
生成AI関連
生成AIの精度を評価するための指標入門(2クラス分類編)
「AIを入れたい」「AIに予測させたい」「AIで検品の精度を上げたい」
この相談、ここ数年で本当に増えました。
ただ、現場でよく起きるのが「AI」という言葉が大きすぎて、会話が噛み合わない問題です。同じ「AI」という単語を使っているのに、頭の中で想像しているものがバラバラなんですね。
発注側が「AIでなんとかして」と言い、受注側が「(どのAIの話だろう…)はい、がんばります」と答える。そして現場では、何ができるのか分からないまま進んで、後で炎上する。これ、本当によく見ます。
この記事では、AGI・AI・生成AI・機械学習・統計を実際に手を動かしながら区別できるレベルで整理します。コード例も交えて「なるほど、こう違うのか」を体感してもらえる内容を目指しました。
最初に、これらの言葉がどういう関係にあるのかを図で示します。
ポイントは2つです。
では、それぞれを具体的に見ていきましょう。
統計は、データを集めて「何が起きているか」を把握するための手法です。
たとえば「先月の売上はいくらだった?」「どの曜日が一番売れる?」「AとBで差があるのは偶然?」といった問いに答えます。
よくある使い方:売上の月別推移、相関分析、A/Bテストの判定
よくある勘違い:Excelで集計しただけなのに「AIが予測した」と言ってしまう
機械学習は、過去のデータを渡すと、そこからパターンを見つけ出し、新しいデータに対して予測や分類を行います。
たとえば「過去3年分の売上データを渡すと、来月の売上を予測する数式を自動で作ってくれる」というイメージです。人間がルールを書くのではなく、データから機械がルールを見つけ出すところがポイントです。
よくある使い方:需要予測、異常検知、画像分類(検品など)
よくある勘違い:データがなくても学習できると思ってしまう(データがないと何も始まらない)
生成AIは、機械学習の一種で、文章・画像・音声などを「生成」することに特化しています。ChatGPTやGemini、Claudeがこれに当たります。
大量のテキストから「次に来そうな言葉」を学習しているので、自然な文章を作るのが得意です。ただし、「事実かどうか」を判断する仕組みは持っていません。
よくある使い方:要約、メールの下書き、社内QAの一次回答、アイデア出し
よくある勘違い:事実を保証してくれる、間違わないと思ってしまう(必ず人間が確認する前提で使う)
AIは非常に広い言葉で、機械学習も生成AIも、さらにはルールベースの自動判定(if-thenで動くもの)も含みます。
「AIで〇〇したい」と言われたとき、話し手が何を想像しているかはバラバラです。だから最初に「どのAIの話ですか?」と確認することが大事です。
よくある勘違い:AI=生成AI(ChatGPT的なもの)だと思う
AGIは、特定のタスクではなく、人間のようにあらゆる知的作業をこなせる汎用的な知能を指します。
現時点では研究目標であり、実用化されたものはありません。「AGIが来たら全部自動化できる」という期待はまだ早いです。
よくある勘違い:いま使っているAIがAGIだと思ってしまう
「AIで〇〇したい」を、もう少しだけ具体化してみます。
| やりたいこと | まず検討する技術 | 補足 |
|---|---|---|
| 資料やメールをいい感じに書いてほしい | 生成AI | 下書き→人が最終確認が堅い |
| 長い文章を短くまとめたい | 生成AI | 要約は得意。ただし事実確認は人が行う |
| 過去データの傾向を知りたい | 統計 | まず可視化・集計で十分なことが多い |
| 来月の需要を予測したい | 機械学習 / 統計 | データと評価方法がないと始まらない |
| 画像で不良品を見つけたい | 機械学習(画像認識) | 不良の定義と正解データ作りが一番大変 |
| ルール通りに処理を自動化したい | ルール / RPA | AIじゃない方が安い・速いことも多い |
| 何でも判断して全部自動化したい | AGI(まだない) | まず業務を分解して"人の判断"を残す |
「来月の売上を予測したい」という相談を受けたとき、いきなり機械学習に飛びつく必要はありません。まずは統計的な可視化で「何が起きているか」を把握するだけで、十分な判断材料になることが多いです。
架空のECサイトの月別売上データを使います。
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
matplotlib.rcParams["font.family"] = "Noto Sans CJK JP"
# サンプルデータ:24ヶ月分の売上
data = {
'年月': pd.date_range('2022-12-01', periods=24, freq='MS'),
'売上': [
120, 115, 130, 145, 160, 180, # 2023年前半
