本講座では、主に現場で多く扱われる、Java11までの機能を使って学習をしていますが、Java12以降にも便利な機能群が導入されてきています。
そのため、本章ではJava12からJava17までに導入された新機能の内、特に役立ちそうな機能に絞って基本的な内容や使い方を紹介していきます。
Java15で追加されたテキストブロックについて紹介します。
まず、文字列の宣言について復習しましょう。
public class MyString1 {
public static void main(String[] args) {
// テキストブロックを使用しない複数行の文字列を宣言
String str = "りんご\r\n"
+ "もも\r\n"
+ "みかん";
System.out.println(str);
}
}複数行にまたがる文字列を宣言する場合、文字列と次の行の文字列との間に改行文字(\r\n)を付与する必要があります。
また、1行単位で文字列を宣言しながら書いていくには、+演算子を用いて文字列と文字列を連結します。
りんご
もも
みかんテキストブロックを使用すると、改行文字や文字列連結の演算子を使用せず、複数行の文字列をJavaのコード内に直接書けるようになります。
以下のように、"""を囲むようにして複数行の文字列を宣言します。
public class MyString2 {
public static void main(String[] args) {
// テキストブロックを使用した複数行の文字列を宣言
String str = """
りんご
もも
みかん""";
System.out.println(str);
}
}りんご
もも
みかんテキストブロックの中に入力した空白文字は、そのまま空白文字として出力されます。
以下のサンプルは、インデント付きのHTML文字列をテキストブロックを用いて書いたコードになります。
public class MyString3 {
public static void main(String[] args) {
// テキストブロックを使用した複数行の文字列を宣言
String str = """
<html>
<head>
<title>こんにちは</title>
</head>
<body>
<h1>こんにちは!!</h1>
</body>
</html>""";
System.out.println(str);
}
}<html>
<head>
<title>こんにちは</title>
</head>
<body>
<h1>こんにちは!!</h1>
</body>
</html>このテキストブロックをうまく活用すると、HTMLやSQLをはじめとする複数行のテキスト文字列で定義している外部テンプレートファイルを別途用意せずに、Javaのコード内に直接書くことができるので、プログラムのファイル数を減らす効果も得られます。
※HTMLやSQLについては、別講座にて学習します。現状はそのようなものがあり、テキストブロックを使うと便利になるということを認識できれば問題ありません
テキストブロックについての説明は、以上です。
Java14で追加された、switch~caseの複数ラベルについて紹介します。
まずは、switch文の使い方を復習しましょう。
public class SwitchCase1 {
public static void main(String[] args) {
int number = 3;
switch (number) {
case 1:
case 2:
System.out.println("番号 = 1, 2");
break;
case 3:
case 4:
case 5:
System.out.println("番号 = 3, 4, 5");
break;
default:
System.out.println("番号 = " + number);
break;
}
}
}switchに指定した変数(number)に対応するcaseには、常に1個の値しか指定できませんでした。
そのため、一度に複数のcase条件値で同じ処理を実行したい場合、その条件の個数分だけcaseを書かないといけませんでした。
switchの複数ラベルの機能を使用すると、以下のようにカンマで区切ることによって、1個のcaseの中にまとめることができ、コードの行数を減らすことができます。
public class SwitchCase2 {
public static void main(String[] args) {
int number = 3;
switch (number) {
case 1, 2:
System.out.println("番号 = 1, 2");
break;
case 3, 4, 5:
System.out.println("番号 = 3, 4, 5");
break;
default:
System.out.println("番号 = " + number);
break;
}
}
}switch~caseの複数ラベルについての説明は、以上です。
Java16で追加されたレコードクラスについて紹介します。
まずは、JavaBeansの使い方を復習しましょう。
最初に、JavaBeansのクラスを作成します。
public class SampleBean1 {
// 名前
private String name;
// フリガナ
private String furigana;
// 年齢
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getFurigana() {
return furigana;
}
public void setFurigana(String furigana) {
this.furigana = furigana;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}次に、実行用のクラスを作成します。
public class ShowSampleBean1 {
public static void main(String[] args) {
SampleBean1 bean1 = new SampleBean1();
bean1.setName("佐藤");
bean1.setFurigana("サトウ");
bean1.setAge(20);
