
生成AI関連
コーディングエージェントを実務でどう使う?社内勉強会で見えたポイント
「AIが設計書を書いてくれるなら、もう人間が書く必要はないのでは?」
生成AIを使った開発が当たり前になってくると、こんな声が出てきます。実際、AIはある程度の情報さえあれば、要件定義書や設計書の草案をあっという間に出力してくれます。では、設計書は不要になるのでしょうか。
答えは、「設計書は不要にならないが、設計書に何を書くかは変わる」です。
本質的な問いはこうです。
これが生成AI時代に求められる設計書の考え方です。
本記事では、次の順で整理します。
まず、設計書がそもそも何のために存在するのかを整理しましょう。「実装のメモ」という認識で設計書を扱うと、書くべきものと削ってよいものの判断を誤ります。設計書には、より根本的な4つの役割があります。
| 役割 | 内容 | 具体例 |
|---|---|---|
| 関係者の認識合わせ | 開発者・PO・ステークホルダーが「同じものを作っている」ことを確認する | 「ログイン後に表示されるのはダッシュボードか、マイページか」を仕様書で合意する |
| 実装前の論点整理 | コードを書く前に「何が決まっていて、何が未決定か」を明確にする | 「認証方式はJWTかセッションCookieか」を設計フェーズで決定しておく |
| 重要な判断理由の記録 | なぜそのアーキテクチャや方式を選んだかを残す | 「PostgreSQLを採用した理由は、JSONBによる柔軟なスキーマ拡張と既存インフラとの親和性」 |
| 保守時の文脈継承 | 担当者が変わっても、過去の判断や制約が参照できる状態にする | 「外部APIのタイムアウトを5秒に設定している理由は、SLAの要件から来ている」 |
この4つの役割は、生成AI時代においても変わりません。むしろ、AIを活用した開発では「なぜそうなっているのか」の背景が曖昧なまま実装が進みやすく、保守時の文脈継承の価値が増しているとも言えます。
NISTのセキュアソフトウェア開発フレームワーク(SP 800-218)でも、組織レベルでセキュア開発の要件を定義・共有すること(PO.1)や、コードを不正アクセスや改ざんから保護すること(PS.1)が整理されています。要するに、安全で再現可能な開発実務は、個人の勘や経験に閉じず、組織のプロセスとして記録・継承されるべきだということです。これは設計書一般の役割とも一致しています。
設計書の4つの役割を踏まえた上で、生成AIの特性を見てみましょう。AIが得意な領域と苦手な領域を正しく把握することが、「何を書くか・書かないか」の判断基準になります。
| カテゴリ | 具体例 |
|---|---|
| 文章化・整形 | 箇条書きのメモを読みやすい文章に整える |
| 要約 | 長い議事録から決定事項だけを抽出する |
| 叩き台作成 | 「REST APIの認証仕様」からテンプレートを生成する |
| 既存文書の再構成 | 散在するドキュメントをまとめ直す |
| コードからの逆生成 | 既存コードを読んで仕様書の草案を出す |
これらは、従来「重い設計書」が担っていた機能の多くです。arc42 も、アーキテクチャ文書はステークホルダーが本当に知る必要がある情報に絞り、プロジェクトに応じて調整して使う前提のテンプレートとして整理しています。AIが生成できる情報を人間が手間をかけて維持する必要性は下がっています。
一方で、生成AIが自動的には埋められない情報があります。これが設計書に残す価値がある情報です。
| カテゴリ | 具体例 |
|---|---|
| 要件の意図・背景 | 「なぜその機能が必要か」「どのビジネス課題を解くか」 |
| 設計判断の理由 | 「なぜAではなくBを選んだか」 |
| 採用しなかった代替案 | 「SessionCookieを不採用にした理由」 |
| トレードオフの記録 | 「パフォーマンスより整合性を優先した根拠」 |
| 品質要求 | 「レスポンス200ms以内」「99.9%可用性」 |
| 外部との約束 | 「APIの後方互換性を3バージョン保証する」 |
| 承認やレビューの根拠 | 「セキュリティレビューでこの制約が追加された理由」 |