175, 190, 210, 195, 220, 280, # 2023年後半(12月は繁忙期)
135, 125, 145, 155, 175, 195, # 2024年前半
185, 205, 225, 210, 240, 310 # 2024年後半
]
}
df = pd.DataFrame(data)
df['売上'] = df['売上'] * 10000 # 万円単位に
print(df.tail(6))
出力:
年月 売上
18 2024-07-31 1850000
19 2024-08-31 2050000
20 2024-09-30 2250000
21 2024-10-31 2100000
22 2024-11-30 2400000
23 2024-12-31 3100000
plt.figure(figsize=(12, 5))
plt.plot(df['年月'], df['売上'] / 10000, marker='o')
plt.title('月別売上の推移')
plt.xlabel('年月')
plt.ylabel('売上(万円)')
plt.grid(True, alpha=0.3)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
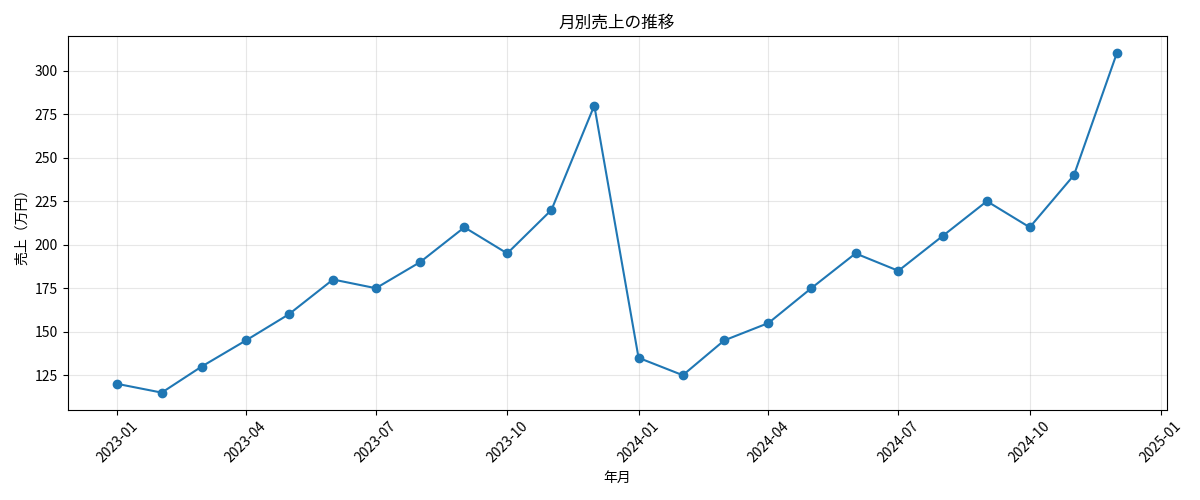
このグラフを見るだけで、以下のことが分かります。
「来月どうなる?」の答えは、複雑なAIモデルを作らなくても「去年の同月 × 今年の成長率」でそこそこの見当がつきます。
# 簡易的な予測:去年同月 × 成長率
growth_rate = df[df['年月'].dt.year == 2024]['売上'].mean() / df[df['年月'].dt.year == 2023]['売上'].mean()
print(f"前年比成長率: {growth_rate:.1%}")
# 2025年1月の予測(2024年1月 × 成長率)
jan_2024 = 1350000
jan_2025_estimate = jan_2024 * growth_rate
print(f"2025年1月の予測: {jan_2025_estimate/10000:.0f}万円")
出力:
前年比成長率: 108.7%
2025年1月の予測: 147万円
ポイント:統計的な集計と可視化だけで「だいたいこのくらい」が分かるケースは多いです。いきなり機械学習に飛びつく前に、まずデータを見ることが大事です。
このような統計分析を生成AIの力を借りて効率的に進めることも、もちろん可能です。ただし、前述のとおりその事実確認は人間が行う必要があります。そのため、統計学の知識を身に着けることから避けることはできません。
統計が「傾向をつかむ」のに対し、機械学習は「パターンを学んで、新しいデータに対して予測する」ことができます。
同じ売上データを使って、違いを体感してみましょう。
機械学習モデルに「何月か」「何年目か」を教えるための特徴量を作ります。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import numpy as np
# 特徴量を作成
df['月'] = df['年月'].dt.month
df['年目'] = (df['年月'].dt.year - 2023) + 1 # 2023年=1年目, 2024年=2年目
# 12月フラグ(繁忙期)
df['12月フラグ'] = (df['月'] == 12).astype(int)
print(df[['年月', '売上', '月', '年目', '12月フラグ']].tail(6))
出力:
年月 売上 月 年目 12月フラグ
18 2024-07-31 1850000 7 2 0
19 2024-08-31 2050000 8 2 0
20 2024-09-30 2250000 9 2 0
21 2024-10-31 2100000 10 2 0
22 2024-11-30 2400000 11 2 0
23 2024-12-31 3100000 12 2 1
# 特徴量と目的変数
X = df[['月', '年目', '12月フラグ']]
y = df['売上']
# モデルを学習
model = LinearRegression()
model.fit(X, y)
# 学習したパターンを確認
print("学習したパターン(係数):")
for feature, coef in zip(X.columns, model.coef_):
print(f" {feature}: {coef:+.0f}円")
print(f" 基準値(切片): {model.intercept_:.0f}円")
出力:
学習したパターン(係数):
月: +108182円
年目: +154167円
12月フラグ: +557727円
