はじめに – RAG(検索拡張生成)が切り拓くビジネス現場でのAI活用
ChatGPTをはじめとする生成AIは、ここ数年で急速にビジネスの現場に浸透し、文章の要約、議事録作成、プログラミング、顧客対応など、幅広い業務に活用されています。
しかし実際に使ってみると、「最近の情報に対応できていない」「応答の根拠がわからず不安」といった、“AIはすごいけど、これじゃ使えない”という声も少なくありません。
この課題に対するアプローチとして注目されている技術がRAG(検索拡張生成)です。
RAGは、ユーザーの質問に対して外部情報を検索・取得し、それをもとに生成AIが回答を行う仕組みで、応答の正確性と信頼性を大きく向上させることができます。
本記事では、Tech Fun社内で開発した、RAGを活用したAIチャットボットの事例をご紹介します。生成AIを業務にもっと活かしたい方に向けて、実践的なヒントをお伝えします。
RAG(検索拡張生成)とは?生成AIと組み合わせた検索拡張技術の概要
まずは、RAGの概要について簡単にご紹介します。
RAGの仕組みと特徴
RAGとは、「Retrieval-Augmented Generation」の略で、読み方は「ラグ」です。日本語に訳すと「検索拡張生成」となります。
これは、ChatGPTのような生成AIに対して、外部のドキュメントやデータベースの情報を参照させ、文脈に沿った有益な回答を生成する手法です。
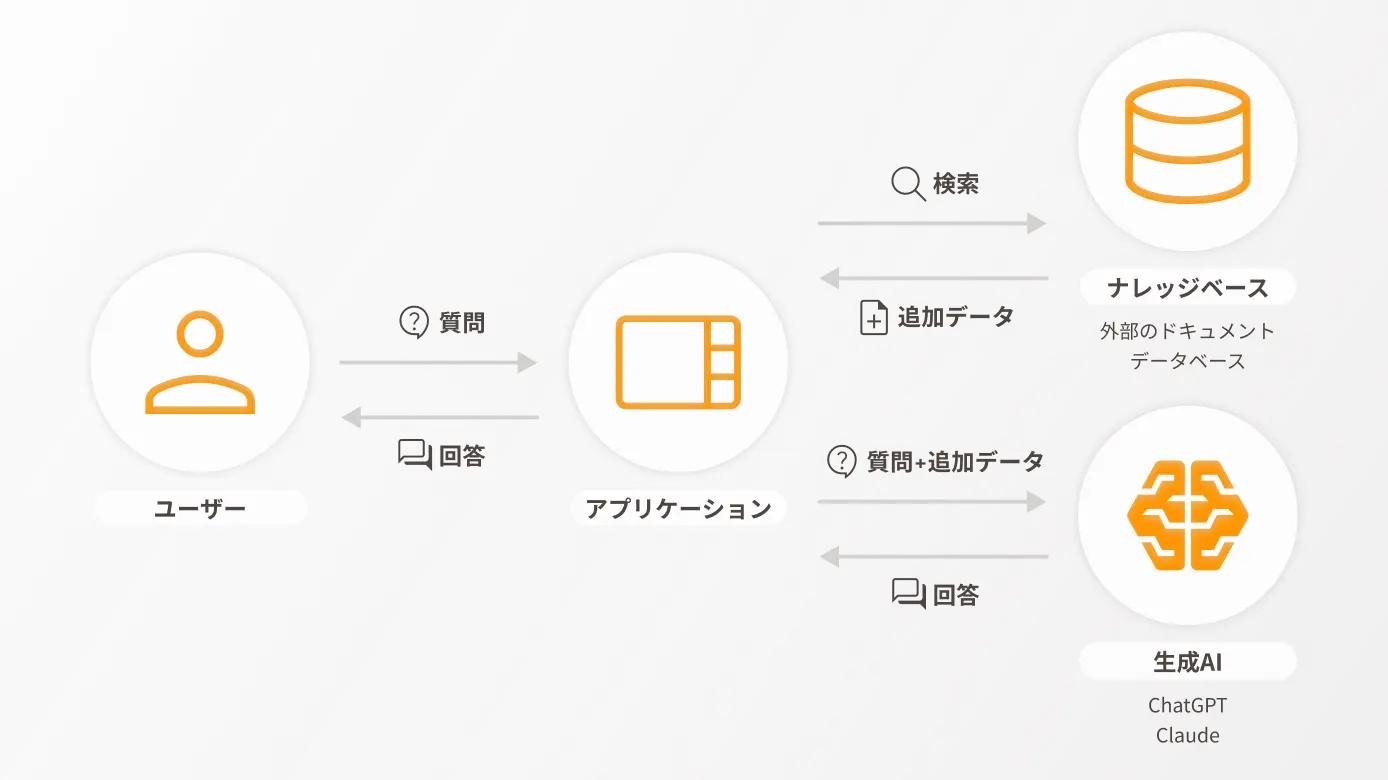
LLM(大規模言語モデル)に追加学習(ファインチューニング)させるのではなく、外部データをリアルタイムで検索・活用する点が大きな特徴です。このため、最新情報を反映しやすく、幅広い分野の情報検索に柔軟に対応できます。
