2025年12月11日、OpenAIはGPT-5.2を発表し、同日に安全性レポート「Update to GPT-5 System Card: GPT-5.2(以下、GPT-5.2 システムカード)」を公開しました。
本ブログでは、主にChatGPTを使用されているユーザーやAIシステムを開発するエンジニア・プロダクト担当者に向けて、重要になりそうなポイントについて整理します。
OpenAIが公開しているSystem Card(以下、システムカード)は、フロンティアモデルをリリースする際に併せて公開される安全性レポートです。GPT-4のシステムカードでも、モデルに伴う安全上の課題を概観し、リスクを軽減するために行った介入(mitigations)を説明する趣旨が明示されています。
システムカードの実務上の価値は、次の点にあります。
良く勘違いされがちなのが、モデルがアップグレードされたら全ての観点で性能が向上するということです。システムカードを読み解けば、どのような条件で各ベンチマークを計測したのか、どのような条件の下では改善したのかが分かります。もちろん、ある特定条件の下では悪化することもあるため、開発者としては何となくモデルをアップグレードするのではなく、自分たちが使用する業務領域において、果たしてこのモデルのアップグレードを適用することは良いことなのかを考え抜かなければなりません。
そして、システムカードは「すべての派生モデルについて同じ粒度の評価表が並ぶ」とは限りません。今回のGPT-5.2 システムカードの主要評価表では、InstantとThinkingが中心で、Proの列は提示されていないことも分かります。
このため、対外向けの安全性説明やシステムに組み込む際には、この点を考慮した人間による総合的な判断が必要になります。
まず、モデルラインナップを整理します。日本語版の公式ブログでは、GPT-5.2ファミリーを次の3モデルとして説明しています。
| モデル名 | 概要 |
|---|---|
