
生成AI関連
Amazon Bedrock Knowledge Base × S3 VectorsでRAGを作って…
CDK を使って Knowledge Base と S3 Vectors を構築し、デプロイした環境を利用しようとしたところ、データソースの同期がすべて失敗するという事象に遭遇しました。以前の記事では、コンソールから Knowledge Base を作成し、そのまま利用した際には問題なく同期できていました。
しかも今回アップロードしたファイルおよびメタデータは、以前の記事で利用したものとまったく同じ内容です。
それにもかかわらず、今回は同期が失敗しました。違いはただ一つです。
本記事では、このエラーをどのように切り分け、最終的にどこに原因があったのかを、実際の検証の流れに沿って整理します。
同期を実行すると、すべてのデータソースがエラーになりました。
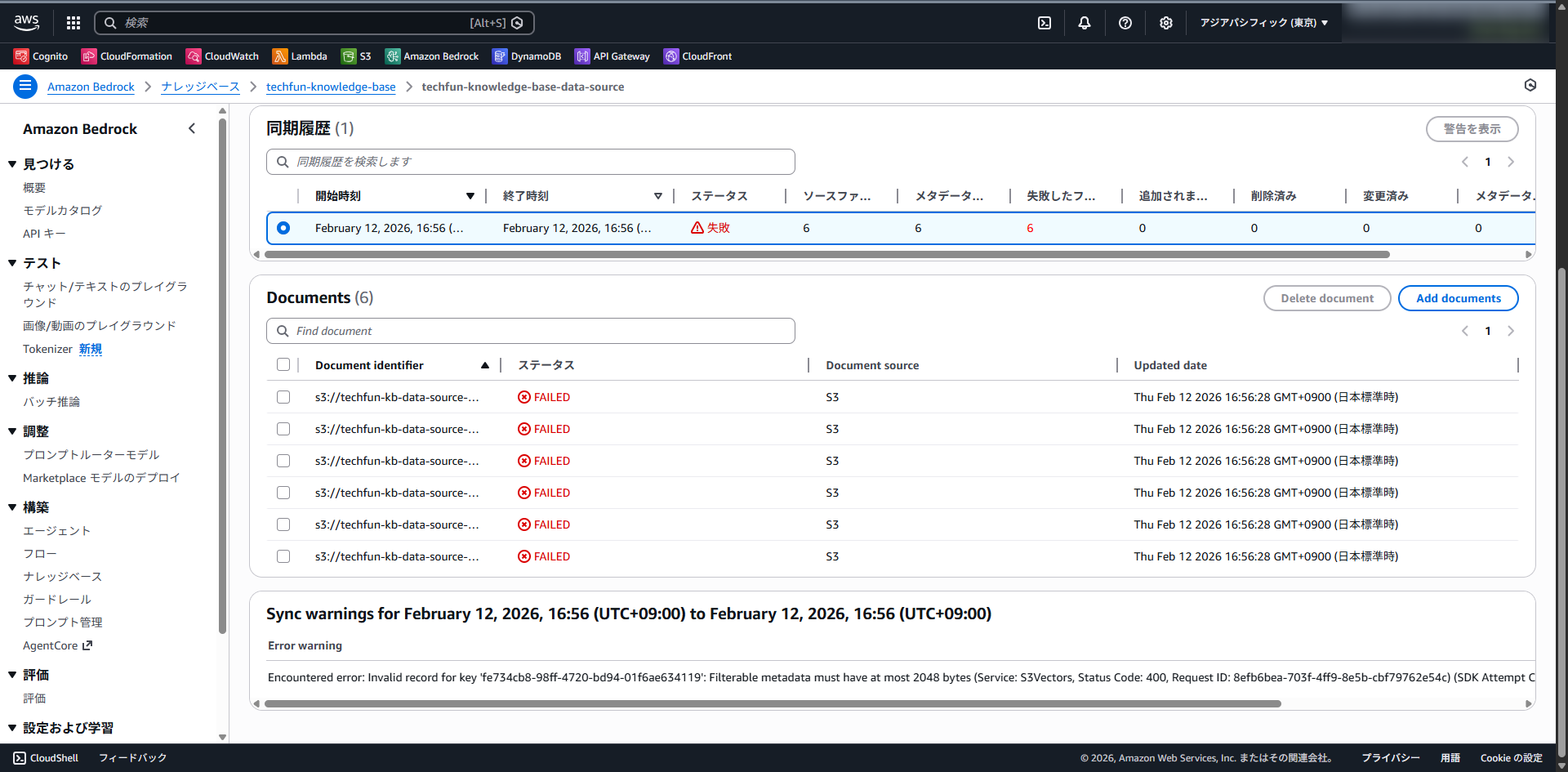
表示されたエラーメッセージは次の通りです。
Encountered error: Invalid record for key 'fe734cb8-98ff-4720-bd94-01f6ae634119': Filterable metadata must have at most 2048 bytes (Service: S3Vectors, Status Code: 400, Request ID: 8efb6bea-703f-4ff9-8e5b-cbf79762e54c) (SDK Attempt Count: 1). Call to Amazon S3 Vectors did not succeed.
