データ検索と聞くと、多くの場合は「完全一致検索」や「部分一致検索」を思い浮かべるのではないでしょうか。
データベースに保存されている文字列と、検索クエリが一致すればヒットする、という仕組みです。
一方で、実務では次のような場面も少なくありません。
こうした課題を解決する手法の一つが類似検索です。
そして、その中核となる技術がエンベディング(埋め込み表現)と呼ばれるものです。
本記事では、「エンベディングとは何か」、「なぜ類似検索ができるようになるのか」を、デモを交えながら説明します。
エンベディングとは、
といったデータを、その意味や特徴を保ったままベクトル(数値の配列)に変換する技術です。
この変換を行うことで、
ようになります。
つまり、人間が感覚的に行っている「これとあれは似ている」という判断を、数学的に扱えるようにする仕組みだと考える事ができます。
では、実際にエンベディングを用いて、どのように類似検索を行うのか見てみましょう。
ここではわかりやすさ重視で、単語の類似検索を行ってみます。
実際のエンベディングは、3072次元、1536次元、768次元といった高次元ベクトルを利用するのが一般的です。
ただし、高次元のままでは図示ができないため、本記事では可視化を目的として、1536次元で生成されるベクトルを主成分分析(PCA)という技術を用いて、2次元まで圧縮します。
実運用では精度の観点から高次元のまま利用するのが一般的です。
今回のデモでは、エンベディングモデルにOpenAIのtext-embedding-3-smallを使用します。
※ OpenAIのライブラリの機能で直接2次元のベクトルを生成する機能はありますが、高次元生成→主成分分析をしたほうが精度が良くなることが多いため、今回は主成分分析を採用しています。
エンベディングの性質が分かりやすくなるよう、ジャンルが異なる2つのカテゴリを用意しました。
Python
JavaScript
プログラミング
実装
デバッグ
AI
機械学習
深層学習
データ分析
人工知能
寿司
ラーメン
カレー
ハンバーグ
パスタ
自動車
電車
バス
飛行機
自転車
この構成により、「意味が近い単語はまとまり、関係のない単語は離れる」という挙動を視覚的に確認できます。
以下は、OpenAI APIで2次元のベクトルを生成するサンプルコードです。
import numpy as np
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI()
words = [
"Python", "JavaScript", "プログラミング", "実装", "デバッグ",
"AI", "機械学習", "深層学習", "データ分析", "人工知能",
"寿司", "ラーメン", "カレー", "ハンバーグ", "パスタ",
"自動車", "電車", "バス", "飛行機", "自転車",
]
# デフォルトで1536次元のベクトルが生成される
response = client.embeddings.create(
model="text-embedding-3-small",
input=words,
)
vectors = np.array([d.embedding for d in response.data])
# 主成分分析という技術で、1536次元を2次元に圧縮(ここの説明は省略)
vectors_2d = pca_to_2d(vectors)
for word, vector in zip(words, vectors_2d):
print(f"{word}: {vector}")
実行すると、下記のようなベクトルが得られます。
Python: [-0.15126746 0.35255755]
JavaScript: [-0.05191365 0.37248566]
プログラミング: [-0.12384383 0.2774263 ]
実装: [-0.11643543 0.0802914 ]
デバッグ: [ 0.11005437 -0.018176 ]
AI: [-0.16327941 0.26665992]
機械学習: [-0.46703785 0.09946574]
深層学習: [-0.32870221 0.25412075]
データ分析: [-0.15491634 0.31756677]
人工知能: [-0.29019093 0.23530355]
寿司: [ 0.38669948 -0.05278358]
ラーメン: [ 0.52679815 -0.00760298]
カレー: [0.51998144 0.0546167 ]
ハンバーグ: [0.44496972 0.03363166]
パスタ: [0.55319311 0.10029806]
