
生成AI関連
Amazon Bedrock Knowledge Base × S3 VectorsでRAGを作って…
RAG(検索拡張生成)システムを構築したあと、「本当にこの検索結果は適切なのか?」「回答の品質をどう測ればいいのか?」という課題に直面したことはないでしょうか。
RAGの精度改善には、チャンキング戦略の変更やメタデータフィルタリングの導入など、さまざまなアプローチがあります。しかし、改善の効果を定量的に把握できなければ、何が効いて何が効かなかったのかが分かりません。
そこで注目したいのがAmazon Bedrock Evaluationsです。このサービスを使えば、LLM as a Judge(LLMを評価者として活用する手法)により、Knowledge Baseの検索・生成品質を自動で定量評価できます。
以前の記事ではKnowledge Baseの構築方法やメタデータの活用を紹介しましたが、今回はその次のステップとして「構築したRAGをどう評価し、改善サイクルを回すか」にフォーカスします。
Amazon Bedrock Evaluationsは、生成AIモデルやRAGシステムの性能を定量的に評価するマネージドサービスです。
主な特徴は以下の通りです。
| 特徴 | 内容 |
|---|---|
| 評価方式 | 自動評価(LLM as a Judge)と人力評価に対応 |
| RAG評価 | 自動評価(LLM as a Judge)のみ対応 |
| 評価対象 | Retrieval only(検索のみ)とRetrieval and response generation(検索+生成)の2種類 |
| 評価モデル | Amazon Nova、Claude などのBedrock上のモデルを評価者として使用 |
| 料金 | 評価時のモデル推論料金が発生。Knowledge Base方式では追加でKnowledge Bases利用料金も発生 |
ポイントは、評価機能そのものに個別の追加料金が設定されているわけではないという点です。課金されるのは評価モデル(Judge)が推論に使用するトークン分で、Bedrock Knowledge Base方式でRAG評価を行う場合は、これに加えてAmazon Bedrock Knowledge Basesの通常利用料金も発生します。
Bedrock EvaluationsでRAGを評価する方法は、大きく分けて2つあります。
Bedrock Evaluationsが検索と評価の両方を担当するアプローチです。評価ジョブを作成する際にKnowledge Baseを直接指定すると、Bedrock側が検索を実行し、その結果を自動で評価してくれます。
メリット:
ユーザーが自前で検索結果を用意し、Bedrock Evaluationsは評価のみを担当するアプローチです。
メリット:
今回は、より手軽に始められるBedrock Knowledge Base方式を使って実際に評価してみます。
RAG評価の流れは、以下の4ステップです。
本記事では、ステップ1のRAGシステム(Knowledge Base)はすでに構築済みであることを前提とし、ステップ2以降を解説します。Knowledge Baseの構築方法については、以下の過去記事をご参照ください。
評価を行うには、まずプロンプトデータセットを用意する必要があります。これは「RAGに対してどんな質問をし、どんな回答を期待するか」を定義したファイルです。
JSONL(JSON Lines)形式で作成します。各行が1つの評価ケースで、conversationTurns配列の中にプロンプトとリファレンス(期待回答)を記述します。Retrieval onlyの評価では、各ケースで指定できる会話ターンは1ターンのみです。
以下は、質問のみのケースとリファレンス付きのケースの例です。