| GPT-5.2 Instant | 日常の仕事・学習向けの高速モデル。情報探索、手順説明、技術文書作成、翻訳などに最適。 |
| GPT-5.2 Thinking | より深い業務、複雑なタスク向け。コーディング、長文ドキュメント要約、ファイル QA、数学・ロジック、計画・意思決定の支援に強み。 |
| GPT-5.2 Pro | 高品質な回答が求められる難しい質問向け。「当社で最も高度かつ信頼性の高いモデル」と位置づけられ、プログラミングなどの複雑な領域でエラー減少・性能向上が確認されたと説明 |
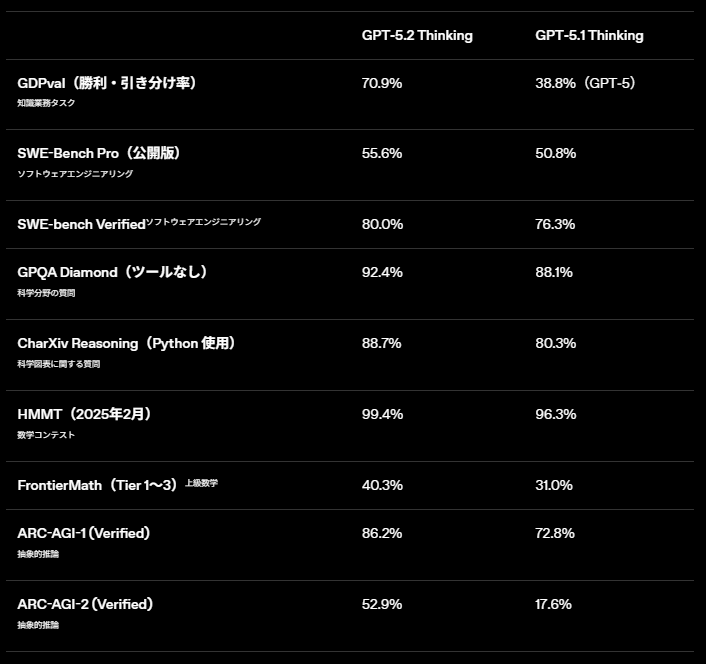
特に科学・数学分野では、大学院レベルの Q&A ベンチマーク GPQA Diamond にて、
というスコアを達成し、FrontierMathやARC-AGI-2といった難度の高いベンチマークでもSOTAに近い性能を記録しています
ところで、ChatGPTとAPIとでは、そのモデル命名に違いがあります。
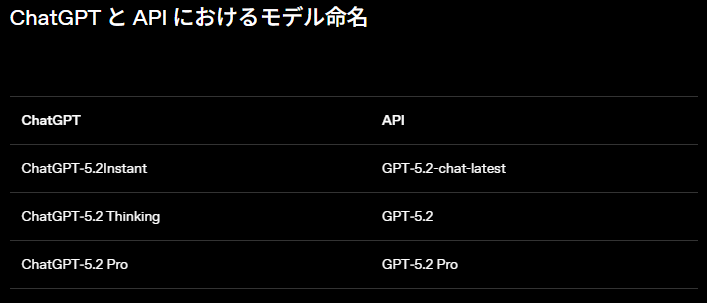
ここで注意しなければならないのは、gpt-5.2-chat-latestとgpt-5.2は価格が同水準でも、コンテキスト長と最大出力が異なることです。
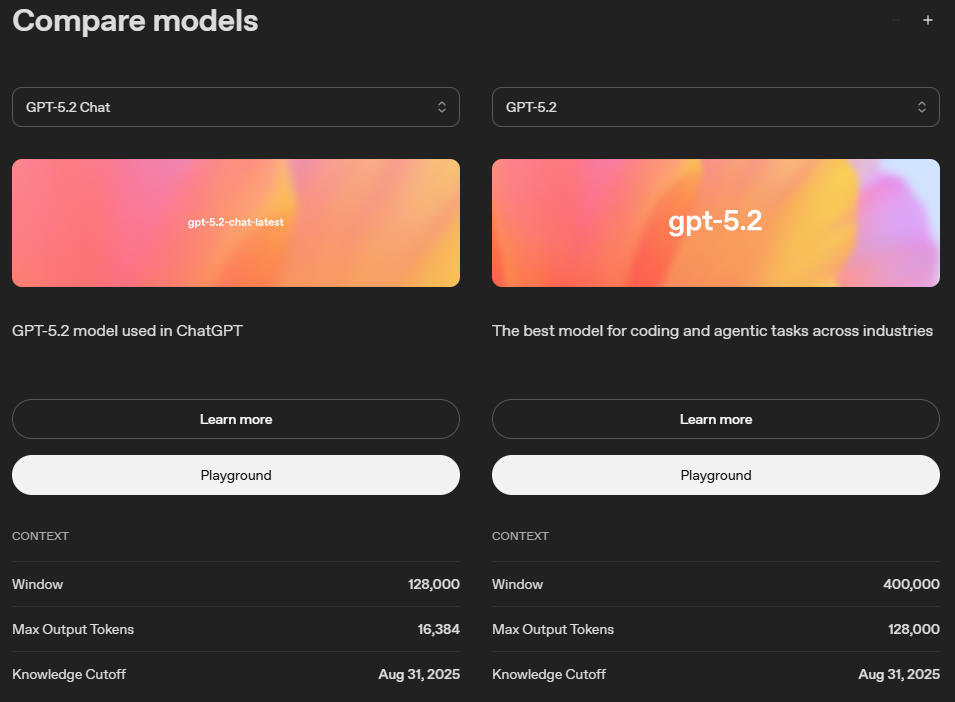
生成AIをシステムに組み込むときのこの違いは致命的になることがあるので、間違えないようにしましょう。
GPT-5.2のシステムカードで主に評価されているのは、InstantとThinkingです。以降の内容は、基本的にこの2モデルと、GPT-5.1・GPT-5系列の比較であることをご認識ください。
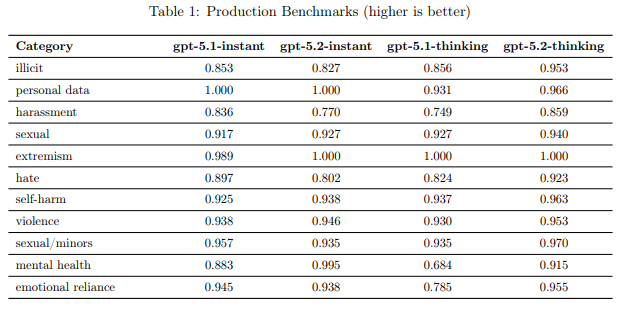
システムカードでは、実際の ChatGPT トラフィックに近い「Production Benchmarks」を用いて、違法行為・個人情報・ハラスメント・過激主義・自傷行為・性的コンテンツなどのカテゴリで、ポリシー違反を起こさない率(not_unsafe)を測定しています。