エラーコードによると「Filterable metadata must have at most 2048 bytes」とあり、フィルターに使うメタデータ(filterable metadata)は 2KB 以下である必要があることが分かります。
しかし、登録していた metadata は実測で300B 程度でした。一見すると、2KB 制限に抵触する理由は見当たりません。ここから調査を開始しました。
エラーメッセージには metadata と書かれていますが、
といった要素が内部的に影響している可能性も考えられます。そこで、極端に小さなドキュメントを用意して検証しました。
ドキュメント1です。
合言葉は、「犬」です。
{
"metadataAttributes": {
"name": "ドキュメント1",
"version": 1.3,
"year": 2024
}
}
既存データを削除し、このテストデータのみをアップロードして同期を実行します。
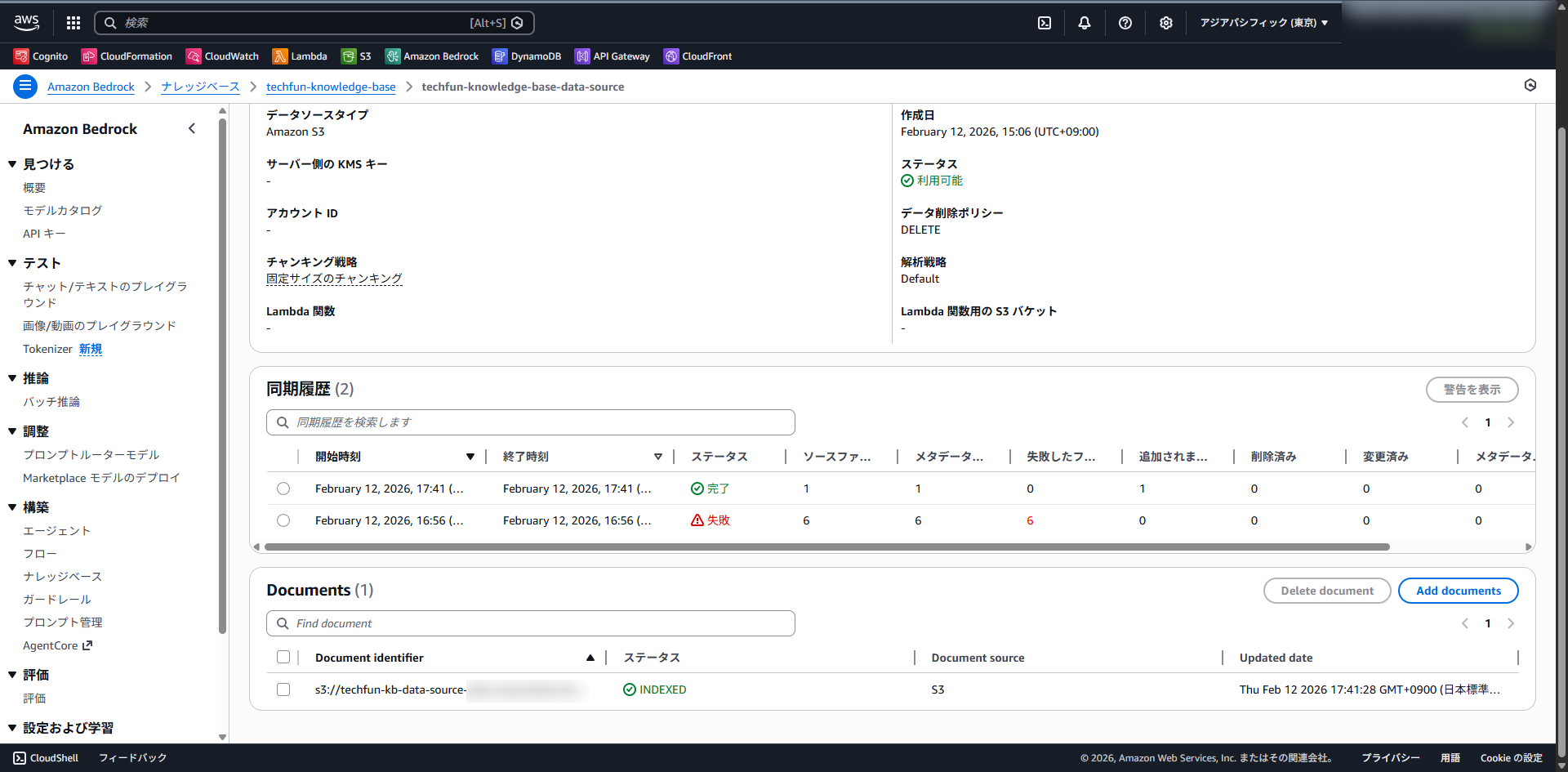
同期は成功しました。
この時点で分かったのは、
ということです。
まだ原因は特定できていませんが、「metadata 単体の問題ではなさそう」という感触が得られました。
次に、Knowledge Base から retrieve を実行し、metadata の中身を確認しました。
import json
import boto3
from dotenv import load_dotenv
load_dotenv()
REGION = "ap-northeast-1" # ご自身のリージョンに置き換えてください
KNOWLEDGE_BASE_ID = "XXXXXXXXXX" # ご自身のKnowledge Base IDに置き換えてください
def make_kb_client():
session = boto3.Session()
return session.client("bedrock-agent-runtime", region_name=REGION)
def retrieve_documents(query: str) -> None:
bedrock_client = make_kb_client()
response = bedrock_client.retrieve(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
retrievalQuery={"text": query},
retrievalConfiguration={
"vectorSearchConfiguration": {
"numberOfResults": 3,
}
},
)
print("----------- retrieve -----------")
print(json.dumps(response, indent=2, ensure_ascii=False))
print("--------------------------------")
if __name__ == "__main__":
retrieve_documents("test")
----------- retrieve -----------
{
"ResponseMetadata": {
(省略)
},
"retrievalResults": [
