
生成AI関連
生成AIに機密情報を渡していいの?
ChatGPTやClaude、Geminiのようなクラウド型の生成AIサービスは、業務でも広く使われるようになりました。本記事では、このように外部事業者のクラウド環境上でLLM(大規模言語モデル)が動作し、インターネット経由で利用する形態を「クラウドLLM」と総称します。
一方で、業務利用が進むほど、社内文書、設計資料、問い合わせ履歴、顧客情報など、外部サービスにそのまま送信しづらい情報を扱う場面も見えてきます。そのような制約がある場合、ローカルLLMという選択肢が検討対象になります。
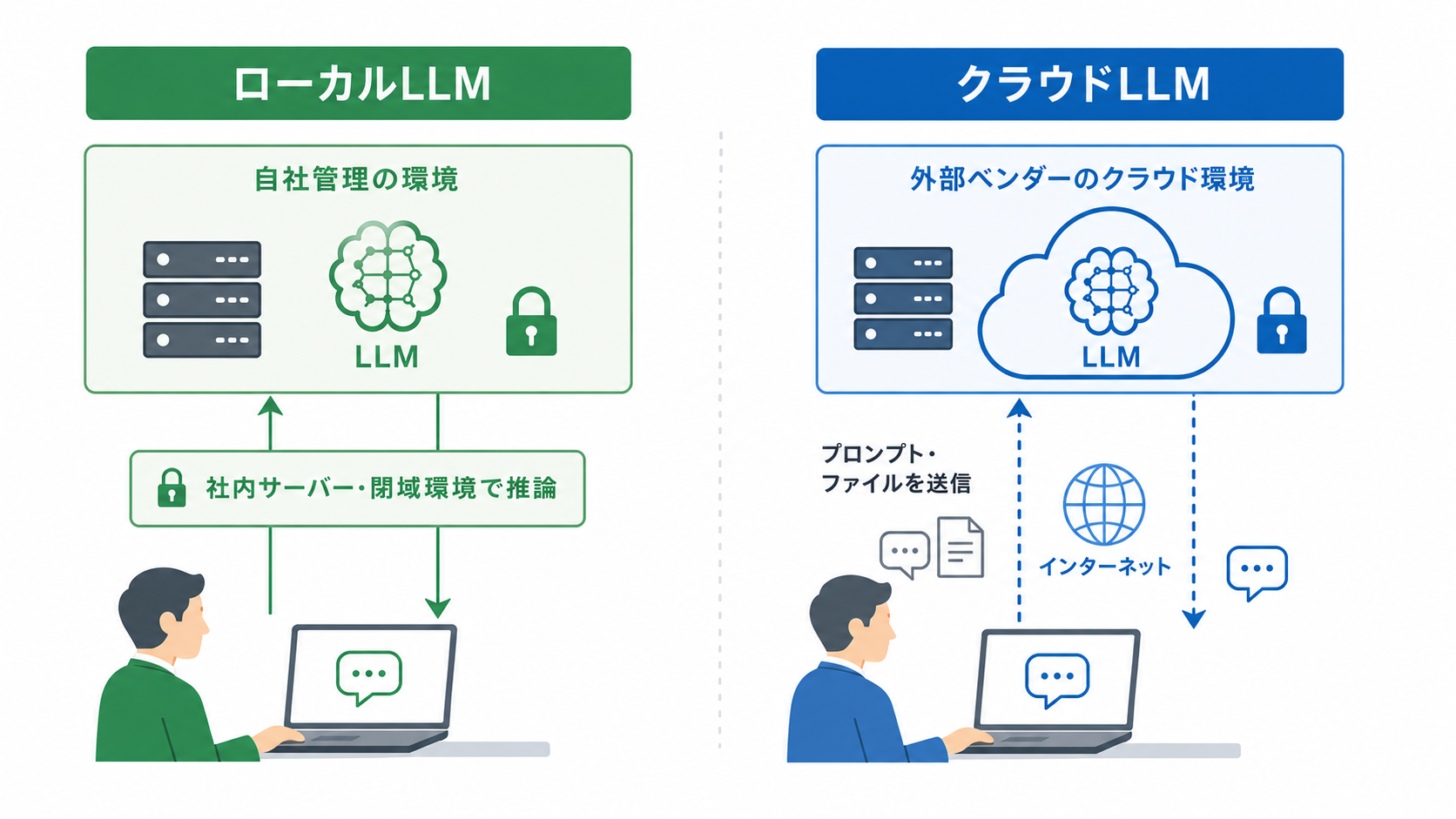
ローカルLLMは、手元のPCや社内サーバー、閉域環境など、自社が管理する環境でLLMを動かす考え方です。クラウドLLMのように外部ベンダーのAPIへ毎回リクエストを送るのではなく、モデルと実行環境を自社側に置くことで、データ管理やアクセス制御を自社のセキュリティ要件に合わせて設計しやすくなります。
ただし、クラウドLLMで行っていた処理を、そのままローカルLLMへ置き換えれば同じように使えるとは限りません。モデルの性能、ハードウェア、運用体制、セキュリティ設計、評価方法などを含めて、改めて設計する必要があります。
本記事では、ローカルLLMの基本的な考え方、クラウドLLMとの違い、業務利用でのメリットと注意点、導入判断のポイントを整理します。
機密情報を生成AIに入力する際の法務・契約面の注意点については、下記の記事でも解説しています。ローカルLLMを検討する背景として、あわせて確認すると理解しやすくなります。
ローカルLLMとは、利用者や企業が管理する環境で動作する大規模言語モデルのことです。ここでいう「ローカル」は、必ずしも個人のPCだけを指すわけではありません。社内サーバー、オンプレミス環境、プライベートクラウド、閉域網内のGPUサーバーなども含めて考えます。
ローカルLLMを構築する場合は、公開されているオープンソースまたはオープンウェイトのLLMを取得し、自社環境で推論できるように設定するケースが多くあります。オープンソースLLMは、モデルのコードや学習・推論に関わる実装が公開されているLLMを指します。一方、オープンウェイトLLMは、学習済みモデルの重みが公開されており、利用者がその重みをダウンロードして実行できるLLMを指します。
ただし、オープンウェイトであっても、学習データや学習コードまで公開されているとは限りません。また、商用利用、改変、再配布の条件はモデルごとのライセンスによって異なります。そのため、業務で利用する場合は、モデルの性能だけでなく、ライセンス条件や利用規約の確認も欠かせません。
クラウドLLMでは、利用者が入力したプロンプトやファイルを、外部ベンダーが提供するサービスやAPIに送信し、そこで推論処理を行います。一方、ローカルLLMでは、モデルの推論処理を自社側の環境で実行します。
| 観点 | ローカルLLM | クラウドLLM |
|---|---|---|
| 実行場所 | 自社管理のPC、サーバー、閉域環境 | 外部ベンダーのクラウド環境 |
| データ送信 | 外部送信を抑えた構成を取りやすい | APIやWebサービスにデータを送信する |
| モデル性能 | 選択するモデルと実行環境に依存する | 高性能な商用モデルを利用しやすい |
| 初期準備 | モデル、実行環境、ハードウェアの準備が必要 | アカウントやAPIキーを用意すれば始めやすい |