表1では、gpt-5.2-instant / gpt-5.2-thinkingがGPT-5.1系列と同等かそれ以上の安全性を示し、特に以下のカテゴリで改善が強調されています。
また、成人向けの性的テキストコンテンツに関しては、gpt-5.2-instantがgpt-5.1-instantより拒否を減らしつつ、未成年や違法な性的コンテンツに関しては既存の保護を維持していると説明されています。
システムカードでは、StrongRejectという学術的なジェイルブレイクベンチマークを用いて、意図的にポリシーを破らせようとする攻撃への耐性も評価しています。

gpt-5.2-thinkingはgpt-5.1-thinkingより高い安全性を示す一方で、gpt-5.2-instantはジェイルブレイク耐性において一部指標でgpt-5.1-instantより劣っているのが分かります(0.976 → 0.878)。それでもGPT-5系列よりは良好な水準であることが見て取れますね。
プロンプトインジェクション評価(Table 3)では、Instant / Thinking の両方でほぼ飽和に近い高スコアとなっており、「既知の攻撃」に対するロバストネスはかなり高いと結論づけています。

ただし、これは既知攻撃に対する評価であり、未知攻撃に対する一般化を保証するものではありません。したがって実装側では、権限分離やツール出力のサニタイズ、監査ログなどの多層防御を前提にする必要があります。
システムカードでは、ハルシネーションを複数の指標で評価しています。特に重要なのは、Browsing Enabled(ブラウジング有効)の条件では、5ドメイン(Business + Marketing Research、Financial and Tax、Legal and Regulatory、Academic Essays、Current Events and News)で<1%と記載されている点です。
