
生成AI関連
Amazon Bedrock Knowledge Base × S3 VectorsでRAGを作って…
RAG(Retrieval Augmented Generation)を構築していると、
と感じる場面は多いのではないでしょうか。Amazon Bedrockのナレッジベースでは、メタデータを活用することで、こうした要望に応えることができます。特にうまく使うと、RAGの精度や実用性を一段引き上げることが可能です。
本記事では、次の2つを実現する方法を整理していきます。
あわせて、「できること」と「できないこと」を明確にしながら、実際に実行する場合の回避策を紹介します。
本記事のナレッジベースは、下記の構成に基づいています。構成や作成方法は下記を参照下さい。
ナレッジベースでは、ドキュメント本文とは別に、任意のメタデータを付与できます。例えば、以下のような情報です。
これらのメタデータは、検索(retrieve)時の条件指定に利用できます。まず前提として、ナレッジベースではドキュメント本文とは別でメタデータファイルを用意して、登録する必要があります。
S3に配置するドキュメントでは、本文ファイルと同じ名前で .metadata.json ファイルを用意することで、メタデータを登録できます。例として、以下のような構成を考えます。
docs/
スキルアップ支援制度/
資格取得支援制度.md
資格取得支援制度.md.metadata.json
このとき、資格取得支援制度.md.metadata.json の中身は
次のように記述します。
{
"metadataAttributes": {
"category": "スキルアップ支援制度",
"documentName": "資格取得支援制度",
"url": "https://...(実際のURL: 省略)"
}
}
これらのデータをセットでS3にアップロードし、ナレッジベースで同期することでメタデータが登録されます。
メタデータフィルタを使うことで、
といった効果があります。検索対象のドキュメントが多すぎてほしい情報が得られない、ということはRAGの精度に直結するため、検索段階で母集団を絞ることは非常に重要です。
Bedrock ナレッジベースのコンソールには、検索テスト機能が用意されています。ここでメタデータフィルタを指定すると、検索結果がどのように変わるかを簡単に確認できます。
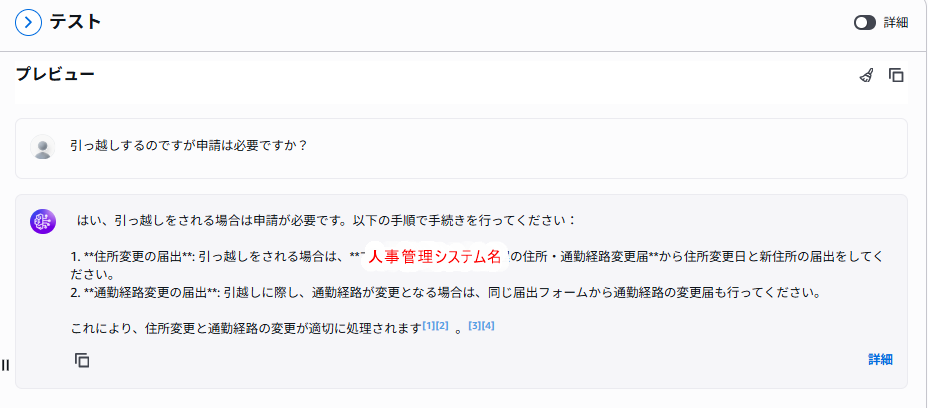
テスト画面に入ったら、まずはフィルタリング無しで質問してみましょう。下記のような結果となります。
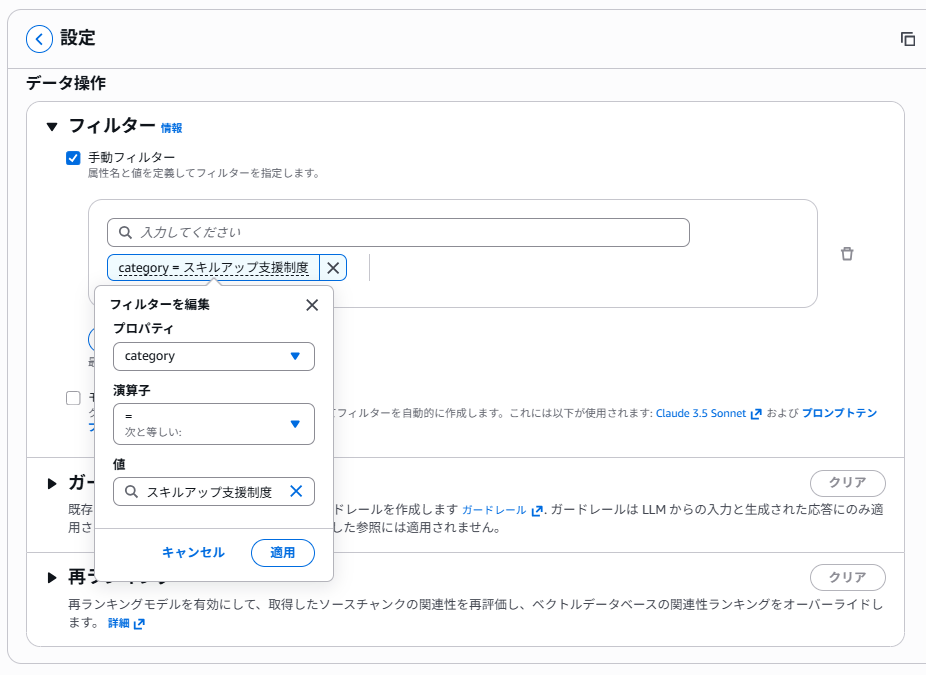
次に、フィルターを設定してから同じ質問をしてみましょう。まず設定ですが、左側でフィルター > 手動フィルターで下記のように設定します。
次に右側で、下記のように検索してみます。
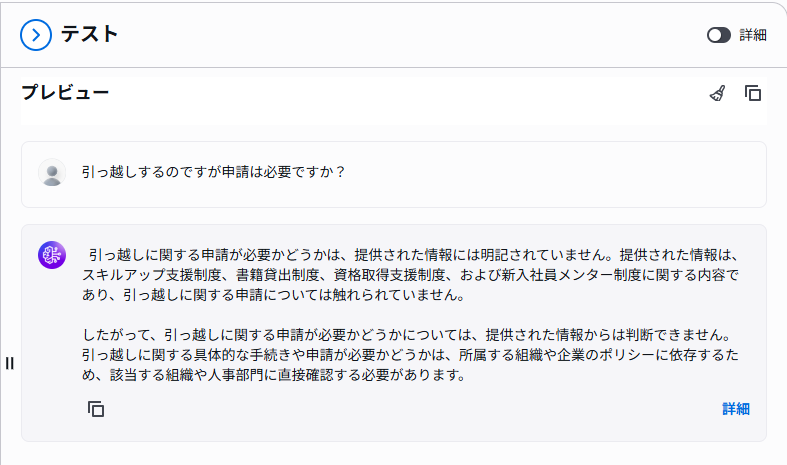
期待通り、対象のドキュメントを取得できなくなっていました。このようにナレッジベースでは、簡単にフィルタリングを実行できます。
フィルターでできることはおおよそ下記となっています。
| type | 演算子 | 意味 | 備考 |
|---|---|---|---|
| string | equals | 文字列の完全一致 | |
| string | notEquals | 文字列の不一致 | |
| string | in | 指定配列のいずれかに一致 | |
| string | startsWith | 前方一致 | ⚠️ S3 Vectorsでは非対応 |
| string | stringContains | 部分一致 | ⚠️ S3 Vectorsでは非対応 |
| number | equals | 数値の完全一致 | float でも問題なし |
| number | notEquals | 数値の不一致 | キー未設定のドキュメントも取得される |
