本章では、Enum及びJava 8より導入されたラムダ(Lambda)式とStream APIに関して学習します。
Enumは、複数の定数を1つのクラスへまとめることが行える新たな型で、よく「列挙型」と表現されます。
Enumを使うことでソースコードの可読性、安全性を高めることができ、以下のように定義します。
アクセス修飾子 enum 列挙名 {列挙子1, 列挙子2, ・・・;}Enumには、以下のようなメリットがあります。
それでは、実際にEnumの使い方について見ていきましょう。
Enumを学ぶ前に、まずは定数について復習しましょう。
public class Prefecture {
public static final String FUKUOKA = "福岡県";
public static final String SAGA = "佐賀県";
public static final String NAGASAKI = "長崎県";
public static final String KUMAMOTO = "熊本県";
public static final String OITA = "大分県";
public static final String MIYAZAKI = "宮崎県";
public static final String KAGOSHIMA = "鹿児島県";
public static final String OKINAWA = "沖縄県";
}上記のように型の前に、final を付けることで定数として宣言することが可能でした。
ここでは、Prefecture という定数を宣言するためのクラスを作成し、クラス変数として定数を定義しています。
このように定数を宣言するクラスを作成することで、定数の値の情報が一クラスに集約されるため、加筆修正等が容易になります。
上記で宣言したクラスは、下記のように用いることが出来ます。
public class StaticMain {
public static void main(String[] args) {
String prefecture = Prefecture.OKINAWA;
System.out.println(prefecture + "の人口は"
+ population(prefecture) + "人です");
}
// 各都道府県の人口をreturnするメソッド
private static String population(String prefecture) {
String population = null;
switch (prefecture) {
case Prefecture.FUKUOKA:
population = "5,101,556";
break;
case Prefecture.SAGA:
population = "832,832";
break;
case Prefecture.NAGASAKI:
population = "1,377,187";
break;
case Prefecture.KUMAMOTO:
population = "1,786,170";
break;
case Prefecture.OITA:
population = "1,166,338";
break;
case Prefecture.MIYAZAKI:
population = "1,104,069";
break;
case Prefecture.KAGOSHIMA:
population = "1,648,177";
break;
case Prefecture.OKINAWA:
population = "1,433,566";
break;
}
return population;
}
}Prefectureクラスでは、クラス変数として定義しているため、インスタンス化することなく用いることが出来ます。
それでは、Enumについて学んでいきましょう。
Enumは前述の通り「列挙型」と表現されます。
ただ、「列挙型」といっても想像が付き難いと思いますので、実際のコードを作成しながら見ていきます。
Enumを作成するやり方は、クラス作成の手順とほとんど同様です。
Enumを作成したいフォルダを右クリックし、メニューから「新規」⇒「列挙型」を選択し、名前を入力します。
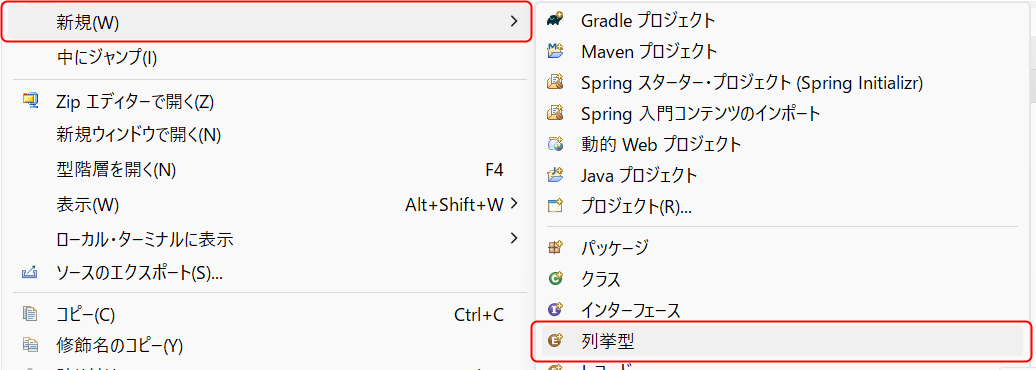
Enumを作成したら、次のサンプルソースの内容を記述してください。
※ コード内の、(1)~(5)の値は記述不要です
(1)
public enum PrefectureEnum {
(2)
FUKUOKA("福岡県"),
SAGA("佐賀県"),
NAGASAKI("長崎県"),
KUMAMOTO("熊本県"),
OITA("大分県"),
MIYAZAKI("宮崎県"),
KAGOSHIMA("鹿児島県"),
OKINAWA("沖縄県");
(3)
private String prefectureName;
(4)
private PrefectureEnum(String prefectureName) {
this.prefectureName = prefectureName;
}
(5)
public String getPrefectureName() {
return prefectureName;
}
}上記は先ほどの項で作成した、Prefecture クラスとほぼ同じ役割を持ちます。
Enumの記載方法は簡単で、下記の通りになります。
| (1) | 通常 public class ~ と続くところを public enum ~ とする。 |
| (2) | public enum の下に列挙子で宣言する。 ※列挙子とはサンプルの「FUKUOKA」や「SAGA」等を指します |
| (3) | 上で宣言した「値」に対応する変数をprivateで宣言する。 |
| (4) | 上で宣言した変数を引数に持つコンストラクタを宣言する。 |
| (5) | 変数を取得するためのメソッドをpublicで作成する。 |
さて、作成したEnumは下記のように用いることができます。
public class EnumMain {
public static void main(String[] args) {
// PrefectureEnum型のKUMAMOTOを用いることを宣言
PrefectureEnum prefectureEnum = PrefectureEnum.KUMAMOTO;
System.out.println(prefectureEnum.getPrefectureName()
+ "の人口は" + population(prefectureEnum) + "人です");
}
// 各都道府県の人口をreturnするメソッド