SampleBean1 bean2 = new SampleBean1();
bean2.setName("鈴木");
bean2.setFurigana("スズキ");
bean2.setAge(30);
System.out.println("最初に追加された名前は、" + bean1.getName() + "さんです。");
System.out.println("2番目に追加された名前は、" + bean2.getName() + "さんです。");
}
}最初に追加された名前は、佐藤さんです。
2番目に追加された名前は、鈴木さんです。従来のJavaBeansでは、フィールドの定義に加え、「getter」と「setter」のアクセスメソッドのコードを、そのフィールドの数分だけ書かないといけない課題がありました。
それを解決する新機能として登場したのが、レコードクラス(Record)です。
このレコードクラスを使うと、JavaBeansよりもデータの構造を簡単に定義できるようになりました。
/**
* SampleBean2レコードクラス。
*
* @param name 名前。
* @param furigana フリガナ。
* @param age 年齢。
*/
public record SampleBean2(String name, String furigana, int age) {
}レコードクラスとして定義するには、下記の通りとなります。
JavaBeansの書き方と比較すると、private修飾子で定義するフィールドやそれらにアクセスする「getter」「setter」のメソッドを書かなくて済むため、非常に簡潔になっています。
定義するフィールド数が多くなればなるほど、コーディング量が減少し、恩恵を受けられる形になります。
このレコードクラスとして書かれたSampleBean2をコンパイルすると、以下に示すコードのクラスファイルが生成されます。
public final class SampleBean2 extends java.lang.Record {
private final String name;
private final String furigana;
private final int age;
public String SampleBean2(String name, String furigana, int age) {
this.name = name;
this.furigana = furigana;
this.age = age;
}
public String name() {
return this.name;
}
public String furigana() {
return this.furigana;
}
public int age() {
return this.age;
}
@Override
public int hashCode() {
~ (省略) ~
}
@Override
public boolean equals() {
~ (省略) ~
}
@Override
public String toString() {
return "SampleBean2[name=" + this.name + ", furigana=" + this.furigana + ", age=" + this.age + "]";
}
}上記のコードから見たレコードクラスの特徴は、以下の通りになります。
それでは、レコードクラスとして作成したSampleBean2の使い方を見てみましょう。
public class ShowSampleBean2 {
public static void main(String[] args) {
SampleBean2 bean1 = new SampleBean2("佐藤", "サトウ", 20);
SampleBean2 bean2 = new SampleBean2("鈴木", "スズキ", 30);
System.out.println("最初に追加された名前は、" + bean1.name() + "さんです。");
System.out.println(bean1);
System.out.println("2番目に追加された名前は、" + bean2.name() + "さんです。");
System.out.println(bean2);
}
}最初に追加された名前は、佐藤さんです。
SampleBean2[name=佐藤, furigana=サトウ, age=20]
2番目に追加された名前は、鈴木さんです。
SampleBean2[name=鈴木, furigana=スズキ, age=30]レコードクラスについての説明は、以上です。
JavaBeansとレコードクラスでは、クラス内に定義されたフィールドにアクセスするメソッドの実装方法が異なるため、
まったく互換性がありません。
そのため、JavaBeansのルールに準拠するアクセス方法しかサポートされていないJavaの標準機能やサードパーティー製ライブラリでは、
レコードクラスのオブジェクトの受け渡しができないので注意が必要です。
Java16で追加されたパターンマッチングについて紹介します。
パターンマッチングを学ぶ前に、関連する技術として、instanceof演算子を学習します。
instanceof演算子を使うと、対象の変数の実態が、どのクラスやインターフェースの型なのかを判定することができます。
構文は、以下のようになります。
<変数名> instanceof <クラスの型>戻り値はbooleanになっており、変数がinstanceofの右辺で指定したクラス型のインスタンスである場合に、trueを返却します。
実際に、instanceof演算子の使い方を確認していきましょう。
public class InstanceofSample1 {
public static void main(String[] args) {
Object obj = "文字列";
if (obj instanceof String) {
System.out.println("これはStringクラスです。");
}
if (obj instanceof Integer) {
System.out.println("これはIntegerクラスです。");
}
}