基準値(切片): 862841円
この結果の意味:
# 2025年1月を予測(月=1, 年目=3, 12月フラグ=0)
future = pd.DataFrame({
'月': [1],
'年目': [3], # 2025年 = 3年目
'12月フラグ': [0]
})
prediction = model.predict(future)[0]
print(f"2025年1月の予測: {prediction/10000:.0f}万円")
出力:
2025年1月の予測: 143万円
| 観点 | 統計(デモ1) | 機械学習(デモ2) |
|---|---|---|
| やったこと | 前年比の成長率を計算 | データからパターンを自動で学習 |
| 予測の仕組み | 人間がルールを決めた | 機械がルールを見つけた |
| 2025年1月予測 | 147万円 | 143万円 |
| 柔軟性 | ルールを変えるには人が修正 | データが増えれば再学習できる |
ポイント:機械学習は「人間がルールを書く」のではなく、「データからパターンを見つけ出す」ところが本質的な違いです。データが増えれば増えるほど、より精度の高い予測ができるようになります。
生成AIは、統計や機械学習とは全く違う役割を持っています。数値を予測するのではなく、「文章や画像を生成する」ことが得意です。
長い文章を渡して、要約させてみましょう。
from openai import OpenAI
client = OpenAI() # 環境変数 OPENAI_API_KEY を使用
# 要約したい文章(議事録の一部を想定)
long_text = """
本日の会議では、来期の販売戦略について議論しました。
田中部長から、オンライン販売の強化が提案されました。
具体的には、ECサイトのUI改善、SNS広告の増額、
インフルエンサーマーケティングの導入が挙げられました。
佐藤課長からは、実店舗との連携強化の重要性が指摘され、
オムニチャネル戦略の必要性について議論がありました。
予算については、オンライン施策に全体の60%、
実店舗連携に40%を配分する方向で合意しました。
次回会議までに各施策の詳細計画を作成することになりました。
"""
response = client.responses.create(
model="gpt-5.2",
max_output_tokens=300,
input=f"以下の議事録を3行で要約してください。\n\n{long_text}",
)
print("【生成AIによる要約】")
print(response.output_text)
出力例:
【生成AIによる要約】
来期の販売戦略として、オンライン販売強化と実店舗連携(オムニチャネル)について議論した。
オンライン施策はECサイトUI改善、SNS広告増額、インフルエンサーマーケ導入を進める。
予算はオンライン60%・実店舗連携40%で合意し、次回までに各施策の詳細計画を作成する。
# 同じ質問をもう一度
response_repeat = client.responses.create(
model="gpt-5.2",
max_output_tokens=300,
input=f"以下の議事録を3行で要約してください。\n\n{long_text}",
)
print("\n【2回目の要約】")
print(response_repeat.output_text)
出力例:
【2回目の要約】
来期の販売戦略として、オンライン販売強化(ECサイトUI改善・SNS広告増額・インフルエンサー活用)が提案された。
実店舗との連携を強めるオムニチャネル戦略の必要性について議論した。
予算配分はオンライン60%・実店舗連携40%で合意し、次回までに各施策の詳細計画を作成する。
注目すべき点:同じ質問をしても、毎回少しずつ違う表現になります。これが「生成」の特徴です。
| 技術 | 入力 | 出力 | 得意なこと |
|---|---|---|---|
| 統計 | データ | 傾向・指標 | 何が起きているかを把握する |
| 機械学習 | データ | 予測値・分類 | 新しいデータに対して当てにいく |
| 生成AI | 指示(プロンプト) | 文章・画像 | 下書き・たたき台を高速で作る |
ポイント:生成AIは要約、メール作成、アイデア出しは得意ですが、事実を保証する機能は持っていません。必ず人間が最終確認する前提で使います。
「AIで精度を上げたい」という相談は多いですが、現場ではだいたい次のどれかが混ざっています。
改善するには、まず「今どのくらいか」を知る必要があります。
❌ 「AIで精度を上げたい」
⭕ 「今の検品ミス率は3%。これを1%以下にしたい」
機械学習は「正解付きのデータ」から学習します。正解がないと、学習も評価もできません。
❌ 「画像で不良品を検出したい」(不良品の画像が10枚しかない)