private static String population(PrefectureEnum prefecture) {
String population = null;
// 引数prefectureには、mainメソッド側でKUMAMOTOを用いた変数を渡しているため、
// case KUMAMOTOと合致する。このようにEnumはswich-case文と相性が良い
switch (prefecture) {
case FUKUOKA:
population = "5,101,556";
break;
case SAGA:
population = "832,832";
break;
case NAGASAKI:
population = "1,377,187";
break;
case KUMAMOTO:
population = "1,786,170";
break;
case OITA:
population = "1,166,338";
break;
case MIYAZAKI:
population = "1,104,069";
break;
case KAGOSHIMA:
population = "1,648,177";
break;
case OKINAWA:
population = "1,433,566";
break;
}
return population;
}
}先の定数を用いたコードとの違いは、populationメソッドの引数のデータ型が、String型ではなく、先ほど作成した PrefectureEnum型になっていることです。
列挙型を引数として定義することで、列挙型(ここではPrefectureEnum型)で宣言している列挙子しか渡せなくなるため、
String型にした場合などに発生しうる、想定していない値が渡されることがなくなる点がメリットとなります。
また、ここでは直接関係はしませんが、Enumは単純に == で比較することが出来ます。
先ほど紹介したEnumは、値を1種類だけ設定しましたが、値を複数設定することも可能です。
以下、サンプルソースに従って、先程作成した「PrefectureEnum.java」と「EnumMain.java」を書き換えてみましょう。
public enum PrefectureEnum {
// 人口に関する値を追加
FUKUOKA("福岡県","5,101,556"),
SAGA("佐賀県","832,832"),
NAGASAKI("長崎県","1,377,187"),
KUMAMOTO("熊本県","1,786,170"),
OITA("大分県","1,166,338"),
MIYAZAKI("宮崎県","1,104,069"),
KAGOSHIMA("鹿児島県","1,648,177"),
OKINAWA("沖縄県","1,433,566");
private String prefectureName;
// 人口を追加
private String population;
// コンストラクタに人口の引数を追加し、フィールドへの代入処理を追加
private PrefectureEnum(String prefectureName, String population) {
this.prefectureName = prefectureName;
this.population = population;
}
public String getPrefectureName() {
return prefectureName;
}
// 人口を取得するためのメソッドを追加
public String getPopulation() {
return population;
}
}上記のコメント部分が、「人口」に関する部分を追加した箇所です。
これに伴い、EnumMainクラスの呼び出し方も変更します。
public class EnumMain {
public static void main(String[] args) {
// PrefectureEnum型のKUMAMOTOを用いることを宣言
PrefectureEnum prefectureEnum = PrefectureEnum.KUMAMOTO;
System.out.println(prefectureEnum.getPrefectureName()
+ "の人口は" + prefectureEnum.getPopulation() + "人です");
}
}書き換えたら、EnumMainクラスを実行してみてください。
結果は、先程と同様であることが確認できますが、コードがより簡潔になったことが分かります。
このように、必要に応じて複数の値を持たせることで、関連情報をまとめて管理できるため、便利です。
次に、Enumで暗黙的に定義されるメソッドについて見ていきます。
Enumはデフォルトで下記のメソッドを暗黙的に定義しています。
とくにメソッドを追加せずとも利用できるため、覚えておきましょう。
下記は暗黙に定義される主なメソッドです。
| メソッド名 | static | 概要 |
|---|---|---|
| name | 列挙子の名前を取得します。 | |
| ordinal | 列挙子の順番(定義した順番)を取得します。 | |
| valueOf | 〇 | 与えられた引数の文字列に該当する列挙子のオブジェクトを取得します。 |
| values | 〇 | 列挙子を順番に並べた配列を取得します。 |
Enumには暗黙に定義されるメソッドとは別に、Enumへ定義された値を利用した独自のメソッドを追加することが可能です。
独自のメソッドでは、前項の暗黙に定義されるメソッドも利用可能です。
それでは、サンプルソースに従って「PrefectureEnum.java」と「EnumMain.java」を更に書き換えてみましょう。
public enum PrefectureEnum {
// 都道府県コードの値を追加
FUKUOKA(40, "福岡県","5,101,556"),
SAGA(41, "佐賀県","832,832"),
NAGASAKI(42, "長崎県","1,377,187"),
KUMAMOTO(43, "熊本県","1,786,170"),
OITA(44, "大分県","1,166,338"),
MIYAZAKI(45, "宮崎県","1,104,069"),
KAGOSHIMA(46, "鹿児島県","1,648,177"),
OKINAWA(47, "沖縄県","1,433,566");
// 都道府県コード
private int prefectureCode;
// 都道府県名
private String prefectureName;
// 人口
private String population;
private PrefectureEnum(int prefectureCode, String prefectureName, String population) {
