
生成AI関連
プロンプトキャッシュ(コンテキストキャッシュ)とは
生成AIをシステムに組み込んでいると、「大量のデータを一括でAIに処理させたい」という場面に遭遇します。商品説明の一括生成、評価データセットの処理、ユーザーレビューの分類 ― いずれもリアルタイムの応答は不要で、数百〜数万件のリクエストをまとめて投げたいケースです。こうした場面で活躍するのがバッチAPIです。
バッチAPIを使えば、通常のAPI呼び出しと比べてコストを最大50%削減しつつ、大量のリクエストを効率よく処理できます。OpenAI・Anthropic・Googleといった主要ベンダーがそれぞれバッチ処理の仕組みを提供しており、いずれも50%のコスト割引が共通の特徴です。
本記事では、OpenAIのBatch APIを中心に仕組みと使い方を解説し(OpenAI公式ドキュメント)、Claude・Geminiでの対応状況も紹介します。
なお、APIコストを削減する別のアプローチとしてプロンプトキャッシュがあります。プロンプトの共通部分を再利用することで入力トークンのコストを削減する手法です。詳しくは以下の記事をご参照ください。
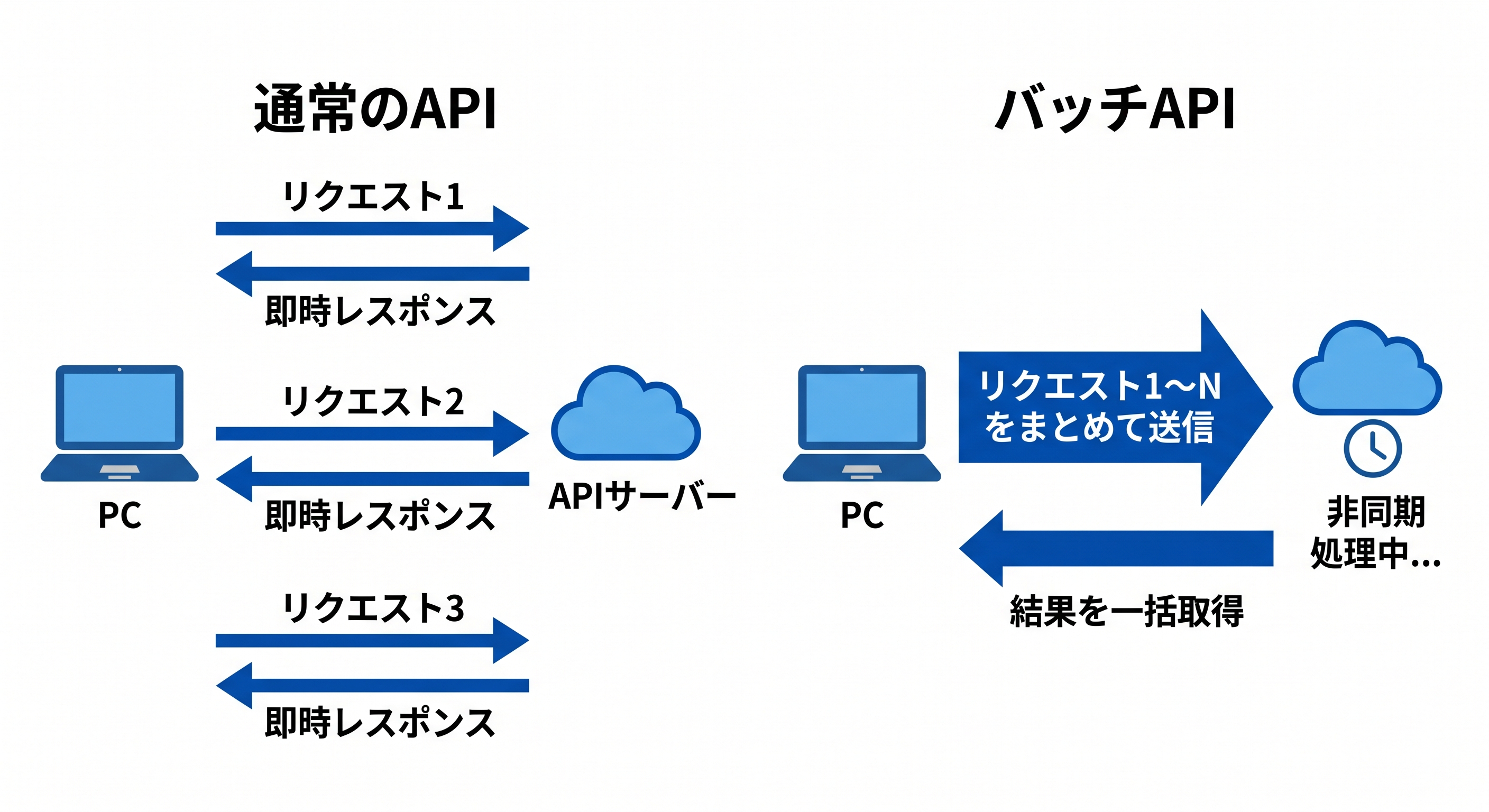
バッチAPIとは、複数のAPIリクエストを非同期でまとめて処理する仕組みです。通常のAPIは1リクエストごとにリアルタイムで応答を返しますが、バッチAPIでは「まとめて送って、あとで結果を受け取る」という流れになります。
| 項目 | 通常のAPI | バッチAPI |
|---|---|---|
| 処理方式 | 同期(リアルタイム) | 非同期(バックグラウンド) |
| レスポンス | 即時 | 最大24時間以内(多くはより早い) |
| コスト | 通常料金 | 最大50%割引 |
| レート制限 | 標準のレート制限 | 別枠のレート制限(より緩い) |
| 適したユースケース | チャット、リアルタイム応答 | 大量データ処理、評価、一括変換 |
ポイントは、バッチAPIは即時応答が不要な処理に特化しているという点です。リアルタイム性を犠牲にする代わりに、コスト削減を実現しています。
OpenAIのBatch APIは、JSONLファイルにリクエストをまとめて送信し、結果をJSONLファイルで受け取るシンプルな設計です。
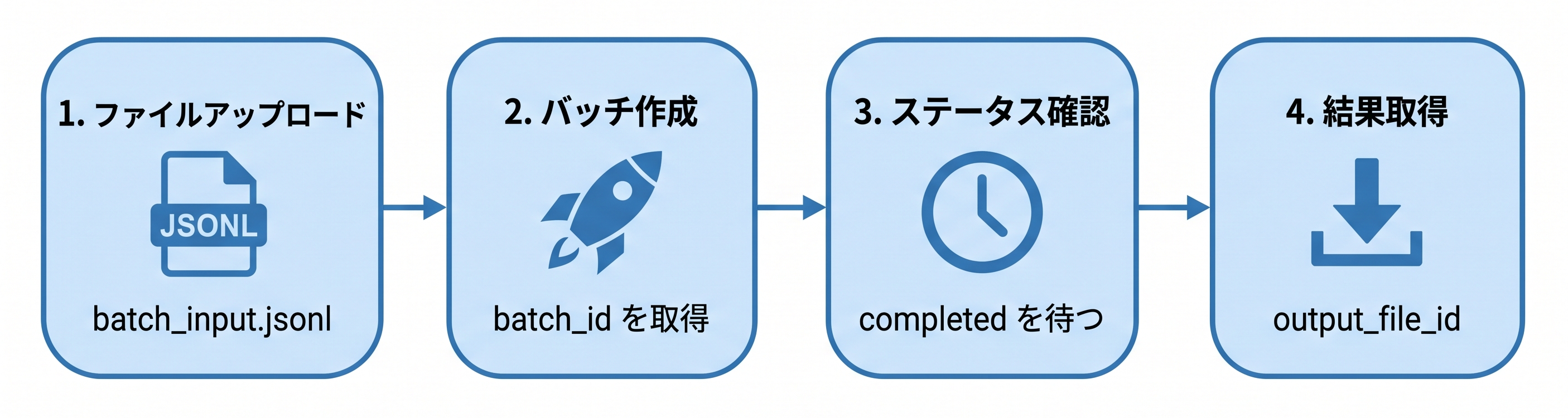
バッチAPIの処理は、大きく4つのステップで構成されます。
バッチAPIは以下のエンドポイントに対応しています。テキスト生成だけでなく、画像生成やビデオ生成にも対応しており、幅広いユースケースで活用できます。
| エンドポイント | 用途 |
|---|---|
| /v1/responses | Responses API |
| /v1/chat/completions | Chat Completions |
| /v1/embeddings | Embeddings |
| /v1/completions | Completions |
| /v1/moderations | Moderations |
| /v1/images/generations | 画像生成 |
| /v1/images/edits | 画像編集 |
| /v1/videos | ビデオ生成 |
入力はJSONL(JSON Lines)形式で、1行が1リクエストに対応します。各リクエストには結果と紐づけるための custom_id を設定します。通常のChat Completions APIと同様に、システムプロンプトも指定できます。
{"custom_id": "request-1", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-5.4-mini", "messages": [{"role": "system", "content": "あなたは技術用語を初心者にもわかりやすく説明するアシスタントです。回答は3文以内で簡潔にまとめてください。"}, {"role": "user", "content": "Pythonのリスト内包表記について教えてください。"}], "max_completion_tokens": 500}}