{
"content": {
"text": "ドキュメント1です。 合言葉は、「犬」です。",
"type": "TEXT"
},
"location": {
"s3Location": {
"uri": "s3://(省略)"
},
"type": "S3"
},
"metadata": {
"name": "ドキュメント1",
"x-amz-bedrock-kb-source-file-modality": "TEXT",
"year": 2024.0,
"version": 1.3,
"x-amz-bedrock-kb-chunk-id": "c8f9c02a-a1b0-431b-a11c-35ff1691e36a",
"x-amz-bedrock-kb-data-source-id": "H4YXHZENRS"
},
"score": 0.5249484777450562
}
]
}
--------------------------------
ここで、自分で設定していない以下のキーが付与されていることが分かります。
つまり、Knowledge Base は内部的にメタデータを自動付与しているということです。ただし、これらは ID やファイル種別といった管理情報であり、ドキュメント本文のサイズには依存しません。そのため、これらが追加されたとしても 2KB を超えるとは考えにくい状況でした。
次に、S3 Vectors から直接ベクトルデータを取得しました。
import json
import boto3
from dotenv import load_dotenv
load_dotenv()
REGION = "ap-northeast-1" # ご自身のリージョンに置き換えてください
VECTOR_BUCKET = "xxxx-xxxxxxxxx-xxxxx" # ご自身のS3 Vectorバケット名に置き換えてください
VECTOR_INDEX_NAME = "yyyy-yyyyyyyyy-yyyyy" # ご自身のS3 Vectorインデックス名に置き換えてください
def get_vectors_with_metadata(limit: int = 5):
client = boto3.client("s3vectors", region_name=REGION)
response = client.list_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=VECTOR_INDEX_NAME,
maxResults=limit,
)
for vector in response.get("vectors", []):
key = vector["key"]
# 実データ取得
item = client.get_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=VECTOR_INDEX_NAME,
keys=[key],
returnData=True,
returnMetadata=True,
)
print(json.dumps(item, indent=2, ensure_ascii=False))
if __name__ == "__main__":
get_vectors_with_metadata()
{
"ResponseMetadata": {