{"conversationTurns":[{"prompt":{"content":[{"text":"Amazon Bedrockのガードレールとは何ですか?"}]}}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"Knowledge Baseのチャンキング戦略にはどのような種類がありますか?"}]},"referenceResponses":[{"content":[{"text":"デフォルトチャンキング、固定サイズチャンキング、階層的チャンキング、セマンティックチャンキング、チャンキングなしの5種類があります。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"S3 Vectorsのメリットは何ですか?"}]},"referenceResponses":[{"content":[{"text":"サーバーレスでベクトルストアを利用でき、別途ベクトルDBを構築・運用する必要がありません。"}]}]}]}
1行だと見づらいので、展開すると以下のような構造です。
{
"conversationTurns": [
{
"prompt": {
"content": [
{ "text": "Knowledge Baseのチャンキング戦略にはどのような種類がありますか?" }
]
},
"referenceResponses": [
{
"content": [
{ "text": "デフォルトチャンキング、固定サイズチャンキング、階層的チャンキング、セマンティックチャンキング、チャンキングなしの5種類があります。" }
]
}
]
}
]
}
| フィールド | 必須 | 説明 |
|---|---|---|
| conversationTurns[].prompt.content[].text | 必須 | RAGに投げる質問文 |
| conversationTurns[].referenceResponses[].content[].text | 任意 | 期待される回答(一部メトリクスで必要) |
注意点:
参考:Knowledge base evaluation prompt datasets – Amazon Bedrock
評価ジョブでは、プロンプトデータセットの読み込みと評価結果の書き出しにS3を使用します。モデル評価ジョブで指定するすべてのS3バケットに対して、以下のCORS設定が必要です。
S3コンソールで対象バケットを開き、「アクセス許可」タブ > 「Cross-Origin Resource Sharing (CORS)」セクションの「編集」から、以下のJSONを設定します。
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"GET",
"PUT",
"POST",
"DELETE"
],
"AllowedOrigins": [
"*"
],
"ExposeHeaders": [
"Access-Control-Allow-Origin"
]
}
]
この設定がないと、Bedrock Evaluationsがデータセットの読み書きに失敗するので忘れずに設定しましょう。
参考:Amazon S3 に CORS アクセス許可を設定する – Amazon Bedrock
Bedrock Evaluationsで利用できるメトリクスは、評価タイプによって異なります。Amazon Bedrockでは組み込みメトリクスに加えてカスタムメトリクスも定義できますが、ここではコンソールからすぐに使える組み込みメトリクスを中心に紹介します。
今回使用するRetrieval onlyでは、検索結果そのものの品質を評価します。利用できる組み込みメトリクスは以下の2種類です。
| メトリクス | 説明 | referenceResponses |
|---|---|---|
| Context Relevance | 検索結果が質問に対してどれだけ関連性があるか(Precision的な指標) | 不要 |
| Context Coverage | 期待回答に必要な情報が検索結果にどれだけ含まれているか(Recall的な指標) | 必要 |
Context RelevanceはreferenceResponsesなしで評価できるため、まずはここから始めるのがおすすめです。LLMが「質問と検索結果の組み合わせ」を見て関連性を判定してくれます。
一方、Context Coverageは「正解情報がどれだけカバーされているか」を測る指標なので、比較対象となるreferenceResponsesが必須です(公式ドキュメントに明記)。