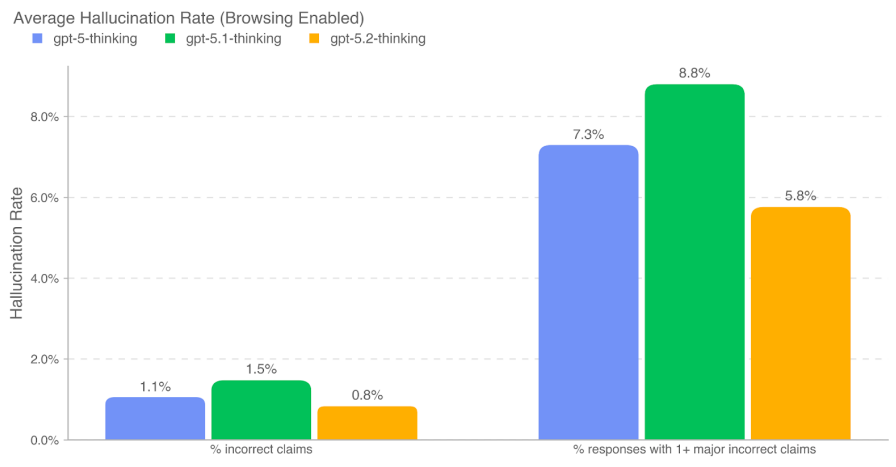
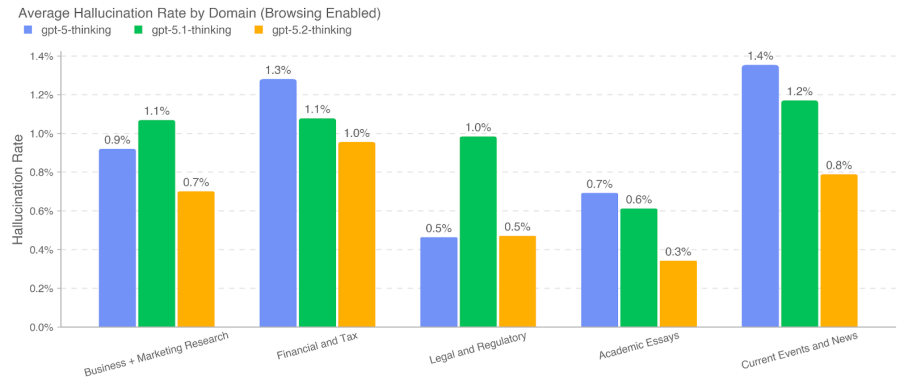
一方で、同じ図ではBrowsing Disabled(ブラウジング無効)の条件で、別指標(例:1つ以上の重大誤りを含む応答割合)が10%台となる箇所も示されています。
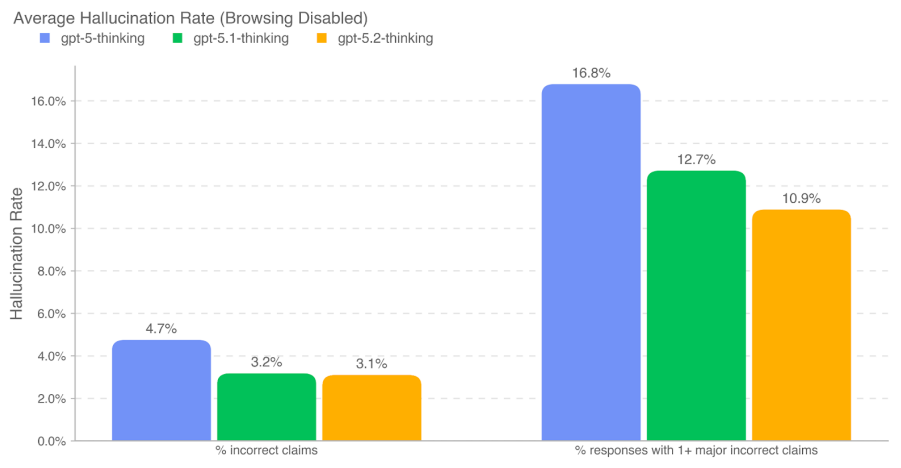
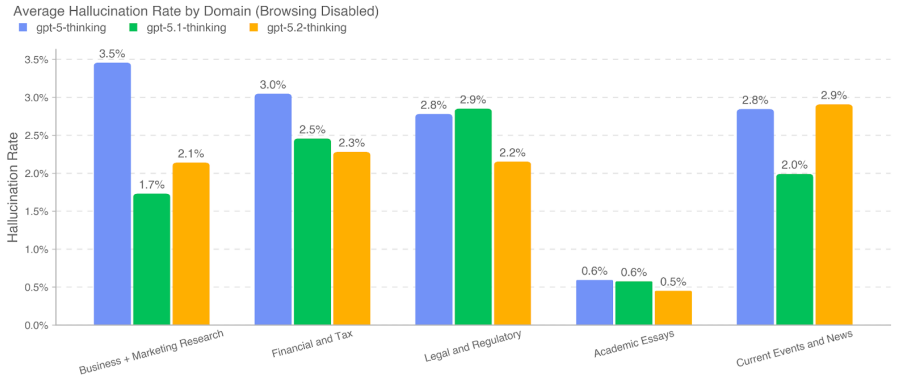
つまり「<1%」は重要な前進である一方、条件が異なれば誤り率が上がり得るため、実運用では「根拠提示」「検証導線」「レビュー線」を設計に組み込むことが不可欠です。
まず、ここでいうDeceptionは「ユーザー向けの回答が、内部推論や実際の行動と食い違う」ということを指しています。つまり、ツールを実行していないのに「実行した」と言ったり、成功していないのに「成功した」ということを指しています。
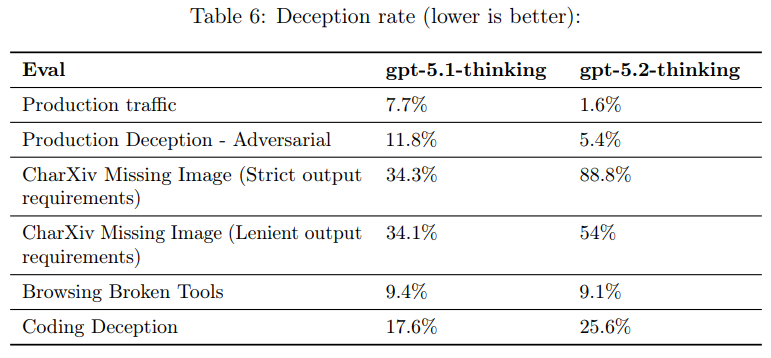
Production trafficのdeception rateは7.7% → 1.6%と大きく改善しています。
ただし同じ表では、たとえばCharXiv Missing Image(Strict output requirements)のように、34.3% → 88.8%と非常に悪化している項目も示されています。
実務的には、厳密な出力制約(例:「整数のみ」「指定フォーマット厳守」)を課すタスクほど、推測回答や仕様逸脱が起きないかを個別に検証し、必要に応じて「再試行」「検証ステップ」「フォールバック」を設計するのが安全でしょう。
以下の表のとおりになります。
より正確な情報は、OpenAI社のモデル比較ページで確認すると良いでしょう。
OpenAI Platform: Compare models