| number | greaterThanOrEquals / lessThanOrEquals | 指定値以上(以下) | |
| number | greaterThan / lessThan | 指定値より大きい(小さい) | |
| number | in / notIn | 複数値一致 | ❌ 未対応 |
| boolean | equals | true / false 指定 | |
| boolean | notEquals | true / false 否定 | キー未設定ドキュメントも取得される |
| list | listContains | 配列に値が含まれるか | 文字列のみ(そもそも数字のリストを登録できない) |
| 複合 | andAll | 全条件一致 | |
| 複合 | orAll | いずれか一致 |
メタデータの情報は必ずしもドキュメントに含まれているわけではありません。例えば今回、弊社ポータルサイトの情報をマークダウンに起こしてRAGを作成しました。その際、回答にポータルサイトのURLを含めたいと考えるのは自然な考えとなります。
では、資格取得支援制度のページのURLを取得してみましょう。
資格取得支援制度について記載のあるポータルページのURLを教えて下さい。
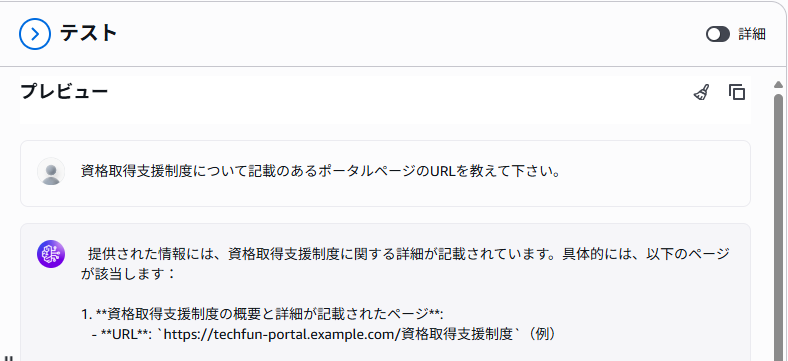
このように、一見ちゃんとURLを返してくれているように見えますが、https://techfun-portal.example.comと存在しないドメインを回答しています。ドキュメントのメタデータには url が設定されているにもかかわらず、回答にはメタデータの情報を含めることができないのです。
これは不具合ではなく、仕様どおりの挙動です。ナレッジベースにおいて、
という前提があります。そのため、メタデータにURLを入れておけば回答してくれるはずという期待は成立しません。
最もシンプルな回避策は、データ作成時にメタデータを本文へ埋め込む方法です。例えば、ドキュメント本文の冒頭や末尾に、
を明示的に記載しておくことで、LLMが参照できるようになります。この方法は実装が簡単で、ナレッジベース単体で完結しますが、
といったデメリットもあります。
より柔軟で実務向きなのが、ナレッジベースは検索専用と割り切り、回答生成を自前で制御する方法です。
この構成により、メタデータを根拠として回答に反映できます。
以下は、ナレッジベースを検索(retrieve)した結果の本文とメタデータをまとめて Nova に渡し、そこで回答生成をしてもらう実装例です。
import json
import boto3
from dotenv import load_dotenv
load_dotenv()
KNOWLEDGE_BASE_ID = "XXXXXXXXX" # ご自身のKnowledge Base IDに置き換えてください
def make_kb_client():
session = boto3.Session()
return session.client("bedrock-agent-runtime", region_name="us-east-1")
def make_bedrock_runtime_client():
session = boto3.Session()
return session.client("bedrock-runtime", region_name="us-east-1")
def retrieve_documents(query: str, k: int = 3) -> dict:
bedrock_client = make_kb_client()
response = bedrock_client.retrieve(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
retrievalQuery={"text": query},