| 運用負荷 | モデル更新、環境管理、監視が必要 | ベンダー側に任せられる範囲が広い |
| コスト | 機材費、電力、保守費が発生する | 利用量に応じた課金が中心 |
| 使用できるモデル例 | gpt-oss、Llama、Qwenなど | GPT-5.5、Claude、Geminiなど |
ローカルLLMは「外部にデータを送らないための選択肢」として語られることが多いですが、それだけで安全性や実用性が保証されるわけではありません。実行環境を自社で管理する分、アクセス制御、ログ管理、脆弱性対応、品質評価も自社側の責任範囲になります。
前提として、ローカルLLMで扱えるタスクの種類は、概ねクラウドLLMと共通しています。文章生成、要約、分類、翻訳、コード生成、質問応答など、LLMを使った主要な処理はローカル環境でも実行できます。
違いが出るのは、「できるかどうか」よりも「どの程度の品質・速度・安定性で実行できるか」です。実際の性能は、モデルの能力、モデルサイズ、量子化の有無、GPUやメモリの性能、プロンプト設計によって変わります。
代表的な用途は次のようなものです。
特に、要約や分類のように出力形式をある程度限定できるタスクは、ローカルLLMでも検証しやすい領域です。反対に、複雑な推論、最新情報を踏まえた調査、高度なコーディング、長い文脈を正確に扱う処理では、主要ベンダーが提供するクラウドLLMのフラッグシップモデルの方が安定する場合が多いです。
ローカルLLMのメリットは、主にデータ管理、コスト、カスタマイズ性、環境制約への対応にあります。
ローカルLLMでは、推論処理を自社側の環境で完結させられるため、プロンプトや入力ファイルを外部サービスへ送信しない構成を取りやすくなります。これは、機密情報、個人情報、契約上外部提供が制限されている情報を扱う場合に重要な観点です。
ただし、ローカル環境で動かしていても、運用設計が不十分であれば情報漏えいリスクは残ります。利用者の権限管理、端末の持ち出し制御、ログの保存方針、生成結果の取り扱いルールなどの設計が別途必要です。
クラウドLLMは、入力トークン数や出力トークン数に応じて費用が発生することが一般的です。大量の要約や分類を継続的に行う場合、利用量に応じてコストが増えます。
ローカルLLMでは、モデルの推論処理を自社環境で行うため、外部のLLM APIへの利用料は発生しません。その代わり、GPUサーバーの購入費、クラウドGPUの利用料、電力、保守、運用担当者の工数が発生します。そのため、単純に「ローカルの方が安い」とは言えません。
コスト比較では、次のような項目を含めて考えます。
利用頻度が少ない場合はクラウドLLMの方が合理的なこともあります。一方で、定型処理を大量に実行する場合や、閉域環境での利用が必須の場合は、ローカルLLMが検討対象になります。
ローカルLLMでは、用途に応じてモデルを選び、実行環境やプロンプト、RAG構成を調整できます。たとえば、要約に特化した用途、コード補助に寄せた用途、日本語文書の分類に寄せた用途など、業務ごとに構成を分けられます。
また、オープンなモデルやツールを利用することで、モデルの入れ替えや検証を自社内で進めやすくなります。Ollama、 LM Studio、 llama.cpp、 vLLMのようなツールや実行基盤は、ローカルLLMを検証する際の代表的な選択肢として知られています。