{"custom_id": "request-2", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-5.4-mini", "messages": [{"role": "system", "content": "あなたは技術用語を初心者にもわかりやすく説明するアシスタントです。回答は3文以内で簡潔にまとめてください。"}, {"role": "user", "content": "HTTPステータスコード404と500の違いを説明してください。"}], "max_completion_tokens": 500}}
{"custom_id": "request-3", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-5.4-mini", "messages": [{"role": "system", "content": "あなたは技術用語を初心者にもわかりやすく説明するアシスタントです。回答は3文以内で簡潔にまとめてください。"}, {"role": "user", "content": "データベースのインデックスはなぜ必要ですか?"}], "max_completion_tokens": 500}}
| 項目 | 内容 |
|---|---|
| 1バッチあたりの上限 | 最大50,000リクエスト |
| ファイルサイズ上限 | 200MB |
| 完了期限 | 24時間(多くはより早く完了) |
| コスト | 通常料金の50%(入力・出力トークン共に) |
| 結果の保持期間 | バッチ完了後30日間(ビデオは24時間) |
| バッチ作成レート制限 | 1時間あたり最大2,000バッチ |
バッチの処理状況は以下のステータスで管理されます。
| ステータス | 説明 |
|---|---|
| validating | 入力ファイルを検証中 |
| in_progress | リクエストを処理中 |
| finalizing | 結果を準備中 |
| completed | 処理完了(結果をダウンロード可能) |
| expired | 24時間以内に完了しなかった |
| cancelling | キャンセル処理中 |
| cancelled | キャンセル済み |
| failed | 入力ファイルの検証失敗 |
実際にOpenAI APIを使って、バッチAPIの動作を確認してみましょう。複数の質問を一括で処理するシナリオで実装します。
今回のデモでは、以下の流れで実装します。
まず、処理対象の質問をJSONLファイルとして用意します。今回はシステムプロンプトで「初心者向けに3文以内で回答する」というルールを設定し、5件の技術的な質問を投げます。
以下は入力ファイルの1行目を整形したものです。
{
"custom_id": "q-001",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-5.4-mini",
"messages": [
{
"role": "system",
"content": "あなたは技術用語を初心者にもわかりやすく説明するアシスタントです。回答は3文以内で簡潔にまとめてください。"
},
{
"role": "user",
"content": "Pythonのリスト内包表記について教えてください。"
}
],
"max_completion_tokens": 500
}
}
各リクエストには custom_id を設定します。この値が結果と元データを紐づけるキーになります。実際のJSONLファイルでは、このようなJSONを1行1リクエストで記述していきます。
今回は共通のシステムプロンプトを設定し、以下の5件の質問を用意しました。
| custom_id | 質問内容 |
|---|---|
| q-001 | Pythonのリスト内包表記について教えてください。 |
| q-002 | HTTPステータスコード404と500の違いを説明してください。 |
| q-003 | データベースのインデックスはなぜ必要ですか? |
| q-004 | RESTとGraphQLの主な違いを3つ挙げてください。 |
| q-005 | Gitでブランチを使う利点を教えてください。 |
JSONLファイルをアップロードし、バッチを作成します。
import argparse
from dotenv import load_dotenv
from openai import OpenAI
def main() -> None:
load_dotenv()
parser = argparse.ArgumentParser(description="JSONLファイルをバッチAPIで実行する")
