
生成AI関連
Structured Outputsの基本と実践
生成AIをシステムに組み込むと、「同じシステムプロンプトを毎回送っている」ことに気づく瞬間があります。メール要約、問い合わせ分類、ドキュメント解析 ― ユーザー入力は毎回変わっても、AIへの指示やスキーマ定義は固定であることがほとんどです。この「毎回同じ部分」を賢く再利用する仕組みがプロンプトキャッシュです。OpenAIでは自動的に適用され、コード変更なしでコスト削減が見込めます(OpenAI公式ドキュメント)。
本記事では、OpenAIを中心にプロンプトキャッシュの仕組みと設計のコツを解説し、Claude・Geminiでの対応状況も比較します。また、Structured Outputとの相性や、実務でのユースケースにも触れていきます。
過去にStructured Outputsの基本を扱った記事もありますので、併せてご参照ください。
プロンプトキャッシュとは、APIリクエストの入力トークンのうち、前回と同じプレフィックス(先頭部分)をサーバー側で再利用する仕組みです。OpenAIやAnthropicでは「Prompt Caching」、Googleでは「Context Caching(コンテキストキャッシュ)」と呼ばれており、ベンダーによって名称は異なりますが、基本的な考え方は共通しています。本記事では総称として「プロンプトキャッシュ」と表記します。
通常、LLMはリクエストごとにすべての入力トークンを処理します。しかし、システムプロンプトやツール定義など、リクエスト間で変わらない部分を毎回ゼロから処理するのは無駄です。プロンプトキャッシュは、この共通部分の処理結果(内部的にはKVキャッシュと呼ばれるアテンション層の中間データ)をサーバーに保持し、次のリクエストで再利用します。
ポイントは、キャッシュが効くのはプロンプトの先頭から一致する部分だけという点です。途中や末尾が同じでも、先頭が異なればキャッシュは効きません。
OpenAIのプロンプトキャッシュは自動的に動作します。コードの変更や明示的な設定は不要です。
| 項目 | 内容 |
|---|---|
| 最小トークン数 | 1,024トークン以上 |
| キャッシュ保持期間(デフォルト) | 5〜10分(最大1時間) |
| キャッシュ保持期間(拡張) | 最大24時間(対応モデルに制限あり) |
| キャッシュトークン料金 | 通常入力の75〜90%オフ(自動適用) |
| 対応モデル | gpt-5.x / gpt-4.1 など |
以下の要素がキャッシュの対象になります。
APIレスポンスの usage フィールドで確認できます。