"RequestId": "a9c00bfb-c746-42eb-a557-7e58abc904b4",
"HostId": "",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"date": "Thu, 12 Feb 2026 09:00:11 GMT",
"content-type": "application/json",
"content-length": "22584",
"connection": "keep-alive",
"x-amz-request-id": "a9c00bfb-c746-42eb-a557-7e58abc904b4",
"access-control-allow-origin": "*",
"vary": "origin, access-control-request-method, access-control-request-headers",
"access-control-expose-headers": "*"
},
"RetryAttempts": 0
},
"vectors": [
{
"key": "c8f9c02a-a1b0-431b-a11c-35ff1691e36a",
"data": {
"float32": [
-0.0544898696243763,
(1,024次元、省略)
-0.06755758076906204
]
},
"metadata": {
"version": 1.3,
"x-amz-bedrock-kb-data-source-id": "H4YXHZENRS",
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2026-02-12T08:39:51Z\",\"modifiedDate\":\"2026-02-12T08:39:51Z\",\"source\":{\"sourceLocation\":\"s3://(省略)/ドキュメント1.md\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":null,\"sourceDocumentId\":\"9sOnR6eTCvL7d7hbp62iaQt0A0dvqA1AqZYGjyaIjbauPuGsUG6w/CzDfkL9zyII\",\"additionalMetadata\":null}",
"AMAZON_BEDROCK_TEXT": "ドキュメント1です。 合言葉は、「犬」です。",
"name": "ドキュメント1",
"x-amz-bedrock-kb-source-file-modality": "TEXT",
"year": 2024.0
}
}
]
}
ここで決定的な情報が見つかります。
"AMAZON_BEDROCK_METADATA": "…",
"AMAZON_BEDROCK_TEXT": "ドキュメント1です。 合言葉は、「犬」です。"
AMAZON_BEDROCK_METADATAには、多くの内部利用データ、そしてAMAZON_BEDROCK_TEXT には本文の全文が格納されていました(おそらく、チャンク分割された後の値)。
この時点で初めて、
という仮説にたどり着きました。
公式ドキュメントによると、S3 Vectors には以下の制限があります。