this.prefectureCode = prefectureCode;
this.prefectureName = prefectureName;
this.population = population;
}
// Enumに設定された都道府県コードを取得する
public int getPrefectureCode() {
return prefectureCode;
}
// Enumに設定された都道府県名を取得する
public String getPrefectureName() {
return prefectureName;
}
// Enumに設定された人口を取得する
public String getPopulation() {
return population;
}
/**
* 引数の都道府県コードから都道府県名を取得する(追加した独自メソッド)
* @param prefectureCode 都道府県コード
* @return 都道府県名
* 存在しない都道府県コードが指定された場合はnull
*/
public static String getPrefectureNameByCode(int prefectureCode) {
PrefectureEnum[] array = values();
for(PrefectureEnum preEnum : array) {
if (preEnum.prefectureCode == prefectureCode) {
return preEnum.prefectureName;
}
}
return null;
}
}public class EnumMain {
public static void main(String[] args) {
// Enum「FUKUOKA」の列挙子の名前を出力
System.out.println(PrefectureEnum.FUKUOKA.name()); // FUKUOKA
// Enum「FUKUOKA」の都道府県名を出力
System.out.println(PrefectureEnum.FUKUOKA.getPrefectureName()); // 福岡県
// 都道府県コードからEnum「FUKUOKA」の都道府県名を出力
System.out.println(PrefectureEnum.getPrefectureNameByCode(40)); // 福岡県
}
}FUKUOKA
福岡県
福岡県上記では暗黙に定義されたメソッド、Enumのインスタンスメソッド、PrefectureEnumのクラスメソッドそれぞれから値の出力を行っています。
それぞれ1つ1つ見ていきましょう。
System.out.println(PrefectureEnum.FUKUOKA.name());Enumに暗黙に定義されたnameメソッドを使用して列挙子の名前を取得し、コンソールへ出力しています。
System.out.println(PrefectureEnum.FUKUOKA.getPrefectureName());これまで同様、Enumのインスタンスメソッドを使用してEnumに設定されている都道府県名を取得し、コンソールへ出力しています。
System.out.println(PrefectureEnum.getPrefectureNameByCode(40));こちらは、PrefectureEnumに定義した独自のgetPrefectureNameByCodeメソッドに都道府県コードを引数として渡し、
その都道府県コードを持ったEnumの都道府県名を取得してコンソールへ出力しています。
都道府県名を取得するgetPrefectureNameByCodeメソッドの内容を見てみましょう。
public static String getPrefectureNameByCode(int prefectureCode) {
PrefectureEnum[] array = values();
for(PrefectureEnum preEnum : array) {
if (preEnum.prefectureCode == prefectureCode) {
return preEnum.prefectureName;
}
}
return null;
}このメソッドでは、最初に暗黙に定義されたメソッドであるvaluesメソッドを利用し、PrefectureEnumクラスで定義した全ての列挙子を配列で取得しています。
その後、取得した配列要素の繰り返し処理を行い、その中で引数の都道府県コードに一致した値がある場合に、対象となるEnumの都道府県名を返却しています。
Enumに関する説明は以上となります。
ラムダ式とは、関数型プログラミングの考え方をもとに実現されたプログラムの記法です。
この後学習するStream APIでよく利用されますので、ラムダ式の基本的な構文について学習していきましょう。
関数型プログラミングとは、関数型言語と呼ばれるプログラミング言語で利用されてきました。
「関数」は、ここでは「ある入力に対して、出力が1つに定まる」ことを指します。
この考え方をもとにコーディングすることにより、より簡潔でメンテナンスしやすいプログラムが実現できます。
Java言語では、「関数型インターフェース」を使用して、ラムダ式を記述していきます。
関数型インターフェースとは、「ポリモフィズム」の章で学習した、インターフェースの1つです。
以下のような特徴があります。
では、2つの特徴について詳しく説明していきます。
@FunctionalInterface
public interface Hello {
public String sayHello(String name); // 抽象メソッド
}Helloインターフェースに、sayHelloという抽象メソッドを1つだけ定義しています。
関数型インターフェースは、このように抽象メソッドを1つだけ定義したインターフェースです。
「@FunctionalInterface」は「FunctionalInterfaceアノテーション」といいます。
アノテーションとは「注釈」と呼ばれ、メソッドやクラスに付与することができます。
アノテーションを付与した場合、そのアノテーションの規則に従ってプログラムを書く必要があり、スペルミスやバグの発生を防止することができます。
@FunctionalInterfaceを付けることにより、関数型インターフェースの条件を満たしていない場合(抽象メソッドを複数持つ場合など)にコンパイルエラーとなります。
複雑なプログラムを構築していくようになると、クラス間で使いまわしたりせず、その場だけで一時的に使用したい抽象クラスやインターフェースを実装したクラスが必要になることがあります。
このような場合、匿名クラスという特殊なクラス定義を使うことができます。