parser.add_argument("input_file", help="入力JSONLファイルのパス")
parser.add_argument(
"--endpoint",
default="/v1/chat/completions",
help="バッチAPIのエンドポイント(デフォルト: /v1/chat/completions)",
)
args = parser.parse_args()
client = OpenAI()
# 1. ファイルをアップロード
with open(args.input_file, "rb") as f:
file = client.files.create(file=f, purpose="batch")
print(f"ファイルアップロード完了: {file.id}")
# 2. バッチを作成
batch = client.batches.create(
input_file_id=file.id,
endpoint=args.endpoint,
completion_window="24h",
)
print(f"バッチ作成完了: {batch.id}")
print(f"ステータス: {batch.status}")
if __name__ == "__main__":
main()
completion_window には "24h" を指定します。これはバッチ処理の完了期限で、現時点ではこの値のみ対応しています。実際には多くのバッチがこれよりも早く完了します。
バッチの処理には時間がかかるため、定期的にステータスを確認します。completed になったら出力ファイルをダウンロードします。なお、バッチIDを控え忘れた場合は client.batches.list() で過去のバッチ一覧を取得できます。
import argparse
from dotenv import load_dotenv
from openai import OpenAI
def main() -> None:
load_dotenv()
parser = argparse.ArgumentParser(description="バッチAPIのステータス確認と結果取得")
parser.add_argument("batch_id", help="バッチID(例: batch_abc123)")
args = parser.parse_args()
client = OpenAI()
# ステータスを確認
batch = client.batches.retrieve(args.batch_id)
counts = batch.request_counts
print(f"バッチID: {batch.id}")
print(f"ステータス: {batch.status}")
print(f"進捗: {counts.completed}/{counts.total} 完了")
if batch.status != "completed":
raise SystemExit(0)
# 結果を取得
result_content = client.files.content(batch.output_file_id).text
print(result_content)
if __name__ == "__main__":
main()
completed になるまで数分おきに実行して確認します。なお、このステータス確認をループ処理(ポーリング)として組むことも可能です。
なお、この実装は簡易的なもので、エラーが出る想定をしていません。
出力もJSONL形式で返ってきます。以下は結果の1行を整形したものです。
{
"id": "batch_req_XXXXXXXXXXXX",
"custom_id": "q-001",
"response": {
"status_code": 200,
"request_id": "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX",
"body": {
"id": "chatcmpl-XXXXXXXXXXXX",
"object": "chat.completion",
"created": 1776148910,
"model": "gpt-5.4-mini-2026-03-17",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Pythonのリスト内包表記は、**for文でリストを作る処理を1行で簡潔に書ける**書き方です。 \nたとえば `[x * 2 for x in range(5)]` は、0〜4を2倍した `[0, 2, 4, 6, 8]` を作ります。 \nさらに `if` を付けて、条件に合う要素だけを集めることもできます。",