ベクトルあたりのメタデータの合計: 最大 40 KB (フィルタリング可能 + フィルタリング不可)
ベクトルあたりのフィルタリング可能なメタデータ: 最大 2 KB
また、S3 Vectorsのベストプラクティスには、下記のように記載があります。
ベクトルインデックスのフィルタリング不可能なメタデータフィールドの設定
ベクトルインデックスを作成する際は、フィルタリング不可能なメタデータキーとしてフィルタリングを必要としないメタデータフィールドを設定します。例えば、ベクトル埋め込みのテキストチャンクは、参照のみが必要な場合、フィルタリング不可能なメタデータフィールドとして保存します。詳細については、「フィルタリング不可能なメタデータ」を参照してください。
つまり、Knowledge Baseと連携させる場合、自動付与されるメタデータを把握し、自身でフィルタリング不可能なメタデータ(non-filterable metadata)を設定しなければならないのです。
今回の設定では、「チャンクサイズ:3,072 トークン」としていたので、仮に 1文字1バイトとしても2KB を超えてしまいます。全ドキュメントで同期が失敗していた理由は、これが原因である可能性が高いと考えられました。
以前の記事では、まったく同じファイルと metadata を使用していました。
違いは、S3 Vectors Index の作成方法です。
以前の環境の Index 設定を確認すると、次の設定が含まれていました。
import json
import boto3
from dotenv import load_dotenv
load_dotenv()
REGION = "ap-northeast-1" # ご自身のリージョンに置き換えてください
VECTOR_BUCKET = "xxxx-xxxxxxxxx-xxxxx" # ご自身のS3 Vectorバケット名に置き換えてください
VECTOR_INDEX_NAME = "yyyy-yyyyyyyyy-yyyyy" # ご自身のS3 Vectorインデックス名に置き換えてください
def get_vector_index_metadata():
client = boto3.client("s3vectors", region_name=REGION)
response = client.get_index(
vectorBucketName=VECTOR_BUCKET,
indexName=VECTOR_INDEX_NAME,
)
print(json.dumps(response, indent=2, default=str))
if __name__ == "__main__":
get_vector_index_metadata()
{
"ResponseMetadata": {
"RequestId": "91663b82-5b43-449b-a3c4-db78501f1a71",
"HostId": "",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"date": "Thu, 12 Feb 2026 09:19:43 GMT",
"content-type": "application/json",
"content-length": "491",
"connection": "keep-alive",
