生成AIを使っていると、temperature、top_p、top_k といったパラメータを目にする機会は多いものの、「雰囲気で設定している」「正直よく分かっていない」というケースも少なくありません。
近年の生成AI(特に推論型)では、
といった設計になってきており、人間が細かくチューニングする場面は確実に減りつつあります。
一方で、これらの仕組みを理解しているかどうかで、
といった挙動の理解度は大きく変わります。
本記事では、生成AIの仕組みに触れながら、数式は使わずPython(numpy)による再現コードを使って生成AIがどのようにテキストを生成しているのかを見ていきましょう。
※ 実装は、pytorchを使ったほうが圧倒的に楽に実装できますが、わかりやすさを重視しnumpyを使用します。
※ また、各社によって実装の仕方に差異があるため、参考程度とお考えください。
生成AIは文章を一気に生成しているわけではなく、1トークンずつ「次に何を出すか」を選択しています。
※ トークンとは、生成AIが文章を理解・生成する際に使う情報の最小単位のことです。
ではどのように選んでいるのでしょうか?まずはシンプルな例を考えてみます。
たとえば、お正月らしく次の文を考えてみます。
「おせちの具材といえば」
この続きとして、生成AIのモデル内部では次のような候補(tokens)とスコア(logitsといいます)が並んでいると考えられます。
(説明用に極端に簡略化しています。また、具材のチョイスはAIによるものです。)
import numpy as np
# トークンの候補(簡略版。実際には数万~数十万トークンの候補が並ぶ)
tokens = ["黒豆", "数の子", "伊達巻", "昆布巻き", "ハンバーグ"]
logits = np.array([2.0, 1.3, 1.0, 0.4, -1.5])
実際のモデルでは、このtokens(トークン候補)が数万~数十万個ほど存在しています。
また、トークンは実際にはもっと細かい単位ですが、わかりやすさを重視し1単語としています。
logitsはそのままでは使われず、softmaxという操作によって確率に変換されます。
softmaxとは、下記のような関数で表されます。
def softmax(x):
exp_x = np.exp(x - np.max(x))
return exp_x / exp_x.sum()
probs = softmax(logits) # 確率分布を生成
出力は次のようになり、tokensの各要素の生成確率が並びます。つまりsoftmaxは、合計を1にすることで、数字→確率に変換してくれます。
probs=array([0.47697211, 0.23685734, 0.17546823, 0.09629901, 0.01440331])
ここで少しsoftmaxについて補足します。なにがsoftかといいますと、
という意味があります。
hardに対してsoftという名前になっているのは、この挙動の違いからです。
softmax によって、「一番大きい値以外の候補も、確率はゼロではない」という状態が作られます。
※ softmax の実装では、数値安定性のために x – max(x) を引いてから exp を取る手法が一般的です。本記事では、この数値安定化を考慮した実装を用いています。
確率が得られた後、生成では確率分布に基づいてランダムに1つ選択されます。
例えばこのような操作です。
choice = np.random.choice(tokens, p=probs)
print(f"{choice=}")
これにより、
という、自然な揺らぎが生まれます。
ここで、テキストの生成に関わる3つの代表的なパラメータを見ていきましょう。
これらを変更することで、生成AIの出力のクセが変化していきます。
temperature は、
確率分布の鋭さを調節する
パラメータです。
softmax の前に logits を割ることで確率分布の形を変える係数として作用します。
def softmax_with_temperature(logits, temperature):