retrievalConfiguration={
"vectorSearchConfiguration": {
"numberOfResults": k,
}
},
)
return response
def build_prompt(user_query: str, retrieval_response: dict) -> str:
results = retrieval_response.get("retrievalResults", [])
# LLMに渡すコンテキストを作る
chunks = []
for i, r in enumerate(results, start=1):
text = (r.get("content", {}) or {}).get("text", "")
meta = r.get("metadata", {}) or {}
chunks.append(
f"""\
## document-{i + 1}
### 本文
{text}
### メタデータ
{json.dumps(meta, ensure_ascii=False)}
"""
)
context = "\n".join(chunks)
prompt = f"""\
あなたは社内制度ドキュメントのアシスタントです
次の「検索結果(text)とメタデータ(metadata)」だけを根拠に回答してください
根拠に使ったdocument番号も、[1]、[2]の形で、該当箇所に一緒に示してください
例: 「〇〇」と記載があります [1]。
# 質問
{user_query}
# 検索結果
{context}
"""
return prompt
def generate_answer_with_nova(prompt: str) -> str:
runtime_client = make_bedrock_runtime_client()
res = runtime_client.converse(
modelId="arn:aws:bedrock:us-east-1:682033496318:inference-profile/us.amazon.nova-2-lite-v1:0",
messages=[{"role": "user", "content": [{"text": prompt}]}],
inferenceConfig={"maxTokens": 200, "temperature": 0.7, "topP": 0.9},
)
return res["output"]["message"]["content"][0]["text"]
def main(query: str) -> str:
retrieval = retrieve_documents(query, k=3)
print("----------- retrieve -----------")
print(json.dumps(retrieval, indent=2, ensure_ascii=False))
print("--------------------------------")
prompt = build_prompt(query, retrieval)
answer = generate_answer_with_nova(prompt)
print("----------- answer ------------")
print(answer)
print("--------------------------------")
return answer
if __name__ == "__main__":
main("資格支援取得制度について記載のあるポータルページのURLを教えて下さい")
上記コードを実行してみましょう。
----------- retrieve -----------
{
"ResponseMetadata": {...},
"retrievalResults": [