これらは、AIが文章を上手に生成できても、合意・責任・判断の根拠を代替することはできません。人間が設計書に残すべきなのは「きれいな説明文」ではなく、「後から説明責任を果たせる記録」です。
上記の整理をまとめると、次のように判断できます。
| 情報の種類 | 判断 | 理由 |
|---|---|---|
| 判断の理由と背景 | 書く | AIが自動では補完できない |
| 採用しなかった代替案 | 書く | 保守時に「なぜ変えないか」の根拠になる |
| 品質要求(性能・可用性・セキュリティ) | 書く | AIへの指示のベースになる |
| 外部との約束・制約 | 書く | AIが触ってはいけない領域を明示できる |
| コードを見れば分かる処理フロー | 書かなくてよい | AIがコードから導出できる |
| APIの引数一覧・型定義 | 書かなくてよい | OpenAPI等で自動生成できる |
| 説明・手順・仕様・背景が混在した長文 | 書かなくてよい | 読み手にもAIにも扱いにくい |
| テンプレートを埋めただけの定型文 | 書かなくてよい | AIが生成できる領域 |
「書くべき情報」が分かったとしても、どう書けばよいかが分からなければ実務では動けません。ここでは、設計書の整理に使える3つのフレームワークを紹介します。
ADR(アーキテクチャ決定記録)は、Martin Fowler が広めた手法で、重要な設計判断を「1論点1記録」で簡潔に残していくアプローチです。Martin Fowler の解説 でも、ADRは単一の重要な意思決定と、その背景や影響を短く記録する文書として説明されています。
ADRのフォーマットはシンプルで、次の5項目が基本です。
# ADR-003: 認証方式に JWT + HttpOnly Cookie を採用する
## ステータス: 承認済み(2025-10-01)
## コンテキスト
SPA構成のフロントエンドからAPIへの認証が必要。XSSリスクを最小化したい。
モバイルアプリからも同じAPIを利用する可能性がある。
## 決定
JWT + HttpOnly Cookie を採用する。
- アクセストークン: 15分、HttpOnly Secure Cookie
- リフレッシュトークン: 7日、別途HttpOnly Secure Cookie
## 不採用とした選択肢
- localStorage: XSS攻撃でトークンが漏洩するリスクがあり不採用
- サーバーサイドセッション: スケールアウト時にセッション共有が必要になるため不採用
## 影響
- CSRFトークンを別途実装する必要がある
- モバイルアプリからのアクセスは別途Cookie以外の認証フローを検討する
このフォーマットのポイントは、「なぜ採用したか」だけでなく「なぜ採用しなかったか」も記録することです。これにより、将来の担当者やAIエージェントが「なぜlocalStorageを使っていないのか」を設計書から読み取れます。
ADRのファイルはリポジトリの docs/decisions/ 配下に置き、Gitで管理するのが一般的です。変更するたびにステータスを更新(Accepted → Superseded など)することで、生きた記録として維持できます。
Diátaxisは、ドキュメントを目的別に4象限に分類するフレームワークです。設計書に限らず、技術文書全般の整理に使えます。
| 象限 | 目的 | 読者の状態 | 設計書での例 |
|---|---|---|---|
| Tutorial | 学習する | 「やり方を学びたい」 | 開発環境のセットアップガイド |
| How-to | 特定のタスクを完遂する | 「〇〇を実装したい」 | 認証フローの実装手順 |
| Reference | 仕様を確認する | 「この挙動はどうなっているか」 | APIエンドポイント仕様一覧 |
| Explanation | 背景・理由を理解する | 「なぜこの設計なのか」 | アーキテクチャの選定理由、ADR |
Diátaxis は、Tutorial・How-to・Reference・Explanation の4種類はそれぞれ目的が異なり、混在させると読者が迷いやすくなると整理しています。