"x-amz-request-id": "91663b82-5b43-449b-a3c4-db78501f1a71",
"access-control-allow-origin": "*",
"vary": "origin, access-control-request-method, access-control-request-headers",
"access-control-expose-headers": "*"
},
"RetryAttempts": 0
},
"index": {
"vectorBucketName": "bedrock-knowledge-base-t3s18v",
"indexName": "bedrock-knowledge-base-default-index",
"indexArn": "arn:aws:s3vectors:(省略)",
"creationTime": "2026-01-23 14:34:43+09:00",
"dataType": "float32",
"dimension": 3072,
"distanceMetric": "euclidean",
"metadataConfiguration": {
"nonFilterableMetadataKeys": [
"AMAZON_BEDROCK_TEXT",
"AMAZON_BEDROCK_METADATA"
]
},
"encryptionConfiguration": {
"sseType": "AES256"
}
}
}
たしかに、nonFilterableMetadataKeysの設定が存在しています。一方、エラーが発生していた環境では、nonFilterableMetadataKeysが空になっていました。
ここで、同期エラーの原因が特定できました。
CDK で Index を作成する際には、以下のようにnonFilterableMetadataKeysを追加します。
const vectorIndex = new s3vectors.CfnIndex(this, "TestVectorIndex", {
vectorBucketArn: vectorBucket.attrVectorBucketArn,
indexName: vectorIndexName,
dataType: "float32",
dimension: 1024,
distanceMetric: "cosine",
metadataConfiguration: {
nonFilterableMetadataKeys: [
"AMAZON_BEDROCK_TEXT",
"AMAZON_BEDROCK_METADATA",
],
},
});
CDKの再デプロイ後、Index 設定を確認し、再度同期を実行します。
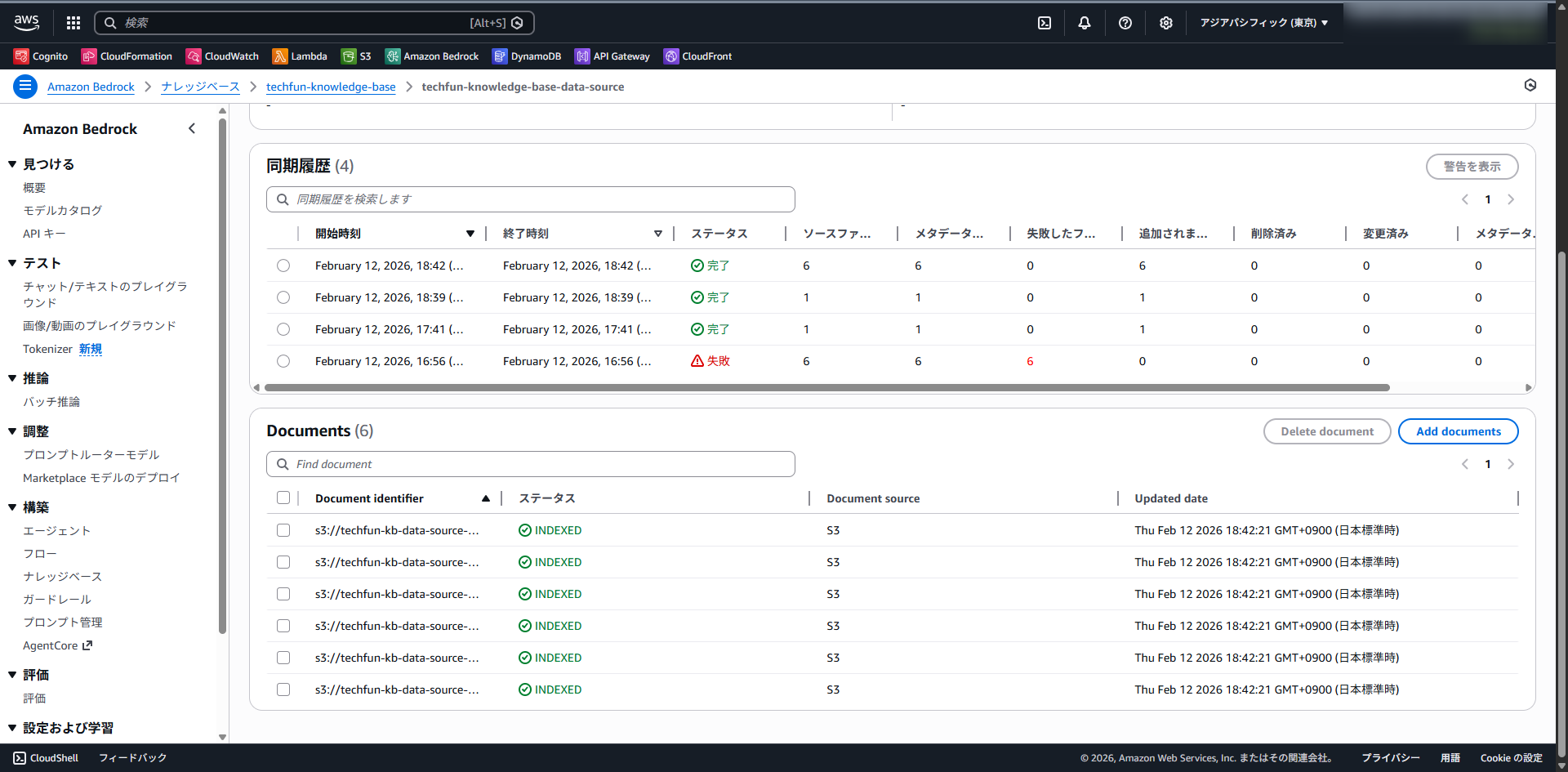
無事、同期は成功しました。
今回の事象から得られたことは、次の通りです。
IaC でインフラを構築する場合、「コンソールでは簡単に作れたから、CDKでも特に意識しなくて問題ないはず」という前提は成立しないことがあります。デフォルト設定の違いが、思わぬ挙動差につながることもあるため、仕様の確認と設定値の明示は重要です。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。



