生成AIを業務で活用する文脈において、RAG(検索拡張生成: Retrieval-Augmented Generation)はもはや定番の構成になりつつあります。一方で、実際にRAGを構築しようとすると、次のような悩みに直面することも多いのではないでしょうか。
こうした課題に対して、「かなり割り切ってRAGを簡単に作れる選択肢」として登場したのがAmazon Web Services が提供するAmazon Bedrock Knowledge Baseです。さらに近年S3 Vectorsが登場したことで、従来のベクトルDBを利用する構成と比べ、比較的低コストで検証できるようになりました。
本記事では、どこまでAWSに任せるだけでRAGが成立するのかを確認するために、実際に構築してみた内容をまとめていきます。
※ 本記事は精度検証やチューニングを目的としたものではなく、PoCや検証用途を想定した内容です。
Knowledge Baseの構成は、下記のよう非常にシンプルです(下記は最低限の構成で、もちろん色々なリソースと連携できます)。
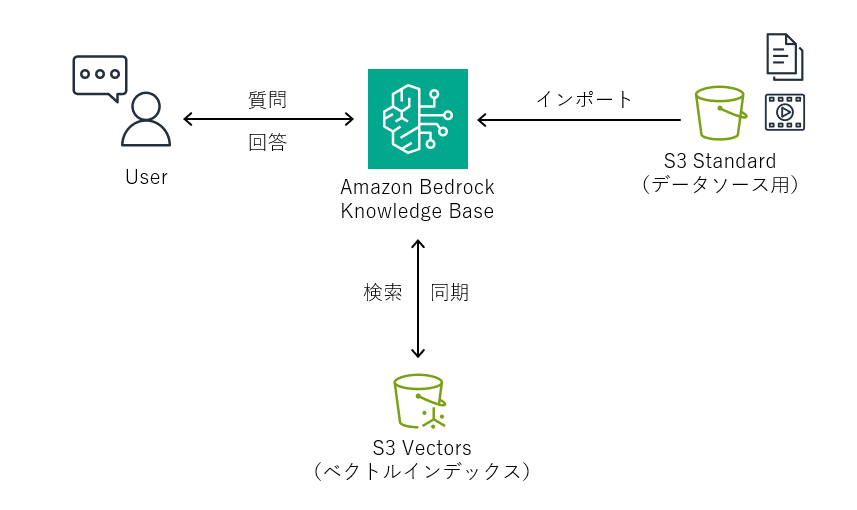
ベクトルDBのスキーマ設計などを意識する必要がなく、RAG構築の初期工程をほとんどAWS側に任せられるのが特徴です。
まずはKnowledge BaseのデータソースとなるS3バケットを作成します。なお、S3は2つ作成する必要があります。