RAGのコンセプトは、2020年にMeta(旧Facebook)が発表した論文で提唱されました。その後、生成AIの普及とともに急速に導入が広がっています。
RAGが効果を発揮するユースケース
RAG(検索拡張生成)は、「生成AIの柔軟な応答力」と「正確かつ最新の外部データ」を組み合わせることで、さまざまなシーンでの活用が期待されています。以下に代表的なユースケースを紹介します。
- 社内ナレッジ検索
- カスタマーサポート
- 医療・法律・金融などの専門分野
- 学習支援
このようにRAGは、情報の正確さや鮮度が求められる場面や、生成AIと組み合わせたインタラクティブな応答が必要な状況で特に威力を発揮します。社内業務の効率化から、顧客対応、教育、専門領域まで、今後さらに幅広く活用されていくと考えられます。
Tech Funの社内ポータルサイトの課題とRAG(検索拡張生成)の活用
ここからは、RAG(検索拡張生成)の導入対象として、Tech Fun社の社内ポータルサイトを選んだ理由をご紹介します。
社内ポータルサイトの課題
Tech Funでは、社内制度や業務ルール、各種申請手順などの情報を網羅的に掲載した社内ポータルサイトを、Googleサイトで構築しています。

この社内ポータルサイトには以下のような課題があり、社内でも問題意識が高まっていました。
- ページの数が多く、情報を見つけにくい
- キーワード検索の精度が低く、検索結果が不十分
- バックオフィスへ同様の問い合わせが頻発し、対応負荷が増大
業務に必要な情報を幅広く掲載しているため、ページ数が膨大になり、構造も複雑化していました。
トップページのディレクトリから目的の情報にたどり着くのが難しいケースが多く見られました。
- 資格報奨金を利用するにはどうしたらいい?
- 資格取得支援制度は申請の期限は?
- フレックス勤務の申請方法は?