設計書でよく起きる問題は、チュートリアル(tutorial)・手順(how-to)・仕様(reference)・背景説明(explanation)が1つの文書に混在することです。Diátaxisの観点で分けると、人間にとっても読みやすく、AIにとっても「どの文書を何のために使うか」が明確になります。
たとえば、アーキテクチャ設計書を次のように分けると整理しやすくなります。
arc42は、ソフトウェアアーキテクチャを12のセクションで整理するテンプレートです。特徴は「全部埋める必要はない」という設計思想です。プロジェクトの複雑さや規模に応じて、必要なセクションだけを使います。
AI時代において特に価値が高いセクションは次の3つです。
| セクション | 内容 | AI時代の価値 |
|---|---|---|
| 制約(Constraints) | 技術的・組織的・法的な制限事項 | AIに「触ってはいけない領域」を伝えられる |
| 品質要求(Quality Requirements) | 性能・可用性・セキュリティなどの非機能要件 | AIへの指示のベースになる |
| アーキテクチャ決定(Architecture Decisions) | 重要な設計判断とその根拠(ADRと連携) | コンテキストファイルに組み込みやすい |
arc42の残りのセクション(コンポーネント図、ランタイムビューなど)は、OpenAPIやIaCコードから自動生成できる情報が多いため、手動で維持するコストと見合うかを判断しながら使うのが実務的です。
| フレームワーク | 主な用途 | 向いている場面 |
|---|---|---|
| ADR | 判断の記録 | 「なぜそうしたか」を残したい |
| Diátaxis | 文書の分類・整理 | 設計書が混在していて整理したい |
| arc42 | アーキテクチャの全体構造化 | プロジェクトの設計書を体系的に整備したい |
3つすべてを採用する必要はありません。まずはADRだけ始めるのが最も取り組みやすく、効果が実感しやすいです。重要な判断が出るたびに短い記録を積み上げるだけで、保守性と引き継ぎのしやすさが大きく変わります。
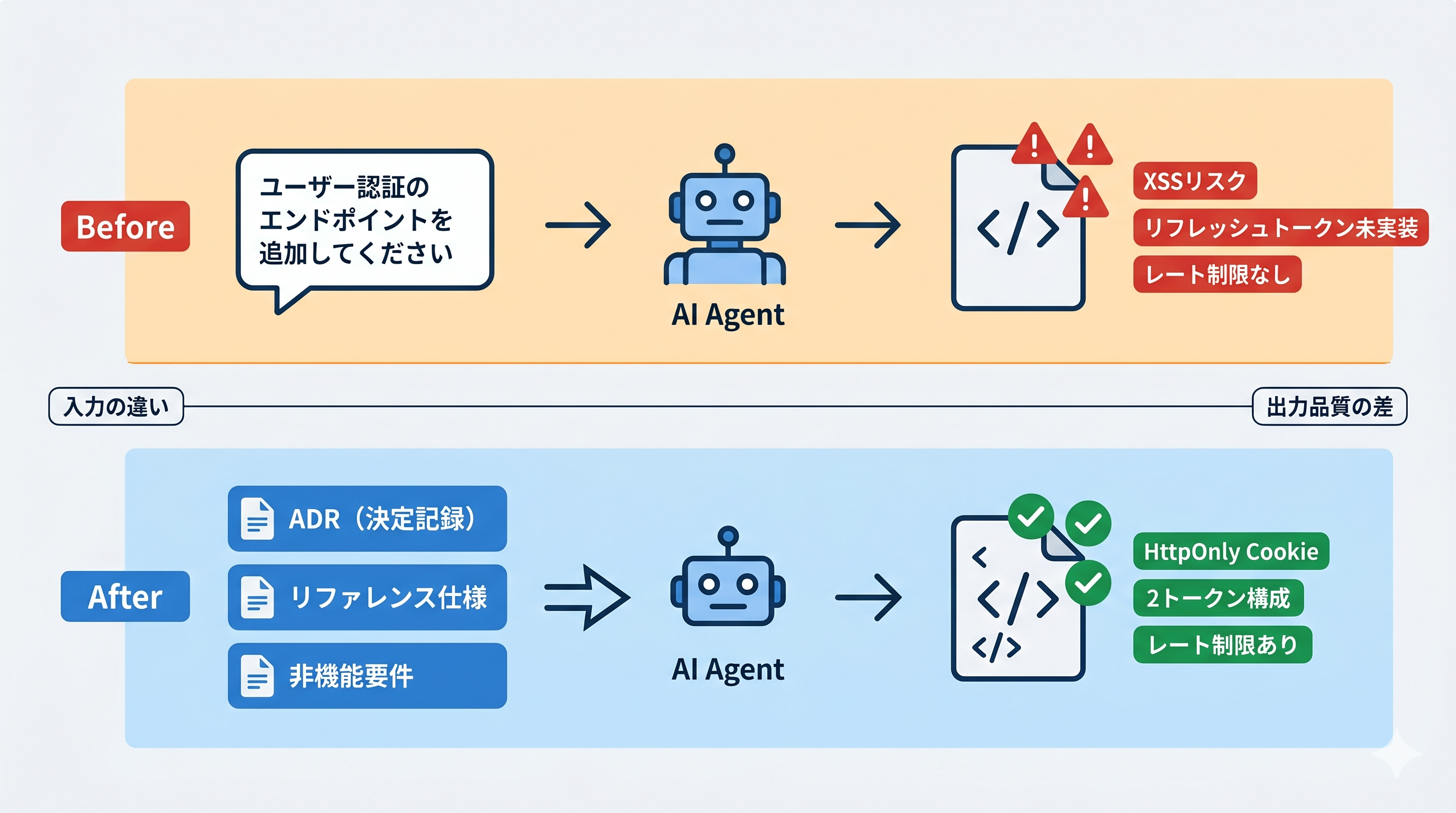
「理屈は分かっても、本当に効果があるのか?」という疑問に答えるため、実際に構造化された設計書をAIコーディングエージェントに渡してみました。今回の小規模な比較では、設計書を構造化すると出力品質が改善する傾向が見られました。
目的: ADR・Diátaxis形式のリファレンス・非機能要件という構造化された設計書を渡した場合と渡さない場合で、AIエージェントの出力品質にどんな差が生まれるかを比較する。
シナリオ: 新たなJavaScriptファイルとして、次の要件でユーザー認証エンドポイントAPIを追加する。
検証ツール(2026年4月時点): OpenAI Codex(GPT-5.4) / Gemini CLI(Gemini 3 Flash preview) / Claude Code(Claude Sonnet 4.6)
比較方法: 設計書なし(Before)と構造化された設計書あり(After)の出力を比較する。今回は各条件1回ずつの探索的な比較であり、統計的な評価ではありません。
なお、今回は追加の実行モード切り替えや細かなチューニングは行わず、通常利用に近い条件で比較しています。
設計書なしでは、次のプロンプトだけを渡しました。今回の比較は各条件1回ずつです。
ユーザー認証のエンドポイントAPIをJavaScriptの新規ファイルで作成してください。JWTを使います。
3つのツールはいずれも、/register、/login、/me といった基本的な認証APIを短時間で生成できました。実装の細部には差があるものの、全体としては「JWTを発行してBearerトークンとして扱う」「ユーザー情報はプロセス内メモリに保持する」「最小限の入力検証だけで成立させる」という、プロトタイプ寄りの共通パターンに収束しています。
たとえば、各ツールの出力には次のような共通要素が見られました。
app.post('/login', async (req, res) => {
const user = findUser(req.body);
