された会員限定のマーケティングデータや、特定の相手にのみ共有される車両走行データなどが該当し、契約先以外へ無断で再提供することは禁止されています。
無料版や一部のコンシューマー向けAIサービスは、入力データをモデルの再学習(トレーニング)に利用することを規約で定めている場合があります。これを把握せずに機密情報を投入すると、AIがその情報を記憶し、他社のユーザーへの回答として出力してしまう(情報漏えい)リスクがあります。
NDAや準委任契約で「第三者への提供禁止」「目的外利用の禁止」を定めている場合、クラウド上のAIサービスに入力すること自体が「第三者提供」とみなされる可能性があります。AIベンダーが「委託先」として提供した機密情報を適切に管理しているか、確認が必要です。
他人が作成した著作物(ニュース記事や小説、他社のソースコードなど)を権利者の許可なく、「享受目的(表現出力目的)」を意図して生成AIに入力し、そのAI生成物を利用した場合は、著作権法30条の4等を適法化根拠とできず著作権侵害に該当します。
学習に使われない設定(オプトアウト設定)であっても、「不正利用の監視(Abuse Monitoring)」を目的として、AIツールを提供する組織が一定期間データを閲覧できる権限を持っている場合があります。極めて高度な機密情報の場合、このリスクも考慮しなければなりません。
これらはいずれもクライアントの財産であり、NDAや基本契約では通常「委託先は受領した情報を目的外利用しないものとする」「第三者への提供は禁止」と定められています。安易にWeb上の生成AIに入力した場合、以下のリスクが生じます。
原則として、「契約上第三者提供禁止」「営業秘密」「個人情報」のいずれかに該当する情報は、適切な契約(Enterprise契約等)がない限り、生成AIへ直接入力しない方針を明文化することをお勧めします。
ChatGPT(OpenAI社)を例に利用規約を紐解くと、Web版とAPI経由とでデータの扱いに大きな違いがあります。
| 項目 | Web版(無料・Plus) | Team / Enterprise版 | API経由(Platform) |
|---|---|---|---|
| 学習への利用 | デフォルトで利用される (オプトアウト設定可能) |
デフォルトで利用されない | デフォルトで利用されない |
| 不正監視の保存 | される | される(Enterpriseの一部で免除可) | される(最大30日間保持) ※一部例外申請あり |
| DPA締結 | 不可(標準規約のみ) | 可能 | 可能 |
業務システムに組み込む場合はAPI経由、あるいはEnterprise版の利用が推奨されます。これらはデフォルトで学習利用がオフになっており、DPA(データ処理契約)の対象となるため、ビジネス利用における法的整合性がとりやすいためです。
※上記は2025年12月時点のOpenAI社の仕様に基づく一般的な解釈です。
入力データがモデルの改善に使われる設定になっていないか。Web版を利用する場合はオプトアウト設定を行っているか。
入力データがどこに保存され、いつ消去されるのか(APIでも通常30日は不正監視用に保持されます)。完全に保持させない「ゼロデータ保持(ZDR)」のオプションが必要か検討します。
個人データや欧州(GDPR適用圏)のデータを扱う場合は、データ処理者としての義務(目的限定、SCC等)をカバーするDPAが締結されているか確認します。
国内法やクライアントとの契約により、データを国内サーバーに限定する必要がある場合、AIベンダーが提供するリージョン指定機能が使えるかを確認します。
ローカルLLMの場合、営業秘密の秘密管理性が失われることは考えにくいでしょう。
一方で、RAGについては注意が必要です。利用者が営業秘密を含む出力情報を、営業秘密として認識できなければ、秘密管理性を満たさなくなる可能性が生じます。
生成AIは業務効率化に大きな可能性をもたらしますが、漫然と使うだけではコンプライアンス違反のリスクを招きます。
まずは「Web版とAPI版の違い」や「学習利用の有無」を正しく理解し、社内ルールを明文化することが第一歩です。さらに、機密性の高い情報はRAGや専用環境の構築によって、セキュリティを担保しながら活用することが可能です。
Tech Funでは、生成AI活用に向けた業務棚卸から、データガバナンスのルール策定、セキュアな検証環境の構築までを支援しています。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。