adjusted = logits / temperature
return softmax(adjusted)
probs = softmax_with_temperature(logits, 2.0)
print(f"{probs=}")
probs=array([0.34079427, 0.24015366, 0.20670217, 0.15312874, 0.05922116])
温度による確率分布の違いはこのようになります。
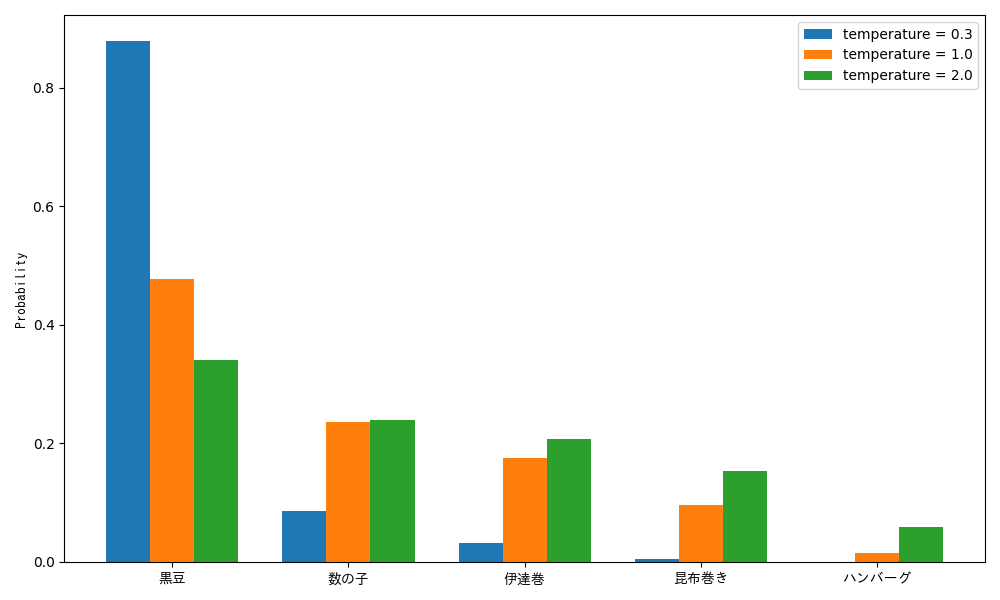
temperature = 0.0 は理論的には割り算できないため、実装上は argmax 相当の挙動になることが多いです。
筆者が社内アプリで temperature = 0.0 を指定し、Structured Output(構造化出力)生成を行っていた際、
という問題が発生しました。
これはtemperature = 0.0(つまり決定的)であるため、何度リトライしても同じ失敗パターンを繰り返すことになります。
決定的すぎる生成は、安全とは限らない
これが temperature = 0.0 が非推奨とされる理由の一つです。
Gemini 3でも非推奨とされています。
注: Gemini 3 モデルを使用する場合は、temperature をデフォルト値の 1.0 に維持することを強くおすすめします。温度を変更する(1.0 未満に設定する)と、特に複雑な数学的タスクや推論タスクで、ループやパフォーマンスの低下などの予期しない動作が発生する可能性があります。
top_p は、
確率の高い順に足し上げ、合計が p (0.0 ~ 1.0) を超えるまで候補を残す
という方法です。
という特徴があります。
長くなるため実装は割愛しますが、例えばp = 0.9で実施した例を見てみましょう。
例えば、temperature = 1.0で実行した結果が下記のようになったとします。
probs=array([0.47697211, 0.23685734, 0.17546823, 0.09629901, 0.01440331])
これを、top_pの考え方に当てはめると、確率の高い順に足し上げた結果、4個目の確率を足したところで0.9を超えることになります。
したがって、p = 0.9の結果は下記のようになります(全体の和が1となるように調整済み)。
probs=array([0.48394248,0.24031872,0.17803249,0.0977063,0. ])
top_k は、
確率(または logits)が高い上位 k (正の整数) 個のトークンのみを選択する
という手法です。
下記はtop_k = 3の際の実行例です。
def kth_largest(values: np.ndarray, k: int) -> float:
"""配列の中で大きい順に k 番目の値を返す"""
if k <= 0 or k > values.size:
raise ValueError("k は 1〜配列長の範囲で指定してください")
# 全体をソートせずに k 番目の値だけ取得する
return np.partition(values, -k)[-k]
threshold = kth_largest(logits, 3)
# しきい値未満の logits を -inf にマスクする
masked_logits = np.where(
logits >= threshold,
logits,
-np.inf,
)
probs = softmax_with_temperature(masked_logits, 1.0)
print(f"{probs=}")
probs=array([0.53634696, 0.26634202, 0.19731102, 0. , 0. ])
このように、logitsの大きかった3つのみが値を持ち、残りは0となりました。
この中から確率的にトークンを選択するのが、top_kの仕組みです。