このように、情報へのアクセス性が低いために、社内ルールや業務手順の理解に時間を要する状況になっており、組織全体の課題となっていました。
社内ポータルサイトをRAGの検証対象にした理由
こうした背景から、Tech Funの社内では、単なる検索機能の改善ではなく、「ユーザーの質問意図を理解し、文脈をふまえて適切に回答する」仕組みが求められていました。
ただし、生成AIは自然言語での応答には優れているものの、社内の情報を学習していないため、そのままでは役に立ちません。
そこで注目したのがRAGです。生成AIとドキュメント検索を組み合わせることで、Slackのような日常的なコミュニケーション環境においても、従業員が自然な言葉で質問し、社内ドキュメントに基づいた正確な回答を得ることができます。
また、社内ポータルサイトがGoogleサイトで構築されており、データ活用に適した基盤がすでに整っていたことも、RAGの導入を進めやすい要因となりました。
このように、社内の状況とRAGの特性が合致したことから、RAGの検証としてAIチャットボットの開発をスタートすることになりました。
AIチャットボットの利用イメージ
今回開発したAIチャットボットの利用イメージをご紹介します。
ユーザーは、Slack上でチャットボットにメンションを付けて投稿するだけで、簡単に回答を得ることができます。
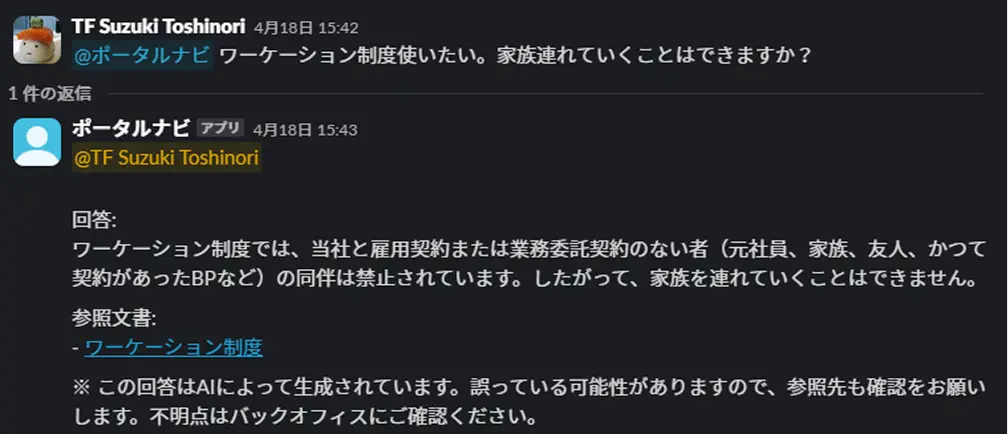
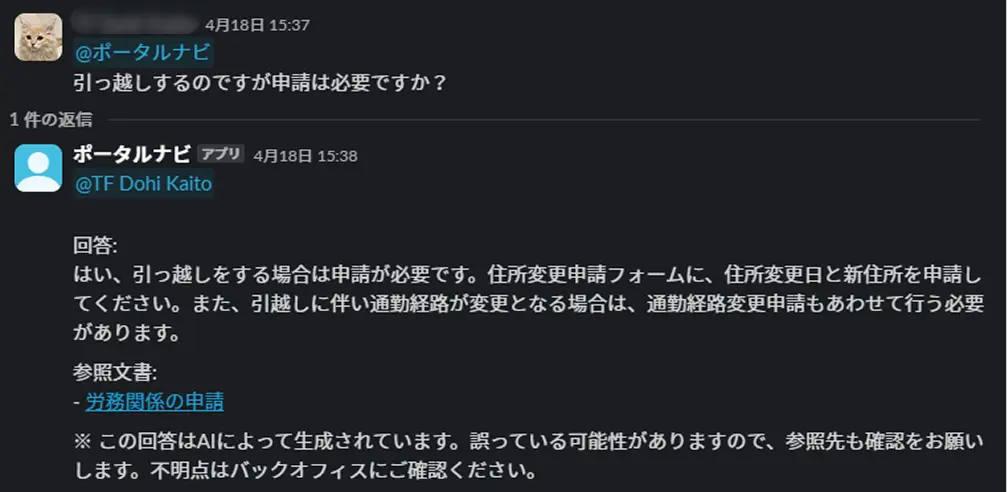
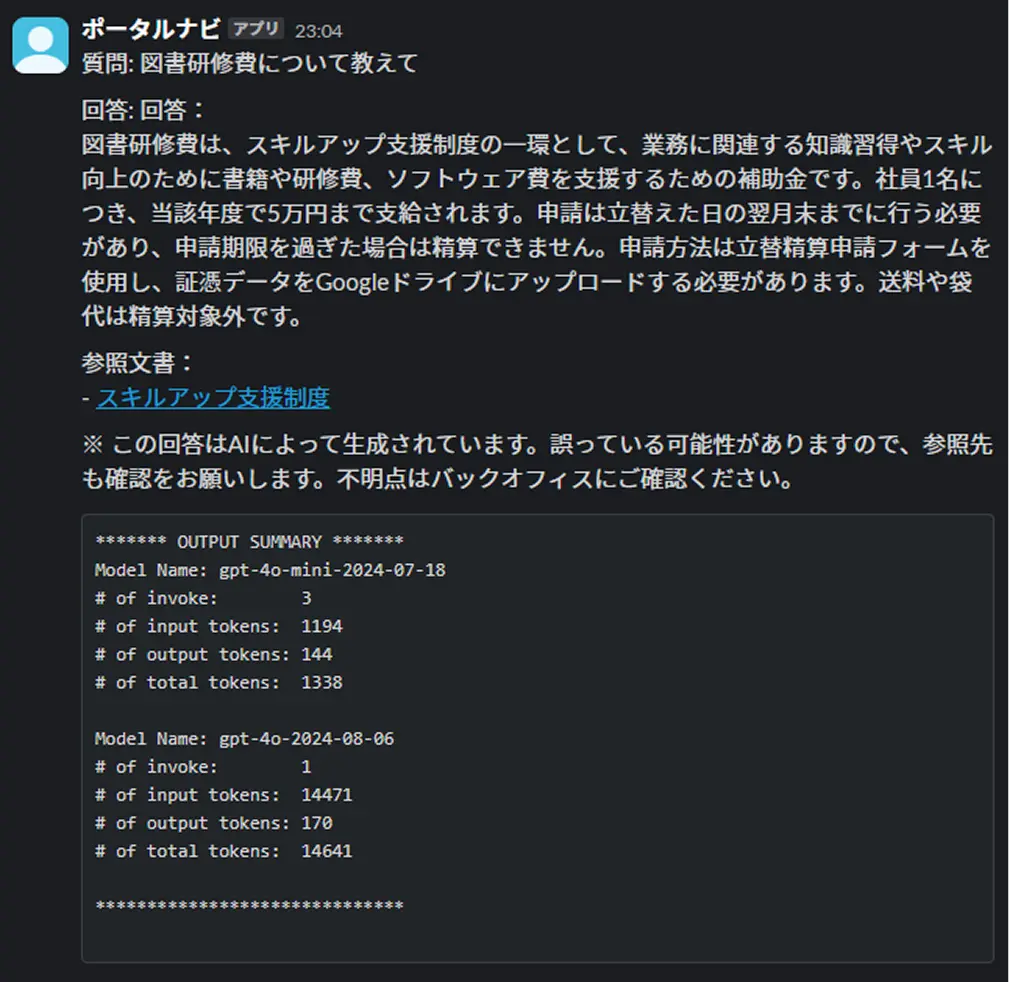
※この応答では、使用したモデルや入力・出力トークン数を表示し、無駄なトークン消費が発生していないかをモニタリングしています
いずれの質問例でも、ユーザーの意図に沿った適切な回答が返されていることがわかります。参照された関連ページも提示されるため、詳細の確認もしやすくなっています。
AIチャットボットの技術とアーキテクチャ
続いて、AIチャットボットの動作の仕組みと、開発に使用した技術について紹介します。
AIチャットボットの動作の流れ
AIチャットボットは次のように動作します。
-
1.社内ポータルのドキュメントを、拡張データとして活用できるよう、あらかじめマークダウン形式のデータベースに変換しておく