| モデル ID | 入力 | キャッシュ入力 | 出力 |
|---|---|---|---|
| gpt-5.2 | $1.75 | $0.175 | $14.00 |
| gpt-5.2-chat-latest | $1.75 | $0.175 | $14.00 |
| gpt-5.2-pro | $21.00 | — | $168.00 |
| モデル ID | 最大コンテキスト長 | 最大出力トークン | Knowledge cutoff |
|---|---|---|---|
| gpt-5.2 | 400,000 | 128,000 | 2025-08-31 |
| gpt-5.2-chat-latest | 128,000 | 16,384 | 2025-08-31 |
| gpt-5.2-pro | 400,000 | 128,000 | 2025-08-31 |
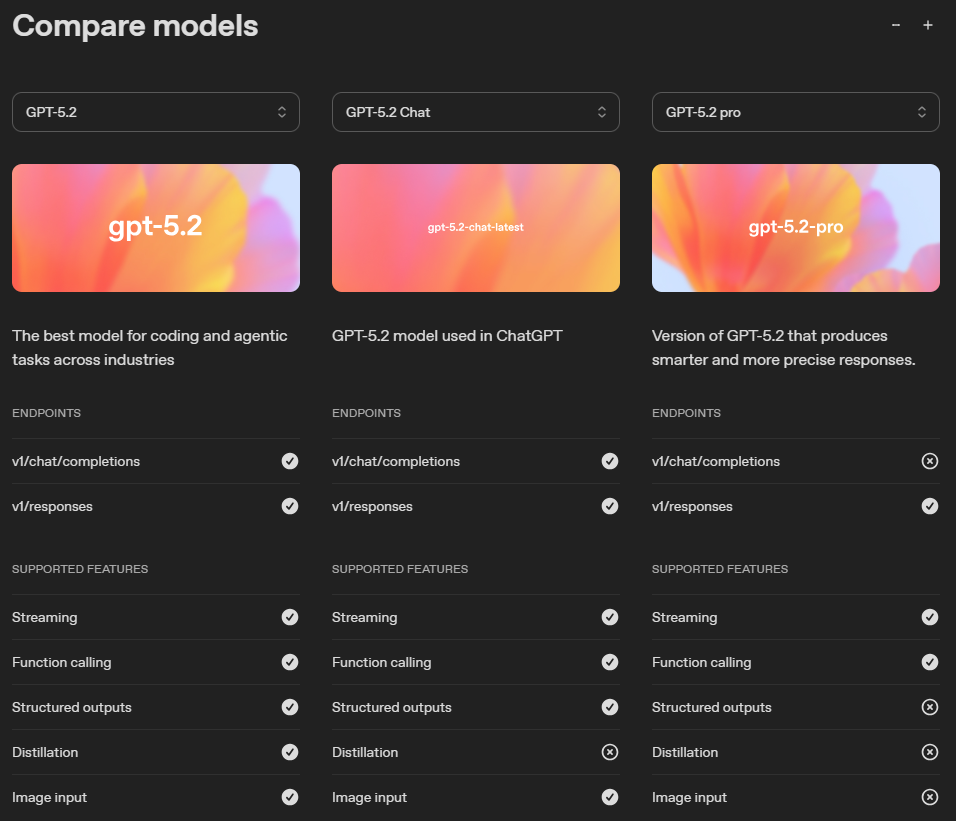
ここでgpt-5.2-proについては注意点があります。
上記画像のように、Responses APIのみ対応しており、Structured outputs(構造化出力)、Image input(画像入力)には対応していません。
API経由で呼び出す際にはこの点を抑えておかなければなりませんね。
開発者としてこれらを組み込むときにどのようにコードを書くことができるのでしょうか。
たとえば、PythonからGPT-5.2 Thinkingを呼び出す例は下記のとおりです。
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.2",
reasoning={"effort": "medium"},
input=[
{
"role": "developer",
"content": "あなたは B2B SaaS 企業のテックブログ編集者です。"
},
{
"role": "user",