匿名クラスは、一時的に使用する名前(変数名)がないクラスとして以下のような構文で記述します。
new 抽象クラスまたはインターフェース() {
抽象メソッドをオーバーライドした処理など
};なお、匿名クラスは無名クラスとも呼ばれることがあります。
それでは、関数型インターフェースの利用方法について説明していきます。
まずは、今まで学習してきた方法で、先程作成したHello.javaを利用してみます。
Helloインターフェースをimplementsして、sayHelloメソッドを実装します。
public class HelloImpl implements Hello {
// sayHelloメソッドをオーバーライド
public String sayHello(String name) {
return "Hello!" + name;
}
}HelloImplクラスをインスタンス化して、sayHelloメソッドを呼び出します。
public class LambdaTest1 {
public static void main(String[] args) {
Hello hello = new HelloImpl();
// Hello!Tanakaの表示
System.out.println(hello.sayHello("Tanaka"));
}
}LambdaTest1クラスを実行すると、以下のようになります。
Hello!Tanakaここまでは、「ポリモフィズム」の章の復習となります。
次に、匿名クラスを利用した場合の実装のサンプルソースは、以下となります。
public class LambdaTest2 {
public static void main(String[] args) {
Hello hello = new Hello() {
public String sayHello(String name) {
return name + "さん、こんにちは!これは匿名クラスです!";
}
};
System.out.println(hello.sayHello("yamada"));
}
}yamadaさん、こんにちは!これは匿名クラスです!hello変数への代入時に、あたかもHelloインターフェースのインスタンスを生成しているように見えますが、 new
Hello()のあとに{}があり、その中でsayHelloメソッドをオーバーライドしています。
匿名クラスを使った実装方法では、先程のHelloImplクラスのような実装クラスが不要となるため、使いまわす必要が無い場合は、簡潔なソースにすることが可能です。
続いて、上記の匿名クラスを使ったプログラムを、ラムダ式を使って書き換えてみます。
public class LambdaTest3 {
public static void main(String[] args) {
// HelloインターフェースのsayHelloメソッドの処理を実装
Hello hello = (String name) -> {
return "Hello!" + name;
};
// Hello!Tanakaの表示
System.out.println(hello.sayHello("Tanaka"));
}
}見慣れない書き方に戸惑うかもしれませんが、処理自体は先ほどの匿名クラスを使ったサンプルソースと一緒です。
Helloインタフェースの実装と、それを利用したプログラムを同時に1つのクラス内で実装しています。
ラムダ式の基本構文は以下のようになります。
インターフェース名 オブジェクト名 = (引数1, 引数2, ・・・) -> {return 処理内容;};上記の例に当てはめてみると、インターフェース名は「Hello」、 オブジェクト名は「hello」、引数は「name」で、{}内(コードブロック)が処理内容となります。
「->」はアロー演算子とも呼ばれ、以下のように使います。
( 実装するメソッドの引数 ) -> { 具体的な処理 };サンプルでは、引数としてString型の変数nameをコードブロックに引き渡しています。
「HelloImpl.java」や匿名クラスの実装部分に当てはめると、「sayHello(String name) { ・・・ }」の「String name」部分にあたります。
なお、上記のサンプルのように実装するメソッドの引数が1つだけの場合、以下のように引数の型と、()を省略することもできます。
Hello hello = name -> {
return "Hello!" + name;
};さらに、処理が1行で完結するような単文の場合は、returnと{}も省略することができます。
Hello hello = name -> "Hello!" + name;このように、ラムダ式を使うことで、プログラムをさらに簡潔に記述することができるようになりました。
Stream APIは、Java 8より導入されました。
これまでの学習では、配列やコレクションに対して、for文などの繰り返し文を用いて、様々な処理を行ってきましたが、
Stream APIを使うことで、配列やコレクションなどのデータの集合に対する処理を簡潔に書くことができるようになります。
ここでは、Stream APIの基本的な構文について学習していきます。
上述したように、配列やコレクションなどのデータの集合に対して、集計、検索、データ抽出などを行うAPIです。
APIとは「Application Programming Interface(アプリケーション・プログラミング・インターフェイス)」の略語で、
「アプリケーションの様々な機能を共有するための仕組み」のようなイメージです。
Stream APIの仕組みを利用して、配列やコレクションなどに対して、様々な操作を行っていくといった流れになります。
Stream APIには、以下のような特徴があります。
それでは、Stream APIの基本構文について、サンプルソースを見ながら確認していきましょう。
以下は、「s」から始まる名前だけを抽出し、出力するサンプルです。
まずはStream APIを使わない場合について見てみましょう。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class StreamTest1 {
public static void main(String[] args) {
// String型配列の生成と、要素の代入
final String[] data = { "shimizu", "tanaka", "sasaki", "suzaki" };
// 配列をString型のListに変換
List<String> list = Arrays.asList(data);
// 結果を格納するListの用意
List<String> outputList = new ArrayList<String>();