"refusal": null,
"annotations": []
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 60,
"completion_tokens": 111,
"total_tokens": 171,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"service_tier": "default",
"system_fingerprint": null
}
},
"error": null
}
custom_id で元のリクエストと結果を紐づけることができます。出力ファイル内のリクエスト順は入力と一致する保証がないため、この custom_id でのマッピングが重要です。
なお、バッチ内で一部のリクエストが失敗した場合、成功分は output_file_id から、失敗分は error_file_id から取得できます。24時間以内に完了しなかったリクエストには batch_expired エラーが記録されます。
バッチAPIを効果的に使うための設計上のポイントをまとめます。
custom_id は結果と元データを紐づける唯一の手段です。出力ファイルのリクエスト順は入力と一致する保証がないため、custom_id で確実にマッピングする必要があります。
実務では、データベースのレコードIDや処理対象のドキュメントIDなど、元データを特定できる値を設定しましょう。
バッチ処理の完了期限は24時間です。期限内に処理が完了しなかったリクエストは batch_expired エラーとなりますが、期限内に完了したリクエストは正常に課金・取得できます。大量のリクエストを扱う場合は、バッチの進捗を定期的に確認しましょう。
バッチAPIの仕組みはベンダーごとに異なります。以下のテーブルに主要な違いをまとめました(OpenAI公式ドキュメント 、Anthropic公式ドキュメント 、Google AI公式ドキュメント)。
| 比較軸 | OpenAI | Claude(Anthropic) | Gemini(Google) |
|---|---|---|---|
| API名称 | Batch API | Message Batches API | Batch API |
| 入力形式 | JSONLファイルアップロード | APIリクエストで直接送信 | インライン / JSONLファイル |
| 1バッチの上限 | 50,000リクエスト / 200MB | 100,000リクエスト / 256MB | インライン: 20MB / ファイル: 2GB |
| 完了期限 | 24時間(多くはより早く完了) | 24時間(多くは1時間以内) | 24時間目標(多くはこれよりはるかに早く終了) |
| コスト割引 | 50%オフ | 50%オフ | 50%オフ |
| 結果の保持期間 | 30日間(ビデオは24時間) | 29日間 | 記載なし |
バッチAPIが特に効果を発揮するのは、大量のデータを同じルールで処理するパターンです。
| ユースケース | 処理内容 | バッチAPIが有効な理由 |
|---|---|---|
| 大規模評価(Evaluation) | テストケースの一括評価 | 数千件のテストを低コストで実行 |
| コンテンツモデレーション | ユーザー投稿の一括チェック | リアルタイム性不要で大量処理 |
| 商品説明の一括生成 | ECサイトの商品データから説明文を生成 | 数百〜数万件の商品を一括処理 |
| ドキュメント翻訳 | マニュアルや契約書の大量翻訳 | 即時性が不要で、コスト削減効果が大きい |
| データラベリング | 学習データへのラベル付け | 大量データに対して一貫したルールで処理 |
いずれも「即時応答は不要だが、大量のデータを一括で処理したい」というパターンです。このパターンに当てはまるシステムでは、通常のAPIをバッチAPIに置き換えるだけでコストを半減できます。
リアルタイム応答が不要な大量処理を行っている場合、バッチAPIへの切り替えを検討してみてはいかがでしょうか。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。