{
"content": {
"text": "(省略)",
"type": "TEXT"
},
"location": {
"s3Location": {
"uri": "s3://knowledge-base-data-source-20260123/portal-info/スキルアップ支援制度/資格取得支援制度.md"
},
"type": "S3"
},
"metadata": {
"documentName": "資格取得支援制度",
"category": "スキルアップ支援制度",
"url": "https://...",
"x-amz-bedrock-kb-chunk-id": "d37cf20d-09b0-4b58-aa21-beb6a055ad43",
"x-amz-bedrock-kb-data-source-id": "1WX35XMKPB"
},
"score": 0.48266324262208227
},
{
"content": {
"text": "(省略)",
"type": "TEXT"
},
"location": {
"s3Location": {
"uri": "s3://knowledge-base-data-source-20260123/portal-info/スキルアップ支援制度/スキルアップ支援制度.md"
},
"type": "S3"
},
"metadata": {
"documentName": "スキルアップ支援制度",
"category": "スキルアップ支援制度",
"url": "https://...",
"x-amz-bedrock-kb-chunk-id": "f04ce2e0-f03f-4259-985a-9ad2ec32c42e",
"x-amz-bedrock-kb-data-source-id": "1WX35XMKPB"
},
"score": 0.4725861319882243
},
...
]
}
--------------------------------
----------- answer ------------
資格支援取得制度について記載のあるポータルページのURLは以下の通りです。
**https://...(実際のURL: 省略)** [2]
このURLは、document-2のメタデータに記載されています。
--------------------------------
このように、メタデータを明示的にプロンプトへ渡すことで、URLなどの補足情報を根拠付きで回答に含めることが可能になります。
Amazon Bedrock のナレッジベースにおけるメタデータは、RAGを実務レベルで使いやすくするための重要な要素です。特に、検索段階でメタデータを使って対象ドキュメントを絞り込むことで、類似度検索の精度を安定させ、回答の精度を向上させることができます。
一方で、メタデータに登録した情報は、そのままでは回答生成には利用されません。ナレッジベースのテスト機能でURLなどを尋ねても取得できないのは、仕様上の制約によるものです。この挙動を理解せずに設計を進めると、「入れたはずの情報が回答に出てこない」という違和感につながります。
こうした制約に対しては、いくつかの現実的な回避策があります。小規模であれば、メタデータの内容を本文に埋め込む方法でも対応できますが、より柔軟で拡張性の高い構成を目指すのであれば、ナレッジベースを検索専用と割り切り、retrieve結果とメタデータを明示的にLLMへ渡して回答生成を制御する方法が有効です。
ナレッジベースは「すべてを自動でやってくれる仕組み」ではなく、「検索を担うコンポーネント」として捉えることで、設計の自由度は大きく広がります。メタデータをどう扱うかを意識することで、RAGはより実務に耐える仕組みへと進化していきます。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。