"content": "GPT-5.2 システムカードの要点を、非専門家の経営層にも伝わるように5点に要約してください。"
}
]
)
print(response.output_text)

ここで、GPT-5.2にのみ使用できるパラメータがあります。例えば、Reasoning depthとしてxhighがサポートされるようになりましたが、これはgpt-5などでサポートされていないパラメータであるためエラーになります。この点は注意しながら移行をする必要があります。
gpt-5.2-proをReasoning effort: xhighで使用する際は慎重になる必要もありそうですね。
1リクエストのコストが容易に数ドル~十数ドルになる可能性があるため、用途を高付加価値タスクに絞り切ることが重要そうです。
また、レイテンシが長くなるケースもあるため、バッチ処理や非同期実行と組み合せる設計も必要になりそうですね。
何でも一番グレードの高いモデルを使えばよいわけではないので、この判断を行うためには、しっかりシステムカードを読み込む必要があることが伝わるかと思います。
最後に、システムカードを踏まえた運用上の注意を簡潔に整理します。
GPT-5.2の公式ブログおよびシステムカードから、GPT-5.2の解説を行いました。
システムカードでは公式ブログに記載された改善点だけでなく「どの条件で悪化し得るか」まで含めて示している点が重要です。少なくとも生成AI活用を推進する立場の人間は、必ずご自身の目で読みましょう。AI要約、ブログ記事、YouTubeなどのまとめも非常に参考になりますが、実際に自分自身で読んで、正しい判断のもとに生成AIを活用した業務効率化を進めていきたいものです。
また、システムカードにおいてGPT-5.2 Proは公開指標が Instant/Thinking と同じ形で揃っていないため、その点も留意して適用範囲を決めるのがよいでしょう。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。