これはGeneral purpose buckets(汎用バケット)で、デフォルト値で問題ありません。
今回のバケット名は、下記としました。
次に、Amazon Bedrockの管理画面からKnowledge Baseを作成します。Amazon Bedrock > ナレッジベース > 作成 > ベクトルストアを含むナレッジベースと進みます。
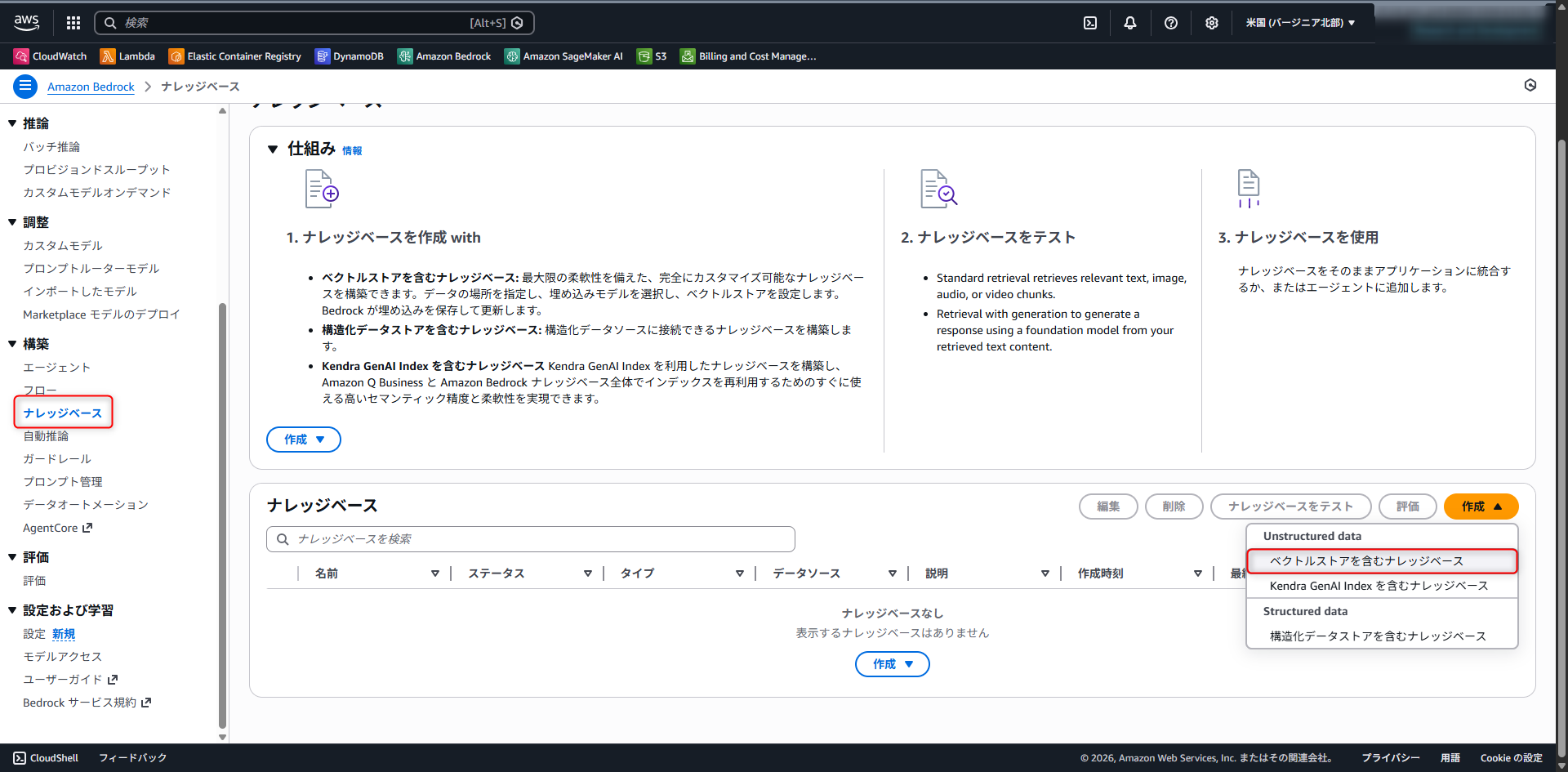
主な設定項目は以下の通りです。
※ 設定項目は、2026年1月23日のものです。AWSのバージョンアップ等により、設定項目、設定値が変更となる場合があります。
| 項目名 | 設定値 | 備考 |
|---|---|---|
| ナレッジベース名 | デフォルト | |
| ナレッジ | デフォルト | |
| IAM 許可 | 新しいサービスロールを作成して使用 | |
| データソースを選択 | Amazon S3 | |
| タグ | なし | |
| ログ配信 | なし |
| 項目名 | 設定値 | 備考 |
|---|---|---|
| データソース名 | 任意 | 今回はS3バケットと同じ名前とした |
| データソースの場所 | この AWS アカウント | |
| S3のURI | 「1. S3バケットを作成する」で作成したデータソース用のバケットを選択 | |
| 解析戦略 | パーサーとしての基盤モデル | |