// listの要素を拡張for文で取り出し、「s」から始まる要素のみ
// outputListに格納
for (String name : list) {
if (name.startsWith("s")) {
outputList.add(name);
}
}
// コンソール出力
for (String str : outputList) {
System.out.println(str);
}
}
}まず、名前の入った配列を生成します。
// String型配列の生成と、要素の代入
final String[] data = { "shimizu", "tanaka", "sasaki", "suzaki" };次に、Arrays.asList(data)で、配列をListに変換しています。
配列のままでも問題ありませんが、後ほどのStream APIを使った場合の説明のために、Listに変換をしています。
// 配列をString型のListに変換
List<String> list = Arrays.asList(data);そして、拡張for文を用いて要素を1つ1つ取り出し、条件に合致する要素のみoutputListにaddしています。
結果についても、拡張for文を使って、出力しています。
では、作成したサンプルソースを、Stream APIを使って書き換えてみましょう。
import java.util.Arrays;
import java.util.List;
public class StreamTest2 {
public static void main(String[] args) {
// String型配列の生成と、要素の代入
final String[] data = { "shimizu", "tanaka", "sasaki", "suzaki" };
// 配列をString型のListに変換
List<String> list = Arrays.asList(data);
// Streamを生成し、「s」から始まる要素だけを抽出して出力
list.stream().filter(name -> name.startsWith("s")).forEach(str -> System.out.println(str));
}
}こちらについても、上から順に処理を見ていきましょう。
// String型配列の生成と、要素の代入
final String[] data = { "shimizu", "tanaka", "sasaki", "suzaki" };
// 配列をString型のListに変換
List<String> list = Arrays.asList(data);ここまでは、先ほどのサンプルとまったく同様です。
異なるのは次の1行になります。
list.stream().filter(name -> name.startsWith("s")).forEach(str -> System.out.println(str));Stream APIに置き換えた場合、拡張for文を用いて実装していた以下の処理が、この1行にて実行されています。
こちらについて、以降で詳しく説明をしていきます。
Stream APIは、基本的に「中間操作」と「終端操作」というStreamに対する操作を使って処理を記述します。
Streamを生成し、それに対していくつもの中間操作を行います。
中間操作の結果を次の中間操作に引き渡し、最終的に終端操作に結果を引き渡して処理をします。
先ほどのサンプルソースの場合、「s」から始まる要素を抽出する処理が中間操作にあたります。
また、例えば並べ替え(ソート)や要素の変換など、様々な処理を中間操作で行うことができます。
中間操作と終端操作について、先ほどのサンプルソースで確認していきます。
list.stream().filter(name -> name.startsWith("s")).forEach(str -> System.out.println(str));この1行で「Streamの生成」、「中間操作」、「終端操作」を実行しています。
1つずつ分解して見ていきましょう。
まずは、List型のオブジェクトからStreamを生成します。
list.stream()続いて、生成したStreamを受け取って、以下のような「中間操作」を行います。
filter(name -> name.startsWith("s"))最後に、「中間操作」の結果を受け取り、以下のような「終端操作」を行います。
forEach(str -> System.out.println(str))上記の内容を踏まえながら、以降の節で中間操作、終端操作それぞれについて順番に見ていきます。
サンプルでは、filterメソッドを使い「s」から始まる要素のみを取得しています。
filter(name -> name.startsWith("s"))filterメソッドには、引数としてラムダ式で渡す必要があり、このラムダ式が関数型インターフェースの実装クラスとなります。
ここでの処理のイメージとしては、
となり、その結果、「s」から始まる名前の要素が抽出されます。
forEachメソッドもfilterメソッドと同様、ラムダ式を引数に取ります。
forEach(str -> System.out.println(str))中間操作から受け取ったStreamの要素を1つずつ取り出して操作を行うため、拡張for文のように繰り返し操作を実行することができます。
上記のサンプルの場合は、forEachメソッドで要素を取り出しながらコンソール出力を行っています。
なお、クラスメソッドやインスタンスメソッドをラムダ式の処理実装部分に記述する場合、省略して記述することができます。
// クラスメソッドの場合
クラス名::メソッド名
// インスタンスメソッドの場合
インスタンス変数名::メソッド名そのため、上記のforEachの部分は、以下のように記述することも可能です。
// forEach(str -> System.out.println(str))
// ↓ 以下にしても同じ結果になります。
forEach(System.out::println)forEachメソッドで要素を出力する場合、こちらの記述の方が多く使われるため、覚えておきましょう。
以上のように、ラムダ式とStream APIを組み合わせることで、コレクションに対する様々な操作を簡潔に記述できるようになりました。
中間操作には、filterメソッドの他にも様々なメソッドが用意されていますので、いくつか紹介します。
mapメソッドはStreamの内容を変換する中間操作になります。
filterメソッドと同様に多く利用されます。
具体的な書き方については、前項のサンプルソースを元に書き換えて確認していきます。
import java.util.Arrays;