# レスポンスの usage から cached_tokens を取得
usage = response.usage
print(f"入力トークン: {usage.input_tokens}")
print(f"キャッシュトークン: {usage.input_tokens_details.cached_tokens}")
cached_tokens が 0 より大きければ、キャッシュが効いています。
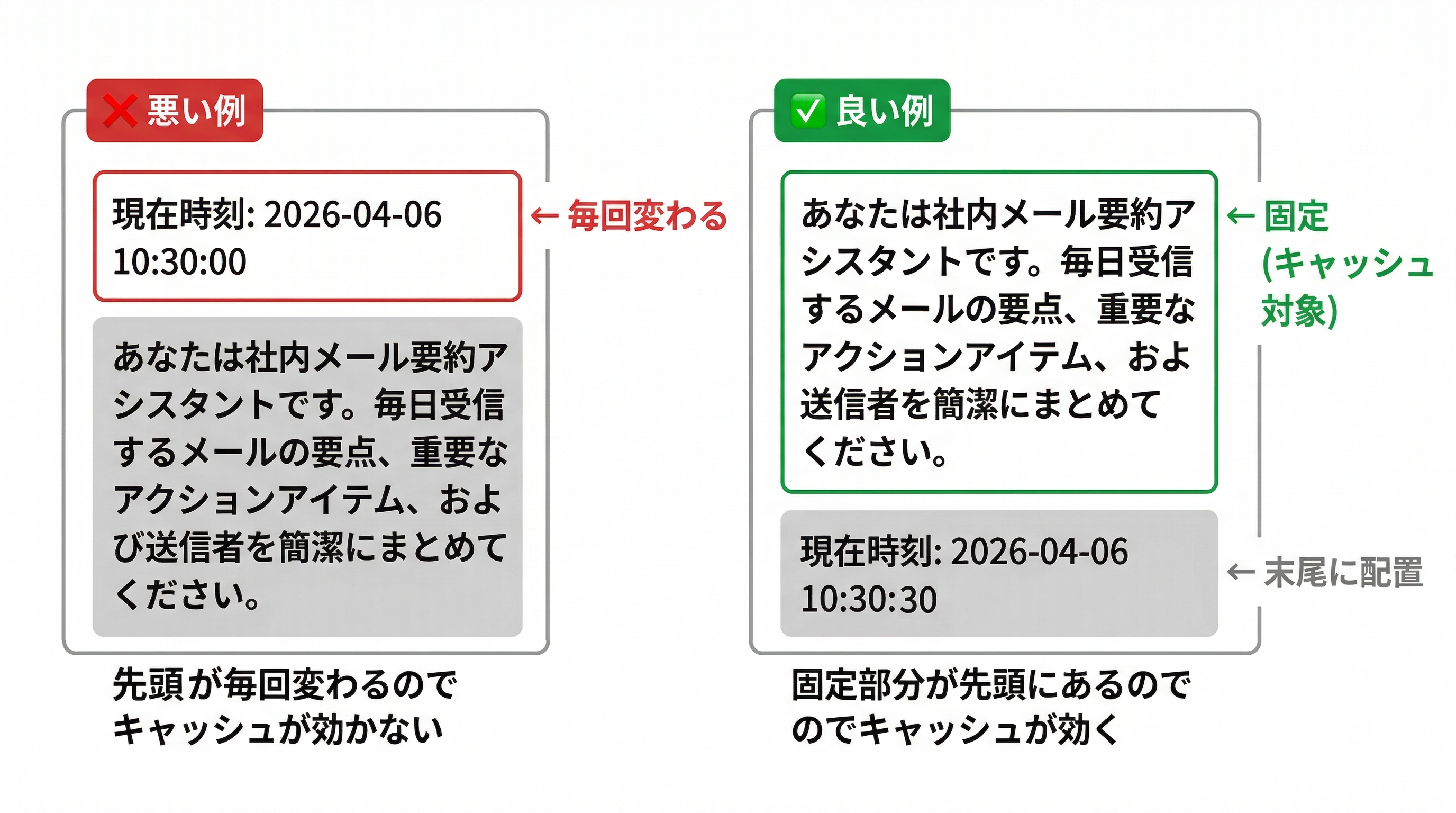
キャッシュは先頭からの完全一致で判定されるため、プロンプトの構成順序が重要です。
固定部分をプロンプトの先頭に集めることで、キャッシュ対象を最大化できます。
具体的な設計指針をまとめます。
| 配置 | 内容の例 |
|---|---|
| 前半(固定) | システムプロンプト、出力ルール、Few-shotの例、ツール定義、スキーマ定義 |
| 後半(可変) | ユーザー入力、タイムスタンプ、セッションID、その他動的コンテキスト |
たとえば、タイムスタンプをシステムプロンプトの先頭に入れてしまうと、毎回プレフィックスが変わりキャッシュが効きません。もちろん、文脈を保つために変動する値を先頭付近に配置しなければならないこともあるのでケースバイケースですが、キャッシュを意識するのであれば極力前半は静的な文章でまとめましょう。
実際にOpenAI APIを使って、キャッシュの動作を確認してみましょう。メール要約を行うシステムプロンプトを用意し、トークン使用量の cached_tokens を観察します。
今回は2つのパターンで検証しました。
| パターン | 特徴 |
|---|---|
| A. instructions で指示 | Responses APIの instructions にシステムプロンプトを渡す |
| B. Structured Output付き | Pydanticスキーマを text_format で指定 |
最もシンプルな方法です。Responses API の instructions パラメータにシステムプロンプトを、input にメール本文を渡します。
def main() -> None:
client: OpenAI = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
instructions: str = """\
あなたは社内メール要約アシスタントです。
以下のルールを厳守してください。
...(省略)...
"""
mail_body: str = """\
山田様
お疲れさまです。
4月10日の顧客向けデモに向けて、以下を今週中に整理したいです。
...(省略)...