⭕ 「不良品の画像を1000枚、正常品の画像を5000枚用意した」
「精度」という言葉は便利すぎて、何を指しているか分からないことが多いです。
| 言葉 | 実際に指しているもの | 例 |
|---|---|---|
| モデルの精度 | 予測の正解率 | 100件中95件当たった → 95% |
| 検品の精度 | 不良を見逃さない率 | 不良100件中98件検出 → 98% |
| 業務品質 | やり直しが減った | クレーム件数が月10件→3件 |
大事なこと:AIは、何もしなくても勝手に精度を上げてくれる装置ではありません。精度を上げるには、データ収集、正解ラベル作成、評価方法の設計、運用体制の構築がセットで必要です。
誤解されがちですが、現場で一番効果が出るのは、精度向上よりも定型作業の高速化です。
この形ができると、結果として:
という形で、業務全体の品質が上がることがあります。
インタビューや打ち合わせの文字起こしは手間がかかりますよね。生成AIを活用することでこれを改善できる可能性があります。
作業者A:文字起こし(1時間の音声 → 約4時間)
作業者B:ダブルチェック(約1.5時間)
──────────────────────────────────────
合計:5.5時間/件
品質は出ますが、維持コストが重いです。
AI:文字起こし一次作成(1時間の音声 → 約10分)
作業者A:確認・修正(固有名詞、数字、ニュアンス)→ 約1時間
怪しい箇所だけ音声に戻って確定
──────────────────────────────────────
合計:1.2時間/件(約80%削減)
| 指標 | Before | After | 改善率 |
|---|---|---|---|
| 1件あたりの工数 | 5.5時間 | 1.2時間 | 78%削減 |
| 月間処理件数 | 8件 | 35件 | 4.4倍 |
| 人件費(月あたり) | 44時間分 | 42時間分 | 微減(件数増加分) |
| 品質(誤字脱字率) | 0.5% | 0.8% | 微増だが許容範囲 |
ポイント:品質は若干下がりましたが、それ以上に処理件数が増え、全体としてはプラスになります。最初から「完璧な精度」を求めず、「人のチェック込みで実用になるか」で判断したのが成功の鍵になります。
本来の目的:
途中から「AIを導入した」という事実づくりが目的化すると、手段の議論しか残らず、だいたい辛くなります。現場は新たなシステムが加わり、かえって煩雑になる可能性もあります。
「精度を上げたい」と言った瞬間、話が止まります。どの精度を上げたいのかが決まらないまま進むと、評価もできません。精度に逃げずに、具体的な評価指標をどうしていきたいかで語るようにしましょう。
「決まったルールで処理できる」なら、Excelの関数、マクロ、RPA、既存システムの改修で終わることも多いです。
相談を受ける側が最初に確認している質問です。これに答えられると、生成AI導入プロジェクトの成功率が上がります。
| # | 質問 | 確認したいこと |
|---|---|---|
| 1 | 何の作業を減らしたい? | 人の時間、どこが重いか |
| 2 | いまのやり方の"基準値"は? | 時間、件数、ミス率 |
| 3 | 間違えると何が困る? | 損失、リスク、責任の所在 |
| 4 | AIの出力は、誰が最終確認する? | チェック体制 |
| 5 | 成功をどう判断する? | 例:月○時間削減、一次対応の平均時間を○%短縮 |
「AI」という大きすぎる言葉を、統計/機械学習/生成AI/AI(総称)/AGIに分解して、できること・できないこと・必要な前提を解説しました。
| 観点 | 説明 |
|---|---|
| 統計 | 「何が起きているか」を説明し、意思決定の土台(基準値・傾向・差の有無)を作る技術。 |
| 機械学習 | 「当てにいく」技術だが、正解データと評価設計がないと始まらない。 |
| 生成AI | 「下書き生成」が強みで、人の確認を前提にすると現場の生産性を大きく押し上げられる一方、事実保証の装置ではない。 |
| AI | これらを含む総称で、会話が噛み合わない最大要因になりやすい。 |
| AGI | 「何でもできる知能」の研究目標で、現場の要件を丸ごと任せる前提に置くと期待値が破綻する。 |
だから「AIで精度を上げたい」をそのまま進めるのではなく、まず(1)何を減らすか (2)現状の基準値 (3)失敗コスト (4)最終責任者 (5)成功指標を言語化し、技術選定と運用設計に落とすのが良いでしょう。実務で堅い出発点は、統計で現状を見える化 → 生成AIで定型作業の下書きを高速化(人がチェック) → 効果とデータが揃ったところで機械学習を検討。
この順で進めると、期待値をコントロールしながら成果が出るAI活用に近づけます。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。