import java.util.List;
public class StreamTest3 {
public static void main(String[] args) {
// String型配列の生成と、要素の代入
final String[] data = { "shimizu", "tanaka", "sasaki", "suzaki" };
// 配列をString型のListに変換
List<String> list = Arrays.asList(data);
// (書き換え部分)
// Streamを生成し、事前に代入したString型の各要素の末尾に「taro」を付与して出力
list.stream().map(strData -> strData + " taro").forEach(System.out::println);
}
}shimizu taro
tanaka taro
sasaki taro
suzaki taro前項の「StreamTest2.java」では中間操作にはfilterを利用していましたが、それをmapに変更しました。
また、forEachメソッドの出力部分の記述も変更しています。
list.stream().map(strData -> strData + " taro").forEach(System.out::println);こちらでは、Streamから取得できる要素全てに対して、末尾に「taro」の文字を付与する形での値変換を行っています。
中間操作は複数組み込むことが可能です。
前項の「StreamTest2.java」では「「s」から始まる要素だけを抽出」という中間操作を行っていましたが、
今回の中間操作と併せて下記のような実装も可能です。
// 「s」から始まる要素だけを抽出し、抽出した各要素の末尾に「taro」を付与して出力
list.stream().filter(name -> name.startsWith("s")).map(s -> s + " taro").forEach(System.out::println);shimizu taro
sasaki taro
suzaki taro必要に応じて、複数の中間操作を組み込んでいくと良いでしょう。
sortedメソッドは、Streamの内容を並び替える中間操作になります。
mapと同様に、前項のサンプルソースを元に書き換えて確認していきます。
import java.util.Arrays;
import java.util.List;
public class StreamTest4 {
public static void main(String[] args) {
// String型配列の生成と、要素の代入
final String[] data = { "shimizu", "tanaka", "sasaki", "suzaki" };
// 配列をString型のListに変換
List<String> list = Arrays.asList(data);
// (書き換え部分)
// Streamを生成し、Streamの内容を昇順に並び替え
list.stream().sorted().forEach(System.out::println);
}
}sasaki
shimizu
suzaki
tanakasortedメソッドを使用することにより、昇順での並び替えが可能となります。
list.stream().sorted()また、以下のようにsortedメソッドの引数にComparator.reverseOrder()を指定することで、降順への並び替えも可能です。
list.stream().sorted(Comparator.reverseOrder())こちらで実行した場合の結果が下記になります。
tanaka
suzaki
shimizu
sasaki中間操作には、この他にも以下のようなメソッドがあります。
| メソッド名 | 概要 |
|---|---|
| flatMap | 多重構造で保持される各要素をフラットな構造に纏め(変換)ます。 |
| skip | skip(n)で、n個目のまでの要素を読み飛ばし、それ以降の要素を取得します。 |
| limit | limit(n)で、n個目までの要素を取得し、それ以降を除去します。 |
終端操作も、forEachメソッドの他にも様々なメソッドが用意されていますので、いくつか紹介します。
collectメソッドはStreamの内容でListやMapの生成を行う、終端操作になります。
以下はStreamの処理で抽出処理を行った後、抽出結果をリストとして返却するサンプルソースになります。
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class StreamTest5 {
public static void main(String[] args) {
// String型配列の生成と、要素の代入
final String[] data = { "shimizu", "tanaka", "sasaki", "suzaki" };
// 配列をString型のListに変換
List<String> list = Arrays.asList(data);
// Streamを生成し、「s」から始まる要素だけを抽出し、リストを生成
List<String> collectList = list.stream().filter(
name -> name.startsWith("s")).collect(Collectors.toList());
System.out.println(list);
System.out.println(collectList);
}
}[shimizu, tanaka, sasaki, suzaki]
[shimizu, sasaki, suzaki]リストを生成する処理は、collectメソッドを記述している、以下の部分になります。
collect(Collectors.toList())collectメソッドには、Collectorインターフェースの実装クラスを渡す必要があり、
今回のサンプルでは「toList()」を渡してListが生成されるようにしています。
なお、ListではなくMapを生成する場合は以下のように、「toMap()」をcollectメソッドの引数に渡します。
collect(Collectors.toMap(key -> key, value -> value))anyMatchメソッドはStreamの要素に対し、条件に一致する要素があるか判定し、結果を取得する終端操作になります。
以下は、Stream内に「tanaka」が存在するか判定を行うサンプルソースになります。
import java.util.Arrays;
import java.util.List;