自動車: [-0.23238473 -0.49313654]
電車: [-0.14845397 -0.57404895]
バス: [ 0.05772 -0.41452748]
飛行機: [-0.22416269 -0.37806025]
自転車: [-0.14682776 -0.50608828]
得られたベクトルをプロットすると、次のような配置になります。
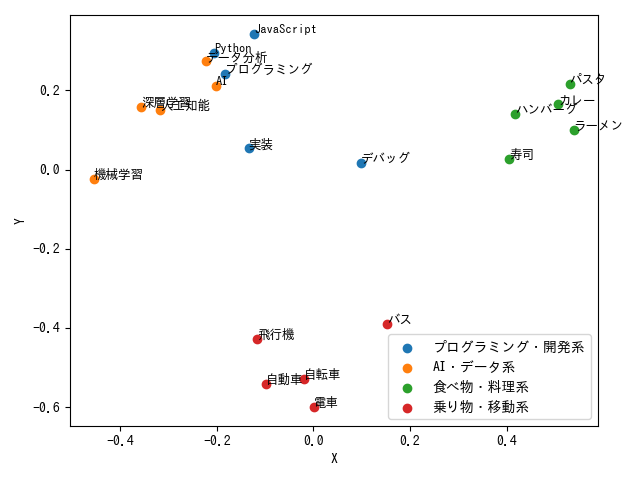
ここで重要なのは次の点です。
単語の表記が似ているかどうかではなく、意味的な近さが反映されていることが分かります。
「エンベディング」という単語を上記と同じようにベクトル化すると、
query_vector = np.array([-0.21509223417701273, 0.12073096051365606])
という値が得られました。
これを使って、類似検索をしてみましょう。
今回は、コサイン類似度という指標を使用します。
詳細な説明は省略しますが、ベクトル同士の類似度を測るときによく使われる指標です。
実装例はこちらです。
import numpy as np
words = [
# 省略
]
vectors_2d = np.array(
[
# 省略
]
)
query_vector = np.array([-0.21509223417701273, 0.12073096051365606])
def cosine_similarity(a: np.ndarray, b: np.ndarray) -> float:
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
similarities = []
for word, vector in zip(words, vectors_2d):
score = cosine_similarity(query_vector, vector)
similarities.append((word, score))
# 類似度の高い順にソート
similarities.sort(key=lambda x: x[1], reverse=True)
# top3 を表示
top3 = similarities[:3]
print("=== クエリに類似した単語トップ3 ===")
for word, score in top3:
print(f"{word}: {score:.4f}")
=== クエリに類似した単語トップ3 ===
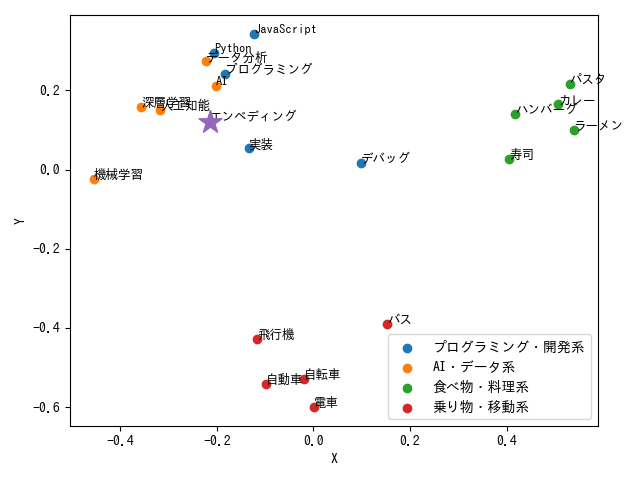
人工知能: 0.9977
深層学習: 0.9958
実装: 0.9911
プロットすると、このようになります。
たしかに、近い単語を取得できてそうですね。
今回のデモでは単語を扱いましたが、文章でも同様にエンベディングを生成できます。
そのため、活用範囲は非常に広く、検索・推薦・チャットボット・マッチングなど、多くの実システムで利用されています。
ここで、弊社が開発したシステムにどのように組み込んでいるかをご紹介します。
弊社が開発した社内ポータル向けAIチャットボットでは、RAG(検索拡張生成)を用いる際に、
といった用途で活用しています。
詳細は以下の事例をご参照ください。
RAG(検索拡張生成)と生成AIを活用したAIチャットボットの開発
弊社のSES案件マッチングシステムでは、
を似たような文章構造に変換したうえでそれぞれをエンベディング化し、意味ベースでマッチングを行っています。
キーワードが完全一致しなくても、内容的に適合度の高い組み合わせを見つけられる点が特徴です。
詳細はこちらをご覧ください。
生成AIによる構造化出力とベクトル検索で、SES案件探索を効率化
ここで、OpenAIとGoogleがリリースしている、代表的なエンベディングモデルを紹介します。
下記2つがよく使用されます。
主な特徴は以下の通りです。
公式ドキュメント
OpenAI Platform > Docs > Vector embeddings
下記がよく使用されます。
主な特徴は以下の通りです。
公式ドキュメント
Gemini API ドキュメント > エンベディング
完全一致検索はシンプルで分かりやすい一方、意味の揺れや表現の違いには弱いという課題があります。
エンベディングを用いることで、
といったメリットを得られます。
「類似検索を実現したい」「検索精度を上げたい」と考えたとき、エンベディングは最初に検討すべき技術の一つと言えるでしょう。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。