参考:メトリクスを使用して RAG システムのパフォーマンスを把握する – Amazon Bedrock
参考として、Retrieval and response generationで使用できる組み込みメトリクスも紹介します。こちらは検索結果をもとにLLMが生成した回答の品質を評価するもので、Retrieval onlyで検索精度を確認した後のステップとして活用できます。
| メトリクス | 説明 |
|---|---|
| Correctness | 回答が期待回答と比べて正確か |
| Completeness | 回答が期待回答の内容を網羅しているか |
| Helpfulness | 回答がユーザーの質問に対してどれだけ有用か |
| LogicalCoherence | 回答が論理的に一貫しているか |
| Faithfulness | 回答が検索結果(コンテキスト)に忠実か(ハルシネーション検出) |
| CitationPrecision | 引用が回答内容に対して適切か(引用の適合率) |
| CitationCoverage | 回答の主張が引用でどれだけカバーされているか(引用の網羅率) |
| Harmfulness | 回答に有害な内容が含まれていないか |
| Stereotyping | 回答にステレオタイプが含まれていないか |
| Refusal | 回答すべきでない質問を適切に拒否しているか |
メトリクスの数は多いですが、最初からすべてを使う必要はありません。自社のユースケースで重視したいポイントを絞り、数件のメトリクスから始めて段階的に追加していくのがおすすめです。より細かい観点で評価したい場合は、カスタムメトリクスを定義して独自の評価基準を組み込むこともできます。
参考:メトリクスを使用して RAG システムのパフォーマンスを把握する – Amazon Bedrock
AWS マネジメントコンソールからRetrieval onlyの評価ジョブを作成する手順を解説します。
Amazon Bedrock > 評価(Evaluations) > RAGタブを開き、作成(Create)ボタンをクリックすると、評価ジョブの作成画面が表示されます。
まず「Evaluation details」セクションで、以下を設定します。
「Inference source」セクションでは、評価対象のRAGソースと評価タイプを設定します。
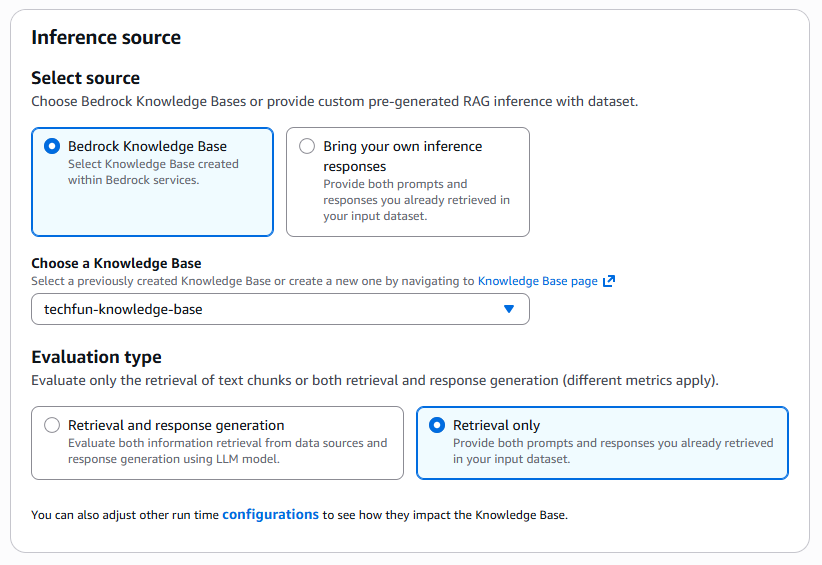
評価対象のソースを選択します。
| ソース | 内容 |
|---|---|
| Bedrock Knowledge Base | Bedrock上に作成済みのKnowledge Baseを選択して評価 |
| Bring your own inference responses | 外部RAGシステムの検索結果・回答をデータセットとして持ち込んで評価 |
今回はBedrock Knowledge Baseを選択します。
評価対象のKnowledge Baseをドロップダウンから選択します。作成済みのKnowledge Baseが一覧に表示されます。
| 評価タイプ | 内容 |
|---|---|
| Retrieval and response generation | 検索+LLMによる回答生成まで含めて評価 |
| Retrieval only | 検索結果のみを評価(検索精度にフォーカス) |
今回はRetrieval onlyを選択します。
まずは検索精度を確認し、問題がなければRetrieval and response generationに進むのが効率的です。検索精度が低いままRetrieval and response generationを評価しても、根本的な問題の切り分けが難しくなります。
なお、Retrieval and response generationを選択した場合は、Response generator model(回答生成に使うモデル)の選択項目が追加で表示されます。
前述の評価メトリクスの中から、今回の評価で使用するものを選択します。今回はRetrieval onlyなので、Context RelevanceとContext Coverageが選択対象です。