}これはStringクラスです。上記のサンプルでは、Object型の変数objに対して、文字列を代入しています。
その後、instanceof演算子を用いて、StringとIntegerを右辺に指定した条件分岐にて判定し、
結果として、String型が正しいため、上記の実行結果が表示されています。
では、instanceof演算子を用いてインスタンスの型を判定し、その値を表示してみましょう。
public class InstanceofSample2 {
public static void main(String[] args) {
Object obj = "文字列";
if (obj instanceof String) {
String str = (String) obj;
System.out.println("これは" + str + "です。");
}
if (obj instanceof Integer) {
Integer i = (Integer) obj;
System.out.println("これは" + i + "です。");
}
}
}これは文字列です。instanceof演算子を用いてインスタンスの型を判定した場合でも、
その値を変数に代入する場合には、以下のようにキャストを使用して変換する必要があります。
String str = (String) obj;このように、インスタンスの型を判定する正しい条件分岐を書いているにもかかわらず、
常にキャストを用いないといけない点が、このinstanceof演算子の使いにくさの課題になっていました。
これに対し、新機能のパターンマッチングを用いることにより、
コレクションのジェネリクス(総称型)と同じように、キャストを使わずに値を取得することができるようになりました。
public class InstanceofSample3 {
public static void main(String[] args) {
Object obj = "文字列";
if (obj instanceof String str) {
System.out.println("これは" + str + "です。");
}
if (obj instanceof Integer i) {
System.out.println("これは" + i + "です。");
}
}
}これは文字列です。パターンマッチングは、以下の形式で条件分岐を書いていきます。
if (<変数名> instanceof <クラスの型> <変数名>) {
<クラスの型>が一致すると、このブロック内で<変数名>を使用できるようになる。
}「<変数名> instanceof <クラスの型>」の末尾に<変数名>を追加します。
この条件式がtrueの場合、つまり、変数名の型がinstanceofで指定しているクラスの型と一致している場合、
条件式に追加した<変数名>を、正として評価されたブロック内で使用することができ、キャストを使用した変数の代入式を省略することができます。
パターンマッチングについての説明は、以上です。
Javaにおけるプログラムの開発において、何回も発生する悩ましい問題がNullPointerExceptionです。
ここでは、Java14で改善されたNullPointerExceptionのエラーメッセージについて紹介していきます。
Javaで扱うデータの種類には、基本データ型(プリミティブ型)と参照型があります。
NullPointerExceptionが発生するのは後者の参照型になります。
Javaでは、参照型の変数に、「何もない」状態を意味する特殊な値「null」を代入することができます。
この「null」にアクセスすると、NullPointerExceptionと呼ばれる例外が発生し、プログラムが異常終了します。
それでは、以下のサンプルコードを用いて、Java14より前のバージョン(Java11)と
Java14以降のバージョン(Java17)で比較しながら、NullPointerExceptionの発生状態を確認してみましょう。
public class NPEBean {
// 名前
private String name;
// フリガナ
private String furigana;
// 年齢
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getFurigana() {
return furigana;
}
public void setFurigana(String furigana) {
this.furigana = furigana;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}public class NPEStacktrace {
public static void main(String[] args) {
NPEBean bean = new NPEBean();
bean.setName("佐藤");
bean.setAge(19);
if (bean.getFurigana().equals("")) {
System.out.print("フリガナが空です。");
}
}
}Java11でサンプルコードを実行すると、以下の結果になります。
Exception in thread "main" java.lang.NullPointerException
at NPEStacktrace.main(NPEStacktrace.java:7)NullPointerExceptionが発生した場所を特定する情報として、以下の情報がスタックトレースに出力されていることを確認することができます。
ただ、これだけでは、発生した行の具体的にどこなのか、ソースコードを見るだけでは、まだ特定に至りません。
そこで、プログラムをデバッグモードで実行して、Eclipseのデバッグ機能を利用することにより、NullPointerExceptionの発生原因につながった箇所を確認することができます。
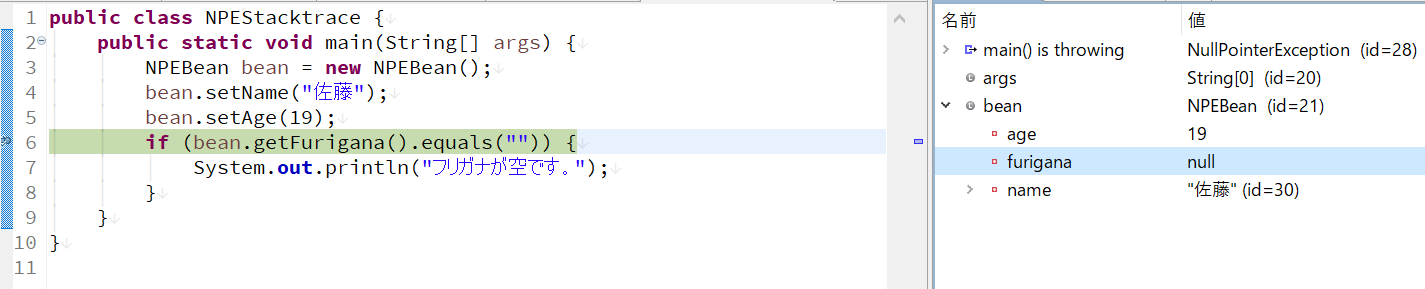
次に、Java17を使ってサンプルコードを実行すると、以下の結果になります。
Exception in thread "main" java.lang.NullPointerException: Cannot invoke "String.equals(Object)" because the return value of "NPEBean.getFurigana()" is null