ただし、ライセンス条件や商用利用の可否はモデルごとに異なります。業務利用では、モデルの利用規約、配布条件、再配布の可否、生成物の扱いを事前に確認しておきましょう。
ローカルLLMを検討する際は、メリットだけでなく、実務上の制約も把握しておく必要があります。
クラウドLLMでは、非常に大規模なモデル、最新の推論機能、大規模な推論インフラを利用できることがあります。ローカルLLMでも高性能なモデルは増えていますが、現時点ではOpenAI、Anthropic、Googleなどの主要ベンダーが提供するフラッグシップモデルと同等以上の品質や安定性を前提にしない方が現実的です。
これは、ローカルLLMに価値がないという意味ではありません。機密情報を外部に送信しない構成、閉域環境での利用、定型処理の大量実行、コスト管理など、クラウドLLMとは別の評価軸で有効になる場面があります。とはいえ、同じタスクで常にクラウドLLMと同等の品質が出るとは限りません。
特に、次のようなタスクでは差が出やすくなります。
ローカルLLMを使う場合は、用途を絞り、評価しやすいタスクから始めることをおすすめします。たとえば、問い合わせ分類、文章の要約、テンプレートに沿った下書き作成などは、評価観点を定めやすい用途です。
ローカルLLMの実行には、CPU、メモリ、GPU、ストレージが関わります。小さなモデルであれば一般的なPCでも動作する場合がありますが、応答速度や同時利用数を求める場合はGPUが必要になることが多いです。モデルサイズが大きくなるほど、必要なメモリやGPUメモリも増えます。
業務利用では、次の観点を事前に確認します。
個人PCで動いた構成が、そのままチーム利用や本番利用に耐えるとは限りません。最初から、最終的な利用規模を見据えて検証することが大切です。
ローカルLLMは外部送信を抑えやすい一方で、環境管理の責任は自社側に寄ります。モデルサーバーへのアクセス制御、利用ログの管理、監査、バックアップ、脆弱性対応、ネットワーク分離などを設計しなければなりません。
また、ローカル環境であっても、生成結果に機密情報が含まれる可能性があります。RAGと組み合わせる場合、検索された社内文書の一部が回答に反映されるため、回答の閲覧権限も重要です。利用者が本来アクセスできない文書の内容を、生成AI経由で取得できる構成は避ける必要があります。
「ローカルだから安全」ではなく、「どのデータに誰がアクセスでき、どのようなログが残り、問題発生時に追跡できるか」を設計することが重要です。
ローカルLLMを導入するかどうかは、技術的な興味だけで決めるべきではありません。対象業務、データの性質、必要な精度、運用体制を踏まえた判断が求められます。
| 判断軸 | 確認すること |
|---|---|
| データの機密性 | 外部サービスへの送信が許容されるか |
| 必要な品質 | ローカルモデルで求める品質に到達できるか |
| 応答速度 | 利用者が待てる時間内に回答できるか |
| 利用量 | API費用と自社運用費のどちらが合理的か |
| 運用体制 | モデル、サーバー、ログ、権限を管理できるか |
| ライセンス | モデルを業務利用できる条件を満たしているか |
| セキュリティ | 閉域化、認証、監査、権限管理を設計できるか |
たとえば、公開情報の要約や一般的な文章作成であれば、クラウドLLMの方が導入しやすい場合があります。反対に、外部送信できないデータを扱う業務、閉域環境での利用、一定量の定型処理を継続的に実行する業務では、ローカルLLMの検討価値が高まります。