すべて設定したら、作成(Create)ボタンで評価ジョブを開始します。
評価ジョブが完了すると、AWSコンソール上でレポートを確認できます。
以下は、Retrieval onlyで5件のプロンプトを評価した結果の例です。
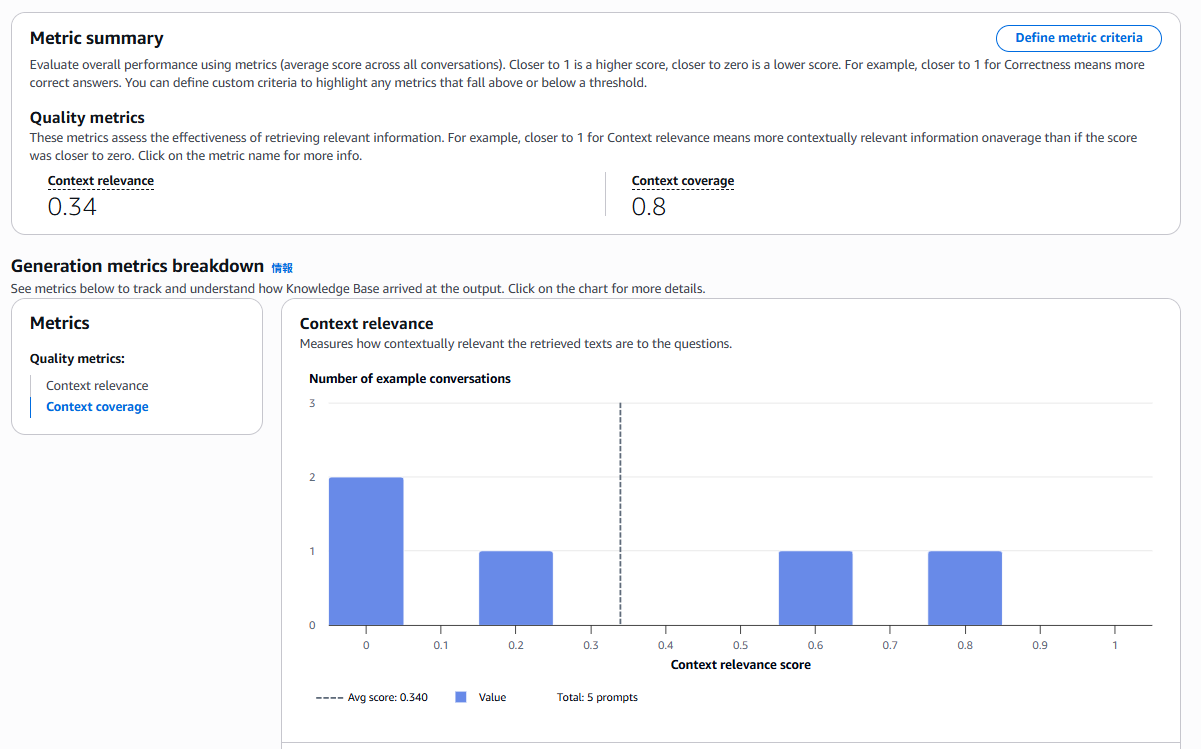
画面上部のMetric summaryには、各メトリクスの平均スコアが表示されます。スコアは0〜1の範囲で、1に近いほど高品質です。この例では、Context Relevanceが0.34、Context Coverageが0.8という結果になりました。
画面下部のGeneration metrics breakdownでは、メトリクスごとのスコア分布をヒストグラムで確認できます。どのプロンプトがどの程度のスコアだったかを視覚的に把握でき、スコアが低い質問を特定して改善につなげることができます。
各質問ごとに、以下の情報を確認できます。
判定理由が記載されている点が非常に便利です。なぜそのスコアになったのかをLLMが説明してくれるため、改善のヒントを得やすくなっています。
複数の評価ジョブを比較する機能もあります。たとえば、チャンキング戦略を変更する前後で評価ジョブを実行し、スコアの変化を確認するといった使い方ができます。
RAGシステムの改善でありがちなのが、「パラメータを変更してみたが、良くなったのか悪くなったのか分からない」という状況です。感覚的な判断に頼っていると、改善のつもりが実は性能ダウンしていた、ということも起こり得ます。
そこで重要になるのが、評価指標を定量的に示し、変更による向上・低下を目に見える形で把握することです。ソフトウェア開発におけるテスト駆動開発(TDD)のように、まず評価基準を定め、改善のたびに評価を実行し、数値で効果を確認する——このアプローチは「評価駆動開発(Evaluation-Driven Development)」と呼ばれています。
RAGの評価指標については、Precision@KやRecall@K、Faithfulness、Answer Relevancyなど、検索・生成それぞれの観点で様々な指標が提案されています。詳しくは以下の過去記事で整理していますので、あわせてご参照ください。
Bedrock Evaluationsは、この評価駆動開発を実践するための強力なツールです。改善施策の前後で評価ジョブを実行し、ジョブ間比較機能でスコアの変化を確認することで、「この変更でContext Relevanceが0.34→0.65に向上した」「Faithfulnessが下がったのでロールバックしよう」といった判断がデータに基づいてできるようになります。
最初から完璧なデータセットやメトリクスを揃える必要はありません。少数のプロンプトから始めて、実際のユーザーからの質問やエッジケースを随時追加しながら、「評価 → 改善 → 再評価」のサイクルを回していくことが大切です。
ここで注意したいのは、LLM as a Judgeは便利ですが、人手評価を完全に置き換えるものではないという点です。評価結果は、選択したJudgeモデル、メトリクスの定義、プロンプトの書き方に影響を受けます。そのため、微妙なニュアンスの妥当性や業務要件への適合性まで、常に正しく判定できるとは限りません。
特に、公開前の重要なユースケースや、スコアが低かったケース、ユーザー影響の大きい改善施策については、LLM as a Judgeによる自動評価と人手によるサンプリング確認を併用するのが現実的です。LLM as a Judgeは「すべてを自動で正しく判定する仕組み」というより、改善の方向性を素早く把握し、問題のあるケースを効率よく見つけるための仕組みとして活用するのが適しています。
Amazon Bedrock Evaluationsを使ったRAGの評価について解説しました。要点を振り返ります。
RAGの「なんとなく良さそう」を「定量的に良い」に変えるための第一歩として、ぜひBedrock Evaluationsを試してみてください。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。