const token = jwt.sign({ sub: user.id }, SECRET_KEY, { expiresIn: '1h' });
res.json({ token });
});
app.get('/me', authenticateToken, (req, res) => {
res.json(req.user);
});
しかし、設計上の前提が与えられていないため、実装は認証基盤として必要な要件を十分には満たしていません。主要な問題を共通項として整理すると、次の4点に集約できます。
| 問題 | 内容 |
|---|---|
| トークン管理が脆弱 | res.json({ token }) でアクセストークンを返す実装が中心で、フロントエンドで localStorage 保存される前提になりやすい。XSS時の漏洩リスクが高く、Cookie運用の方針も統一されていない。 |
| セッション継続設計がない | リフレッシュトークンや再発行エンドポイントがなく、アクセストークン失効後は再ログイン前提になる。実運用を想定した認証フローとしては不十分。 |
| 防御策が不足している | ログイン試行に対するレート制限、失効管理、ユーザー存在確認などが不十分で、ブルートフォースや古いトークンの悪用への備えが弱い。 |
| アプリケーション規約と整合していない | エラーレスポンス形式が { message } や素のステータス返却などに分かれ、プロジェクト共通のAPI仕様として扱いづらい。 |
次の3種類の設計書を渡しました。
① ADR(決定記録)
# ADR-003: 認証方式に JWT + HttpOnly Cookie を採用する
## ステータス: 承認済み
## コンテキスト
SPA構成のため、XSSリスクを最小化したい。
## 決定
JWT + HttpOnly Cookie を採用する。
## 不採用とした選択肢
- localStorage: XSSでトークンが漏洩するリスクがあり不採用
## 影響
- アクセストークン: 15分、HttpOnly Secure Cookie に保存
- リフレッシュトークン: 7日、別途HttpOnly Secure Cookie に保存
② Diátaxis形式のリファレンス(仕様定義)
## POST /auth/login
- リクエスト: `{ email: string, password: string }`
- レスポンス(成功): `{ userId: string }` + Set-Cookie ヘッダー(アクセス・リフレッシュ)
- レスポンス(失敗): `{ error: { code: string, message: string } }`
- エラーコード: AUTH_FAILED, VALIDATION_ERROR, RATE_LIMIT_EXCEEDED
③ 非機能要件(制約)
## 認証エンドポイントの非機能要件
- レート制限: /auth/* は 1IP あたり 10req/15min
- トークン保存: localStorage は禁止、HttpOnly Cookie のみ使用する
- エラーレスポンス: 全エンドポイントで `{ error: { code, message } }` 形式を使用する
設計書を渡した上で同じ指示を出すと、3つのツールとも概ね次のような実装を生成しました。
全文を掲載すると冗長なので、共通して改善されたポイントだけを抽象化すると次のようになります。
app.post("/auth/login", authLimiter, async (req, res) => {
const user = await authenticateUser(req.body);
if (!user) {
return res.status(401).json({
error: { code: "AUTH_FAILED", message: "Invalid email or password" },
});
}
const accessToken = signAccessToken(user.id, "15m");
const refreshToken = signRefreshToken(user.id, "7d");