"""
response = client.responses.create(
model="gpt-5.4-mini",
instructions=instructions,
input=mail_body,
)
Pydanticでスキーマを定義し、text_format で渡すパターンです。各フィールドに Field(…) で詳細な description を付けています。
なお、意図的に各 description を長めに記載しています
from pydantic import BaseModel, Field
class ActionItem(BaseModel):
assignee: str = Field(
...,
description="タスクの担当者名。メール本文中に明記されている担当者をそのまま抽出する。不明な場合は '未定' とする",
)
deadline: str = Field(
...,
description="タスクの期限。日付が明記されている場合は 'YYYY-MM-DD' 形式で抽出し、午前・午後などの指定があれば併記する。期限の記載がない場合は '期限なし' とする",
)
content: str = Field(
...,
description="タスクの具体的な内容。メール本文から依頼事項を簡潔に要約し、曖昧な表現は原文のニュアンスを保ったまま記載する",
)
class MailSummary(BaseModel):
three_line_summary: list[str] = Field(
...,
description="メール全体の要点を3行で簡潔にまとめたリスト。各行は1文で完結させ、依頼の背景・主な作業内容・期限やリスクの順で構成する",
)
key_points: list[str] = Field(
...,
description="メール内の重要ポイントを箇条書きで抽出したリスト。意思決定事項、制約条件、注意すべきルールなど、見落とすと問題になる情報を優先的に含める",
)
action_items: list[ActionItem] = Field(
...,
description="メールから抽出したアクションアイテムのリスト。担当者・期限・内容の組み合わせで構造化し、複数の依頼が含まれる場合はそれぞれ個別の要素として分離する",
)
notes: list[str] = Field(
...,
description="セキュリティ、法務、個人情報に関わる注意事項のリスト。顧客データの取り扱い制限、社外共有の可否、コンプライアンス上の懸念など、本文中に該当する記述があれば抽出する",
)
# Structured Output を指定して呼び出し
response = client.responses.parse(
model="gpt-5.4-mini",
instructions=instructions,
input=mail_body,
text_format=MailSummary,
)
各パターンを短い間隔で複数回実行し、キャッシュヒット時のトークン使用量を比較しました。
| パターン | input_tokens | cached_tokens |
|---|---|---|
| A. instructions | 1,545 | 1,280 |
| B. Structured Output付き | 3,059 | 2,816 |
このように、特にキャッシュの設定リクエストを送ることなく、簡単に実行することができました。
なお、全く同じ文言を送っても、input_tokensのすべてがキャッシュされるわけではない、ということもわかりました。
OpenAIのStructured Output(response_format や text_format で JSON Schema を指定する機能)を使う場合、スキーマ定義はプロンプトの先頭にプレフィックスとして追加されます。
Structured Outputはシステムに生成AIを組み込む上で重要な技術であり、これは実務上大きなメリットがあります。
メールからの情報抽出のようにスキーマが固定で入力だけが変わるユースケースはもちろん、システムプロンプトが動的に変わるケースでも、スキーマ部分のキャッシュは安定して効くこととなります。
プロンプトキャッシュの仕組みはベンダーごとに異なります。以下のテーブルに主要な違いをまとめました(OpenAI公式ドキュメント 、Anthropic公式ドキュメント 、Google AI公式ドキュメント )。
| 比較軸 | OpenAI | Claude | Gemini |
|---|---|---|---|
| 適用条件 | 自動(設定不要) | 明示設定が必要 | 自動(2.5以降) / 明示設定 |
| 最小トークン数 | 1,024 | 1,024〜4,096(モデルによる) | 1,024〜4,096(モデルによる) |
| キャッシュ保持期間 | 5〜10分(拡張: 最大24時間) | 5分 / 1時間 | 自動管理 / TTLで指定 |
| キャッシュ保存料金 | 無料 | 基本入力の1.25倍(5分) / 2倍(1時間) | 暗黙的: 無料 / 明示的: ストレージ費用あり |
| キャッシュ読み取り料金 | 基本入力の0.1〜0.25倍(75〜90%オフ) | 基本入力の0.1倍(90%オフ) | 基本入力の0.1倍(90%オフ) |
OpenAIはキャッシュの書き込みが無料で自動適用されるため、最も手軽に恩恵を受けられます。コスト削減に加えて、キャッシュヒット時にはレイテンシも最大80%短縮されます。Claudeは書き込みに追加コストがかかりますが、読み取りの割引率が高く、繰り返し同じプレフィックスを送るワークロードではコスト面で大きな効果があります。Geminiは暗黙的キャッシュ(自動)と明示的キャッシュ(TTL指定)の2種類があり、暗黙的キャッシュではヒットが保証されない点に注意しましょう。
プロンプトキャッシュが特に効果を発揮するのは、固定の指示で大量の入力を処理するパターンです。
当社のSES案件マッチングシステムでは、1日6,000件超のメールから案件情報を自動抽出しています。このシステムでは、Structured Outputを使って「単価」「開始日」「契約期間」など19種類29項目をメールから構造化して取り出します。
このようなシステムでは、以下の部分がリクエスト間で固定です。
変わるのはメール本文だけです。つまり、プロンプトの大部分をキャッシュ対象にすることができます。1日6,000件のメールを処理する場合、固定部分のトークンが毎回キャッシュから読み込まれることで、レイテンシとコストの両面で大きな効果が期待できます。
| ユースケース | 固定部分 | 可変部分 |
|---|---|---|
| カスタマーサポートの自動分類 | 分類ルール、カテゴリ定義、応答テンプレート | 問い合わせ内容 |
| ドキュメントレビュー | レビュー観点、チェックリスト、出力スキーマ | レビュー対象の文書 |
| コードレビュー | レビュールール、コーディング規約 | 対象のコード差分 |
| 議事録の要約 | 要約ルール、出力フォーマット | 会議の文字起こし |
| データ入力の自動化 | 入力ルール、バリデーション条件、スキーマ | 入力元データ |
いずれも「ルールは固定、入力だけが変わる」というパターンです。このパターンに当てはまるシステムを構築している場合、プロンプトの構成を見直すだけでキャッシュの恩恵を最大限に引き出せます。
プロンプトの構成順序を意識するだけで、レイテンシとコストの両面でパフォーマンスを改善できます。既存のシステムでも、プロンプトの構成を見直してみてはいかがでしょうか。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。