public class StreamTest6 {
public static void main(String[] args) {
// String型配列の生成と、要素の代入
final String[] data = { "shimizu", "tanaka", "sasaki", "suzaki" };
// 配列をString型のListに変換
List<String> list = Arrays.asList(data);
// Streamを生成し、「tanaka」が存在するか判定
if (list.stream().anyMatch(name -> name.equals("tanaka"))) {
System.out.println("Stream内にtanakaが存在します。");
} else {
System.out.println("Stream内にtanakaが存在しません。");
}
}
}Stream内にtanakaが存在します。anyMatchメソッドでは、条件に一部の要素が一致する場合はtrueが取得しますが、類似のメソッドとして以下があります。
終端操作には、この他にも以下のようなメソッドがあります。
| メソッド名 | 概要 |
|---|---|
| max、min | Stream内の最大値要素や最小値要素を取得します。 |
| findFirst | Stream内の最初の要素を取得します。 |
一部の終端操作で取得できる結果の型には、Optional型というものがあります。
以下はOptional型で提供されるメソッドの一部になります。
| メソッド名 | 概要 |
|---|---|
| get | Optional型で保持されている値を取得します。 |
| isPresent | Optional型で保持されている値が存在するか判定します。存在すればtrueを取得します。 |
| ifPresent | Optional型で保持されている値が存在する場合に実行したい処理を引数に指定することができます。 |
| orElse | Optional型で保持されている値が存在する場合は値の取得を行い、存在しない場合は引数に指定した値を取得します。 |
Optional型は値が存在するかのチェックや値が存在しない場合に別値に置き換え等が行えます。
本章では詳しい説明は割愛しますが、頭の片隅には置いておきましょう。
Stream APIを使いこなせるようになると、非常に複雑な処理を簡潔に記述することも可能になります。
やや難易度が高く感じるかもしれませんが、開発現場で使う場面も増えてきていますので、基本は押さえておくようにしましょう。
ラムダ式とStream APIに関する説明は以上です。
Enumの練習問題です。
以下のメッセージコードとメッセージを持つEnumを定義し、メッセージコードからメッセージを取得できるメソッドを作成してください。
また、作成したEnumを呼び出して実行する、mainメソッドを持つクラスもあわせて実装してください。
| メッセージコード | メッセージ |
|---|---|
| 001 | INFOメッセージ |
| 002 | WARNメッセージ |
| 003 | ERRORメッセージ |
public class MessageEnumMain {
public static void main(String[] args) {
/* ここに追記(作成したEnumを呼び出し、INFOメッセージをコンソールへ出力) */
/* ここに追記(作成したEnumを呼び出し、ERRORメッセージをコンソールへ出力) */
}
}public enum MessageEnum {
INFO("001", "INFOメッセージ"),
WARN("002", "WARNメッセージ"),
ERROR("003", "ERRORメッセージ");
// メッセージコード
private String messageCode;
// メッセージ
private String message;
private MessageEnum(String messageCode, String message) {
this.messageCode = messageCode;
this.message = message;
}
public String getMessageCode() {
return messageCode;
}
public String getMessage() {
return message;
}
/**
* 引数のメッセージコードからメッセージを取得する
*
* @param messageCode メッセージコード
* @return メッセージコードに一致するメッセージ / 一致しない場合はnull
*/
public static String getMessageByCode(String messageCode) {
MessageEnum[] array = values();
for(MessageEnum msgEnum : array) {
if (msgEnum.messageCode.equals(messageCode)) {
return msgEnum.message;
}
}
return null;
}
}public class MessageEnumMain {
public static void main(String[] args) {
// INFOメッセージをコンソールへ出力する
System.out.println(MessageEnum.getMessageByCode("001"));
// ERRORメッセージをコンソールへ出力する
System.out.println(MessageEnum.getMessageByCode("003"));
}
}INFOメッセージ
ERRORメッセージ MessageEnum.javaでは、Enumに複数の定数値をまとめて定義しています。
そして、独自に追加したgetMessageByCodeメソッド内で、暗黙的に定義されているvaluesメソッドを利用して全てのEnumを検索する処理をしています。
getMessageByCodeメソッドは、MessageEnum.java内の全てのEnumを参照するため、クラスメソッドとして定義をしてください。
問題1で作成したEnumの定義を以下のように修正し、ラベルからメッセージを取得するメソッドを作成してください。
また、mainメソッドを持つクラスに、ラベルからメッセージを取得するメソッドを呼び出す処理も追加してください。
| メッセージコード | ラベル | メッセージ |
|---|---|---|
| 001 | 【通知】 | INFOメッセージ |
| 002 | 【警告】 | WARNメッセージ |