res.cookie("access_token", accessToken, httpOnlyCookieOptions);
res.cookie("refresh_token", refreshToken, httpOnlyCookieOptions);
return res.status(200).json({ userId: user.id });
});
Before と比べると、今回の比較では設計書ありの出力に次のような改善傾向が見られました。
もっとも大きな違いは、認証方式がプロトタイプ寄りの単純なJWT実装から、運用を前提にした構成へ寄ったことです。localStorage 前提ではなく HttpOnly Cookie を使う方向に揃い、リフレッシュトークンを含む2トークン構成や /auth/* へのレート制限も反映されました。エラーレスポンスも { error: { code, message } } 形式に揃いやすくなり、単に「動くログインAPI」を作る段階から、「要件を満たす認証API」を組み立てる段階へ進んだと言えます。
特に興味深かったのは、設計書に判断理由まで含めると、単に仕様を満たすだけでなく、「なぜその実装を選んだのか」までコードに残す振る舞いが一部で見られたことです。たとえば Claude Code や OpenAI Codex では、ADR-003 を参照するコメントが付くケースがありました。
| 観点 | 設計書なし | 設計書あり(ADR + リファレンス + 非機能要件) |
|---|---|---|
| トークン保存方式 | localStorage想定(セキュリティリスク) | HttpOnly Cookie(ADR準拠) |
| リフレッシュトークン | 未実装 | 実装済み・有効期限7日 |
| レート制限 | なし | express-rate-limit導入(10req/15min) |
| エラーハンドリング | 独自フォーマット | プロジェクト規約に準拠 |
| 要件充足度 | 低い | 高い |
ただし、同じ設計書を渡しても、どの情報を強く拾うかにはツールごとの個性がありました。差が出たのは、実装の正否そのものよりも、設計意図や判断理由をどこまでコードに持ち込むかという点です。
OpenAI Codex
今回の比較では、判断理由をコメントとして残す場面はありましたが、設計書の構造に対する感度はやや低めでした。逆に言えば、Codex では特に ADR・リファレンス・非機能要件を分けて明示するなど、入力を構造化したときの差が出やすいとも言えます。
Gemini CLI
今回の比較では、@docs/ で指定した内容を素直に実装へ反映する傾向が強く、非機能要件の反映は安定していました。一方で、ADRの背景をコメントとして残すよりは、「書かれている仕様をそのまま満たす」方向に寄りやすい印象でした。
Claude Code
今回の比較では、設計意図をコードコメントに落とし込む傾向が最も強く、ADR番号や非機能要件への参照が残ることがありました。仕様準拠だけでなく、判断の背景までコードに写し取ろうとする挙動が見えました。
この比較は筆者が各条件1回ずつ実行した結果です。生成AIの出力は非決定的であり、常に同じ結果になるとは限りません。
今回の検証で最も効果が大きかったのは、「してはいけないこと」と「代わりにすること」をセットで書いた箇所でした。「localStorage 禁止」だけを書いた場合は指示が守られないケースもありましたが、「localStorage 禁止、HttpOnly Cookie を使う」とセットで書くと、3ツールすべてで正しく反映されました。
これは Anthropic のエージェント設計ガイド にも通じる考え方です。禁止事項だけでなく、期待する振る舞いを具体的に書くほど、エージェントの挙動は安定しやすくなります。
また、ADR形式の「なぜ採用しなかったか」という記録が、AIエージェントにとって「なぜこの実装パターンを使ってはいけないか」の根拠としても機能することが分かりました。判断理由の記録は、人間向けの説明責任だけでなく、AIへの指示品質にも直結します。
本記事の内容をまとめます。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。