クラウドLLMとローカルLLMは、どちらか一方だけを選ぶものではありません。実務では、用途に応じて使い分ける構成が現実的です。
| 用途 | 向いている選択肢 |
|---|---|
| 一般的な文章作成、調査、企画の壁打ち | クラウドLLM |
| 最新情報を踏まえた調査 | クラウドLLMまたはWeb検索連携 |
| 機密情報を含む文書の要約 | ローカルLLMまたは専用契約のクラウド環境 |
| 大量の定型分類処理 | ローカルLLMまたは低コストなAPI構成 |
| 社内文書検索 | RAGとローカルLLM、または閉域対応のクラウド基盤 |
重要なのは、ローカルLLMを「クラウドLLMより安全なもの」と一括りにしないことです。安全性、品質、コスト、運用負荷のどこを重視するかによって、適した構成は変わります。
ローカルLLMを検証する場合は、本番環境や大規模なRAG構成を作るよりも、限定用途で評価するのが現実的です。手元や社内にGPU環境があるかどうかで、最初の進め方は変わります。
GPU環境がある場合は、Ollama、 LM Studio、 llama.cpp、 vLLMなどを使って、候補モデルを実際にローカル環境で動かして評価できます。この場合は、応答品質、応答速度、メモリ使用量、同時利用数を確認できます。
GPU環境がない場合でも、検証を始められないわけではありません。公開されているオープンウェイトモデルをクラウドAPIで提供しているサービスを使えば、自前のGPUを用意せずにモデルの回答傾向を確認できます。ただし、この方法で確認できるのは主に回答品質です。応答速度、同時実行性能、メモリ使用量などは、実際にローカル環境で動かす場合とは大きく異なるため、別途評価が必要です。
たとえば、2026年6月時点では、クラウド経由でオープンウェイトモデルを実行できるサービスとして、Together AI、 Fireworks AI、 Groq、 Hugging Face Inference Providers などがあります。
なお、この方法はローカルLLMの実行ではありません。入力データは外部サービスに送信されるため、機密情報や個人情報を使った検証には向きません。ダミーデータで出力傾向やプロンプトの相性を確認する用途であれば有効です。
対象業務は、問い合わせ文のカテゴリ分類、議事録の要約、社内FAQの回答案作成など、評価観点を用意しやすいものから選ぶと進めやすくなります。
最初から「社内文書を何でも質問できるAI」を目指すと、検索設計、権限管理、回答評価、運用ルールが複雑になります。まずは限定用途でローカルLLMの特性を把握し、その後にRAGや業務システム連携へ広げる方が、課題を切り分けやすくなります。
ローカルLLMは、外部サービスにデータを送信しづらい業務や、閉域環境で生成AIを使いたい場面で有力な選択肢になります。データ管理の自由度を高められる一方で、モデル性能、ハードウェア、セキュリティ、運用体制を自社側で考える必要があります。
本記事の要点は次のとおりです。
ローカルLLMは、クラウドLLMを置き換える技術というより、生成AIの利用場所と管理方法を広げる選択肢です。業務要件に応じてクラウドLLM、ローカルLLM、RAG、専用契約のクラウド基盤を使い分けることで、実務に合った生成AI活用を設計しやすくなります。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。