※ 数学の話になるため詳しくは触れませんが、不要なトークンのlogitsをマイナス無限にしてからsoftmaxを行うと、そのトークンの確率は0となります。
ここでは Gemini を使って、temperature = 0.0とデフォルト設定で複数回生成したときの挙動を比較します。
ソースコードは下記を用いました。
from dotenv import load_dotenv
from google import genai
load_dotenv()
vertex_client = genai.Client()
res = vertex_client.models.generate_content(
model="gemini-2.5-flash",
contents="こんにちは!おせちに入ってる具、1つ選ぶとしたら何を選びますか?",
config={
"temperature": 0.0, # デフォルトの場合はこちらをコメントアウト
"thinking_config": {"thinking_budget": 0},
},
)
print(res.text)
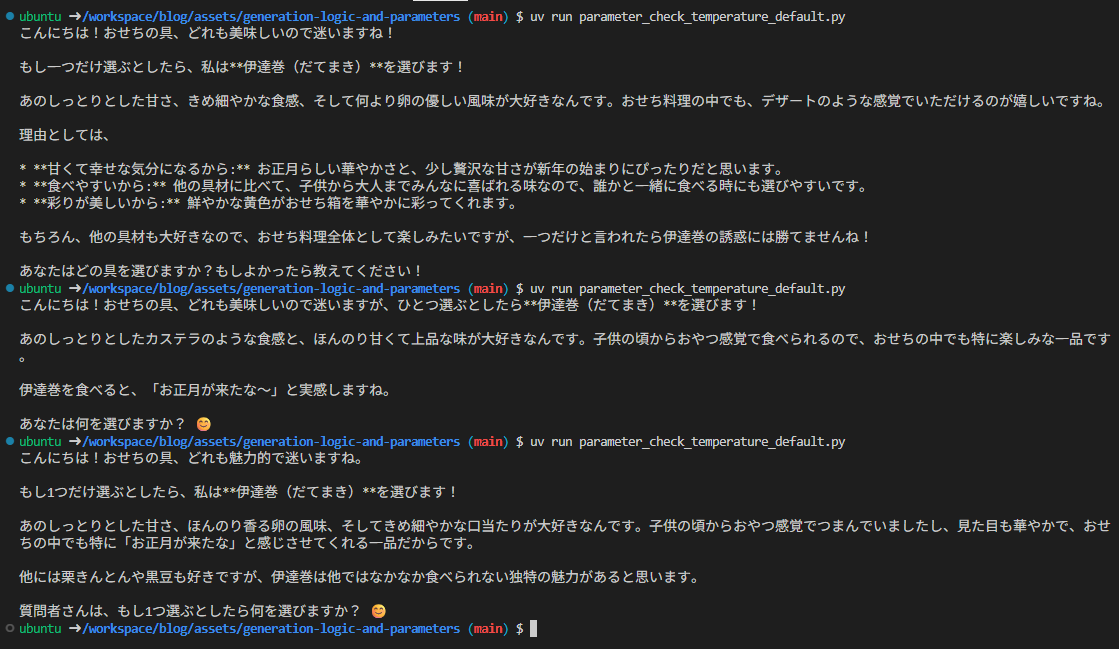
毎回内容が変わっていますね。
このように、毎回少し違った意見を得ることが出来ます。
これは、独創的なアイデアが生まれやすいため、創造性が重要となるタスク(アイデアの考案など)に向いています。

このように、同じ文言での回答が得られます。これは、再現性が欲しいタスクに向いています。
ただし、下記の注意は必要です。
まずは先述の通り、1度エラーがでてしまうと、プロンプトを変更しない限り解消が難しいこと。
そしてもう一つが、必ず同じ回答が得られるわけではないことです。
AI側の実装の仕方だったり、logits(各トークンのスコア)の段階で値が同じだと、スコアが同じトークンがランダムで選ばれることになるため、回答に若干の差異が生まれることがあります。
まとめると、以下のようになります。
温度の違いが、挙動として明確に確認できましたね。
最後に、GoogleとOpenAIを例に、各種パラメータがどのように扱われているか確認してみましょう。
Geminiは、Gemini 2.0以降は下記のようになっており、top_kのみ自身で設定ができなくなっています。
- Temperature: 0.0~2.0(デフォルトは 1.0)
- topP: 0.0~1.0(デフォルトは 0.95)
- topK: 64(固定)
OpenAIは、gpt-5, gpt-5-mini, gpt-5-nanoでは何も設定できず、gpt-5.2で推論を行わない場合にのみ設定ができるようになっています。
また、top_kについては言及されていませんでした。
GPT-5.2 parameter compatibility
The following parameters are only supported when using GPT-5.2 with reasoning effort set to none:
- temperature
- top_p
- logprobs
Requests to GPT-5.2 or GPT-5.1 with any other reasoning effort setting, or to older GPT-5 models (e.g., gpt-5, gpt-5-mini, gpt-5-nano) that include these fields will raise an error.
今回は生成AIのテキスト生成の仕組みと、それに関わる3つのパラメータを紹介しました。
生成AIの API では、パラメータを直接触れなくなりつつあります。
しかし、設定できなくなっていってるだけであって、なくなっているわけではありません。
これらはテキスト生成のしくみとパラメータを理解しておくことで、原因を考えやすくなります。
今後は生成AIを「魔法」としてではなく、確率モデルとして捉える視点を持つことを意識していきましょう。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。