| 解析用の基盤モデルを選択 | Nova 2 Lite v1 GLOBAL Amazon Nova 2 Lite | |
| パーサー向けの指示 | デフォルト | |
| チャンキング戦略 | 固定サイズのチャンキング | |
| 最大トークン | 3,072 | 使用予定のエンベディングモデルの最大値とした ※ |
| チャンク間のオーバーラップの割合 | 10 | テストなので、最低限とした |
| 変換関数 | なし | |
| 詳細設定 | デフォルト |
※ Amazon Nova Multimodal Embeddingsは実際には8,172 tokens入力できると記載があるが、ここでは3,072までしか設定できなかった。
| 項目名 | 設定値 | 備考 |
|---|---|---|
| 埋め込みモデル | Amazon Nova Multimodal Embeddings 1.0 | オンデマンドを選択 |
| ベクトルデータベース | 新しいベクトルストアをクイック作成 | |
| ベクトルストア | Amazon S3 Vectors | |
| マルチモーダルストレージの保存先 | 「1. S3バケットを作成する」で作成したマルチモーダル用のバケットを選択 |
今までの設定値が間違ってないか確認しましょう。参考までに、弊社で作成したときの設定値はこちらになります。
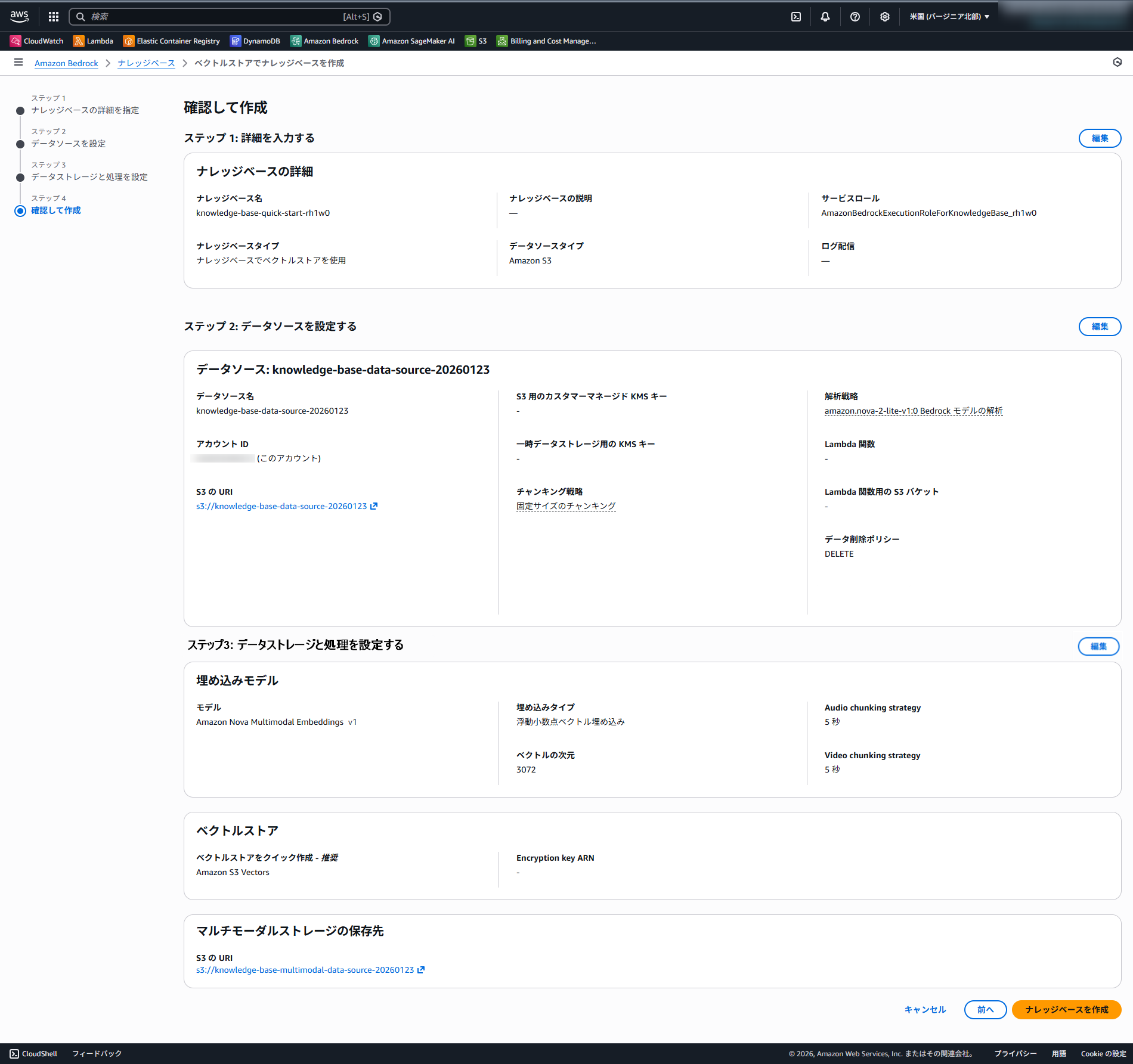