| 003 | 【異常】 | ERRORメッセージ |
| 004 | 【詳細】 | DETAILメッセージ |
public class MessageEnumMain {
public static void main(String[] args) {
/* 問題1で実装した処理の下に以下を追記 */
/* ラベル【警告】からメッセージを呼び出して、コンソールへ出力する処理 */
/* ラベル【詳細】からメッセージを呼び出して、コンソールへ出力する処理 */
}
}※この問題の解答は掲載しておりません。Tech Fun ITスクールのJava研修では、講師が丁寧に解説しています。
現在Tech Fun ITスクールでは、新規受講者の募集は行なっておりません。
ラムダ式とStream APIの練習問題です。
以下は関数型インターフェースとStream APIを用いた抽出処理を実装をしています。
関数型インターフェースの実装を用いて、抽出処理を完成させてください。
import java.util.List;
@FunctionalInterface
public interface FilterFunction {
public List<String> filterFunc(List<String> list);
}import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class FilterFunctionTest {
public static void main(String[] args) {
List<String> nameList = Arrays.asList("sato", "ito", "tanaka", "sasaki", "suzuki");
// FilterFunctionクラスを実装して「s」から始まる要素だけを抽出する
FilterFunction function = (list) -> {
return list.stream().filter(name ->
name.startsWith("s")).collect(Collectors.toList());
};
/* ここに追記(上記で抽出した結果をコンソールへ出力する) */
}
}sato
sasaki
suzukiimport java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class FilterFunctionTest {
public static void main(String[] args) {
List<String> nameList = Arrays.asList("sato", "ito", "tanaka", "sasaki", "suzuki");
// FilterFunctionクラスを実装して「s」から始まる要素だけを抽出する
FilterFunction function = (list) -> {
return list.stream().filter(name ->
name.startsWith("s")).collect(Collectors.toList());
};
// 抽出した結果をコンソールへ出力する
function.filterFunc(nameList).stream().forEach(System.out::println);
}
} FilterFunctionはListを引数で受け取り、Listを返却する抽象メソッドが定義されています。
ラムダ式の実装は前項の「ラムダ式を利用した実装」のLambdaTest3.javaと同じ形式になります。
FilterFunction function = (list) -> {
};抽出処理には、filterメソッドを利用します。
list.stream().filter(name -> name.startsWith("s"))また、抽出結果をリストとして返却する必要があるため、終端操作にcollectメソッドを利用しています。
list.stream().filter(name -> name.startsWith("s")).collect(Collectors.toList());これらのStream APIの処理とラムダ式を合わせると下記のような処理になります。
// FilterFunctionクラスを実装して「s」から始まる要素だけを抽出する
FilterFunction function = (list) -> {
return list.stream().filter(name -> name.startsWith("s")).collect(Collectors.toList());
}; 実装されたFilterFunctionのfilterFuncメソッドはリストを返却するため、
それらをコンソールへ出力する場合はFilterFunctionのfilterFuncメソッドの結果からStreamを生成し、
これまでと同様にforEachメソッドにて繰り返し処理を行います。
function.filterFunc(nameList).stream().forEach(System.out::println);以下はStream APIを用いた抽出処理を実装をしています。
関数型インターフェースの実装を用いて、抽出処理を完成させてください。
ただし、FilterFunctionインターフェースは問題1で使用したものを再利用してください。
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class FilterFunctionTest2 {
public static void main(String[] args) {
List<String> nameList = Arrays.asList("sato", "ito", "tanaka", "sasaki", "suzuki", "kikuchi", "matsumoto", "yamada", "sakurai", "ueda", "kimura");
/* ここに追記(nameListの要素のうち、4個目までの要素を読み飛ばし、そこから3個目までの要素を取得する。) */
/* ここに追記(上記で抽出した結果をコンソールへ出力する) */
}
}suzuki
kikuchi
matsumoto※この問題の解答は掲載しておりません。Tech Fun ITスクールのJava研修では、講師が丁寧に解説しています。
現在Tech Fun ITスクールでは、新規受講者の募集は行なっておりません。
本章で学んだ内容は、どれも慣れるまでは難しく感じるかもしれません。
理解を深めるために、教材のサンプルコードを少し変更して、いろいろなパターンを試してみると良いでしょう。
Enum・ラムダ式・Stream APIについての説明は、以上です。