at NPEStacktrace.main(NPEStacktrace.java:7)NullPointerExceptionが発生した場所を特定する情報として、以下の情報がスタックトレースに出力されていることを確認することができます。
さらに、以下のエラーメッセージが新たに出力されています。
Cannot invoke "String.equals(Object)" because the return value of "NPEBean.getFurigana()" is nullこれを簡単に直訳すると、以下となります。
つまり、NPEBean.getFurigana()の戻り値であるString型のオブジェクト参照がnullであり、
そのnull参照からString.equalsメソッドを実行しようとしてNullPointerExceptionが発生した。
ということが、このスタックトレースのエラーメッセージから読み取ることができます。
エラーに関する情報がここまで揃っていれば、Eclipseのデバッグ機能を使用せず、
NullPointerExceptionが発生した箇所を特定することができるので、解決に要する時間の短縮が期待できるといっても良いでしょう。
Java12からJava17までに新たに追加されたAPIについて、いくつか紹介していきます。
まずは、String型です。
String型は、Javaのバージョンが上がっていくと同時に、開発で役に立つ汎用的なAPIが追加されています。
Stringクラスには、指定された書式をもとに整形した文字列を返すformat()メソッドがありますが、
テキストブロックで定義された書式文字列向けに利用するformatted()メソッドが、Java15より新たに追加されました。
public class StringSample1 {
public static void main(String[] args) {
// String.format()を使用するコード
// format()の第一引数に書式文字列を指定
String result1 = String.format(
"""
名前: %s
年齢: %d
""", "佐藤", 20);
System.out.println(result1);
// String.formatted()を使用するコード
// 変数strに書式文字列を指定
String str =
"""
名前: %s
年齢: %d
""";
String result2 = str.formatted("佐藤", 20);
System.out.println(result2);
}
}名前: 佐藤
年齢: 20
名前: 佐藤
年齢: 20Stringクラスのformat()とformatted()の違いは以下の通りで、書式文字列の中に指定する書式指示子の仕様はどちらも同一です。
どちらを使用するかは、ソースコードの可読性や保守性を重視しながら使い分けていくのが良いでしょう。
| format() | formatted() |
|---|---|
| クラスメソッド | インスタンスメソッド |
| 書式文字列を第一引数に指定する | インスタンスに書式文字列を指定する |
上記サンプルコードの書式文字列に指定している書式指示子の仕様の説明は以下の通りです。
| 書式指示子 | 説明 |
|---|---|
| %s | String型のオブジェクトを文字列としてそのまま出力 |
| %d | intやlongなどの数値を出力 桁数を固定して足りない部分をゼロで埋めるには、桁数の値を指示子に指定する 例)5桁の場合 「%5d」と指定する。 これに「123」が渡されると「00123」と出力される |
ここで取り上げられていない指示子を含む、書式文字列の仕様の詳細について知りたい場合は、
java.util.FormatterクラスのJava APIドキュメントを参照してください。
Stream APIに追加されたAPIについて紹介します。
Stream APIでストリームからリストに変換する方法として、これまではCollectorsクラスを使用していました。
List<SampleBean> beanList = stream
..... (ストリームの中間操作) .....
.collect(Collectors.toList());Java16より、Collectorsクラスを使用せずにリストに変換する終端操作のメソッドとして、toList()が新たに追加されました。
リストからストリームに変換するList.toStream()は最初から提供されているのに対し、ストリームからリストに変換するStream.toList()は提供されていませんでした。
これに対し、ぜひ追加してほしいというJavaユーザーの要望が背景にあり、反映する形の機能追加となりました。
List<SampleBean> beanList = stream
..... (ストリームの中間操作) .....
.toList();このStream.toList()の注意点として、実行結果として返されるリストオブジェクトは、その構成を変更することができない読み取り専用のリストになる点があります。
例えば、要素の追加や削除を実行すると、UnsupportedOperationExceptionが発生します。
| メソッド | 返されるリストの種類 | リストの要素構成の変更 |
|---|---|---|
| Collectors.toList() | ArrayList | 可能 |
| Stream.toList() | Collections.unmodifiableList(ArrayList)で返されるリスト | 不可能 (例外が発生する) |
Collections.unmodifiableList()によって返されるリストの型は、java.util.ImmutableCollections$ListNで、
ユーザーが直接利用することのできないコレクションフレームワーク内部のクラスになります。
Immutableとは「変更不可能」という意味を表し、unmodifiableと同義語です。
Java12からJava17までに導入された機能の基本的な使い方についての説明は、以上です。