これで「ナレッジベースを作成」をすると、数分でナレッジベースが完成します。
ここから、実際にRAGとして機能するかを確認します。
Knowledge Base作成後、データソース用S3バケットにドキュメントを配置します。
今回は検証用として、以下のような簡単なデータを用意しました。
約70ファイルです。カテゴリごとにフォルダ分け等されていますが、気にせずそのままS3にアップロードしました。
S3にデータを配置した後、Knowledge BaseのSync(同期)を実行する必要があります。下記画像の同期ボタンを押して下さい。
なお、S3にドキュメントを追加しただけでは利用できないので、注意が必要です。
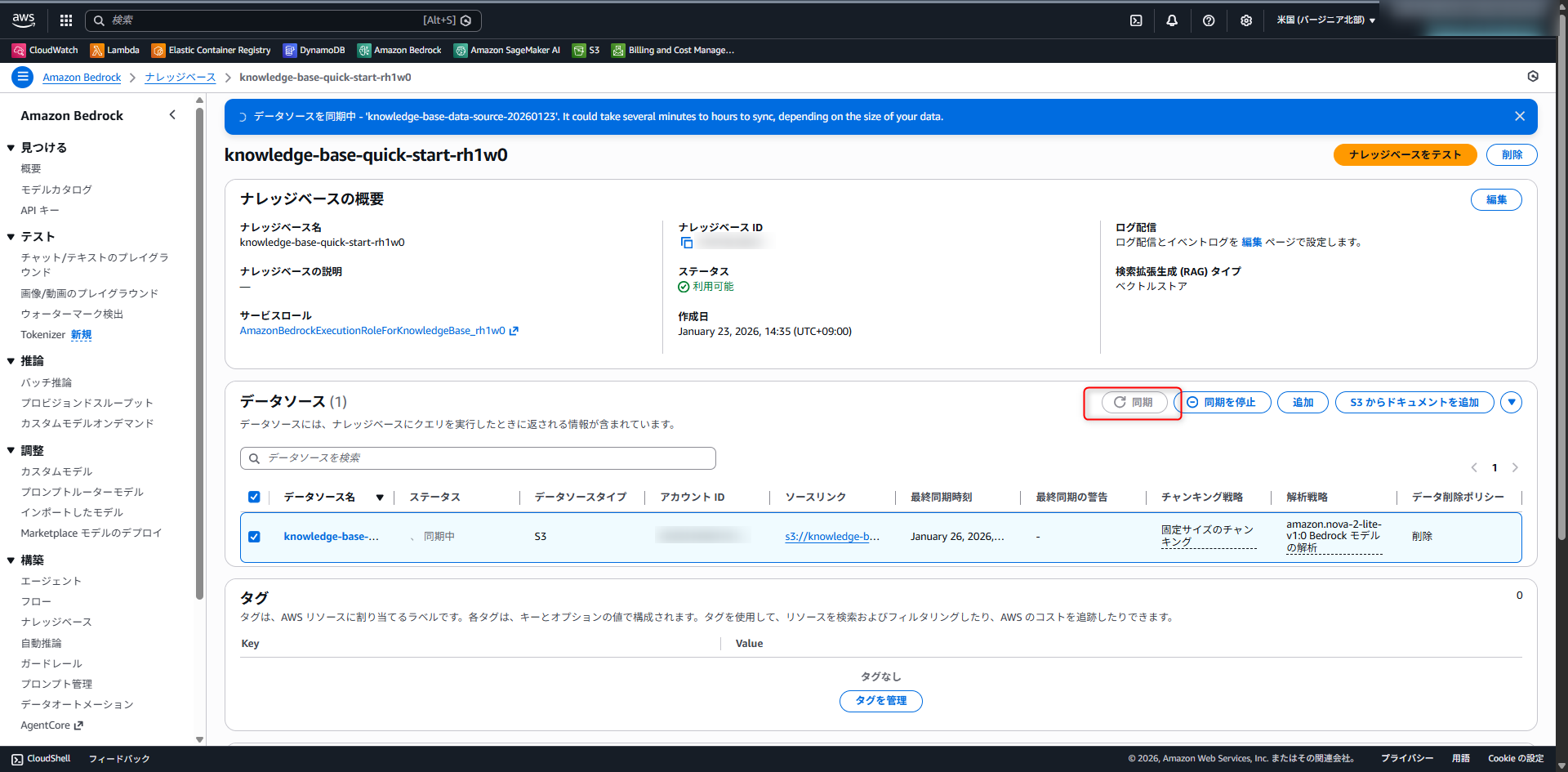
数分待つとステータスがAvailable(利用可能)に変更されます。ここで同期ボタンを押すと裏では、ドキュメントの分割やEmbedding(埋め込み)生成、ベクトル保存までが自動で行われます。
準備が整ったら、Knowledge Baseに対して質問を投げてみます。
ナレッジベースの画面右上の、「ナレッジベースをテスト」ボタンからテストできます。
「取得と応答生成」で好きなモデルを選んだら準備完了です。例えば、「引っ越しするのですが申請は必要ですか?」と質問してみましょう。
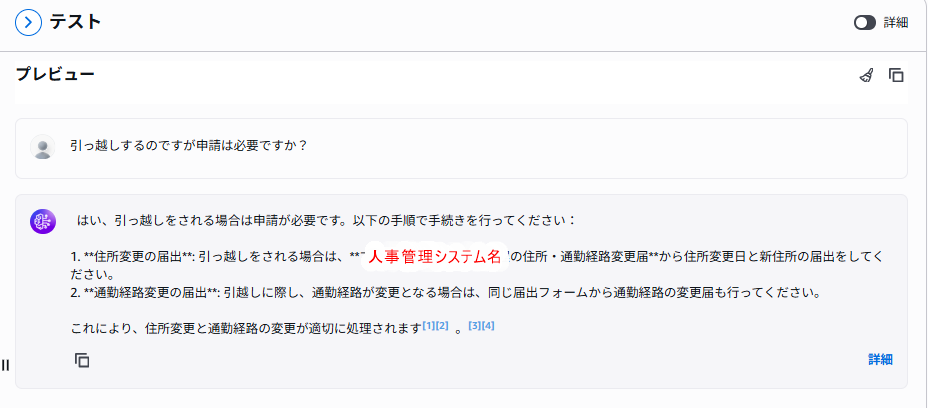
このように、先ほど格納したドキュメントに基づいて回答してくれます。また、どのドキュメントを根拠に回答しているかも確認できるため、RAGとしての要件が満たされています。
実際に Amazon Bedrock Knowledge Base と S3 Vectors を使ってみて感じた点を、メリット・デメリットに分けて整理します。
Amazon Bedrock Knowledge Base と S3 Vectors を使うことで、RAGの「最初の一歩」は驚くほど簡単に実現できます。
といった用途であれば、非常に有力な選択肢だと感じました。
特に、「RAGを本格的に作る前に全体像を把握したい」「社内説明やデモ用に、短期間で動くものを用意したい」といったケースでは、Knowledge Base と S3 Vectors の組み合わせは非常に相性が良い構成です。
一方で、本格的な精度改善や運用を行う場合は、自前実装や構成の見直しが必要になる点は留意が必要です。ナレッジベースの枠組みの中で解決できるケース(前処理関数の追加、ベクトルデータベースの変更など)もありますが、それを超えた精度改善を目指すと、構成が一気に複雑化する可能性があります。
まずはAWSマネージドな構成でRAGの感触を掴み、必要に応じて自前構成へスケールさせていく、という使い方が現実的な選択肢になりそうです。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。