-
2.ユーザーがSlackで行った問い合わせに応じて、関連するドキュメントをデータベースから検索・取得する
-
3.問い合わせ内容と取得したドキュメントをもとに解析を行い、生成AIへの入力クエリを整形する
-
4.整形したクエリをChatGPTまたはClaudeに入力し、生成された回答をSlack上に表示する
全体の流れをシーケンス図で表すと、次のようになります。(検証時に導入した仕様も含まれています)
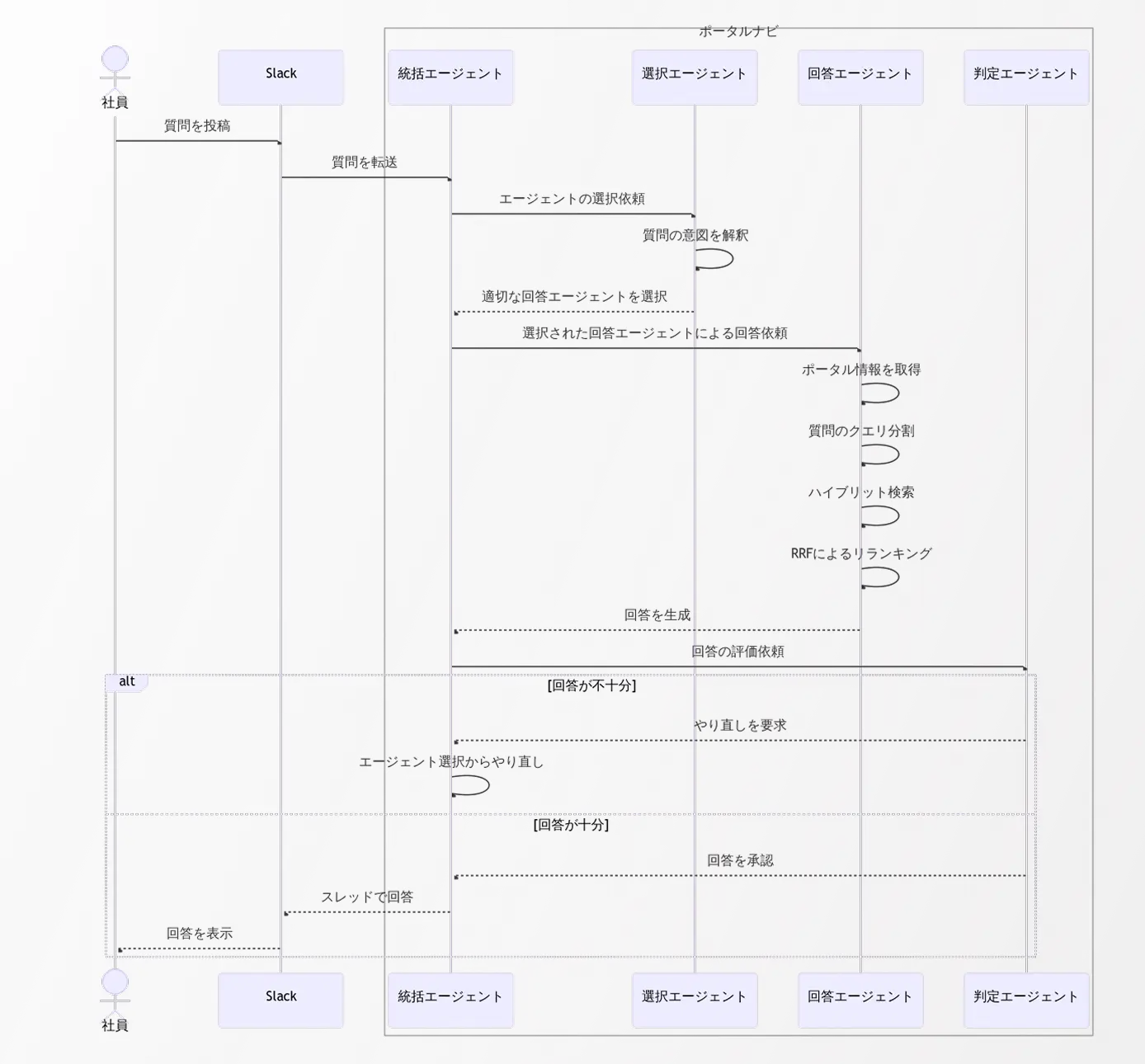
AIチャットボットのアーキテクチャと技術要素
アーキテクチャは、以下の図のように構成されています。
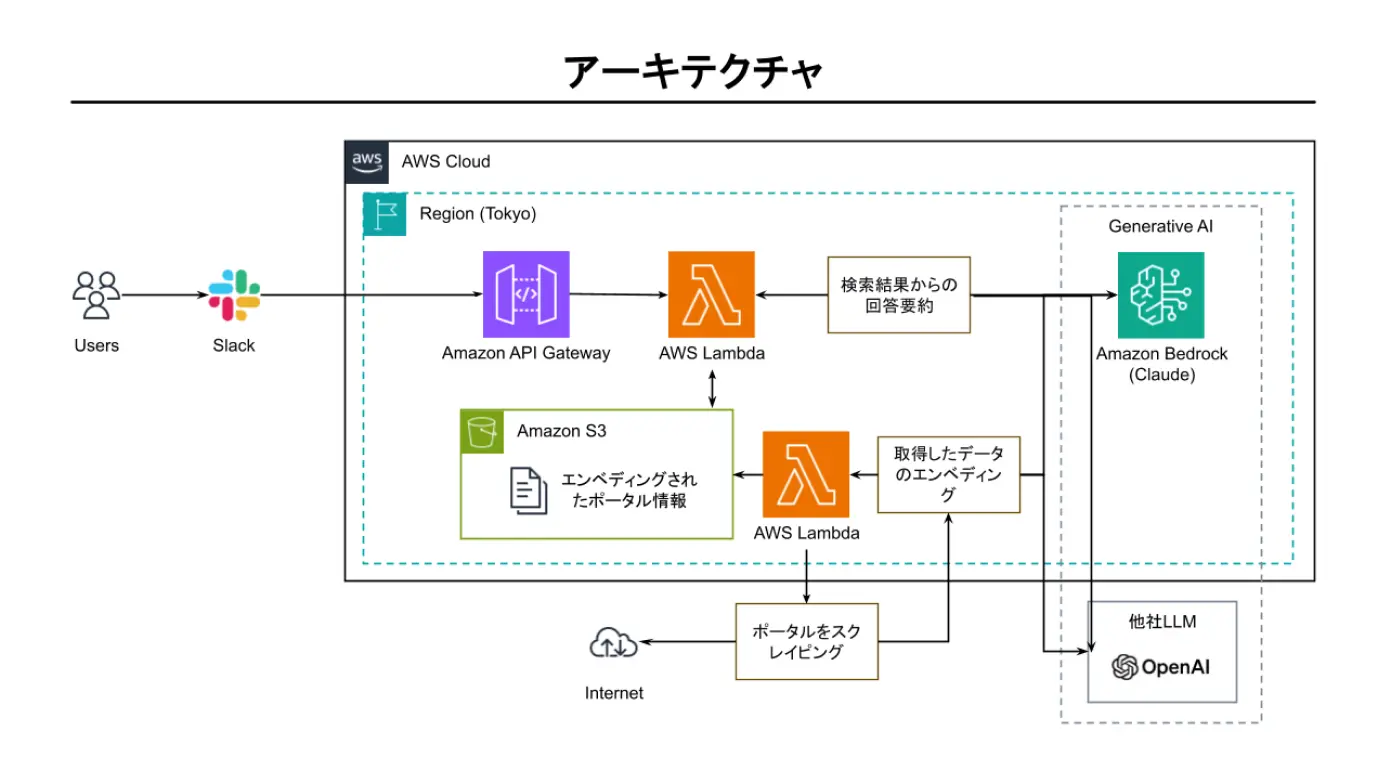
次のような技術を組み合わせて開発を行いました。
- OpenAI GPT
- Google Gemini
- Anthropic Claude / AWS Nova
- LangChain
- LangSmith
- テキスト埋め込み
- ChromaDB
- ハイブリッド検索
- Cohere
- Answer Correctness(正確性)
- Answer Relevance(関連性)
- Faithfulness(忠実性)
AIチャットボットの精度向上に向けた工夫
今回の開発では、AIチャットボットの回答精度を高めるために、生成AIに送るクエリの拡張や、拡張データの改善など、さまざまな工夫を行いました。具体的な取り組みは以下の通りです。
クエリ拡張
ユーザーの意図を確実に把握するため、ユーザーが入力したクエリを元に、3つの異なるバリエーションに展開する仕様としました。
この処理は生成AIを用いて自動化しており、ユーザーは意識することなく適切な応答をしてもらうことができます。
例えば、ユーザーからの「資格取得支援制度の申請の期限は?」という質問に対しては、次のような展開が行われます。
- 「資格取得支援制度の申請期限に関するガイドラインは何ですか?」
- 「社内の資格取得支援の申請を行う際の締切日について教えてください。」
- 「資格支援制度に関連する申請期限の詳細についての規定はどこにありますか?」
このように、ユーザの意図を理解し、クエリを展開することによって、必要な情報を漏らさずに取得できるようにしました。
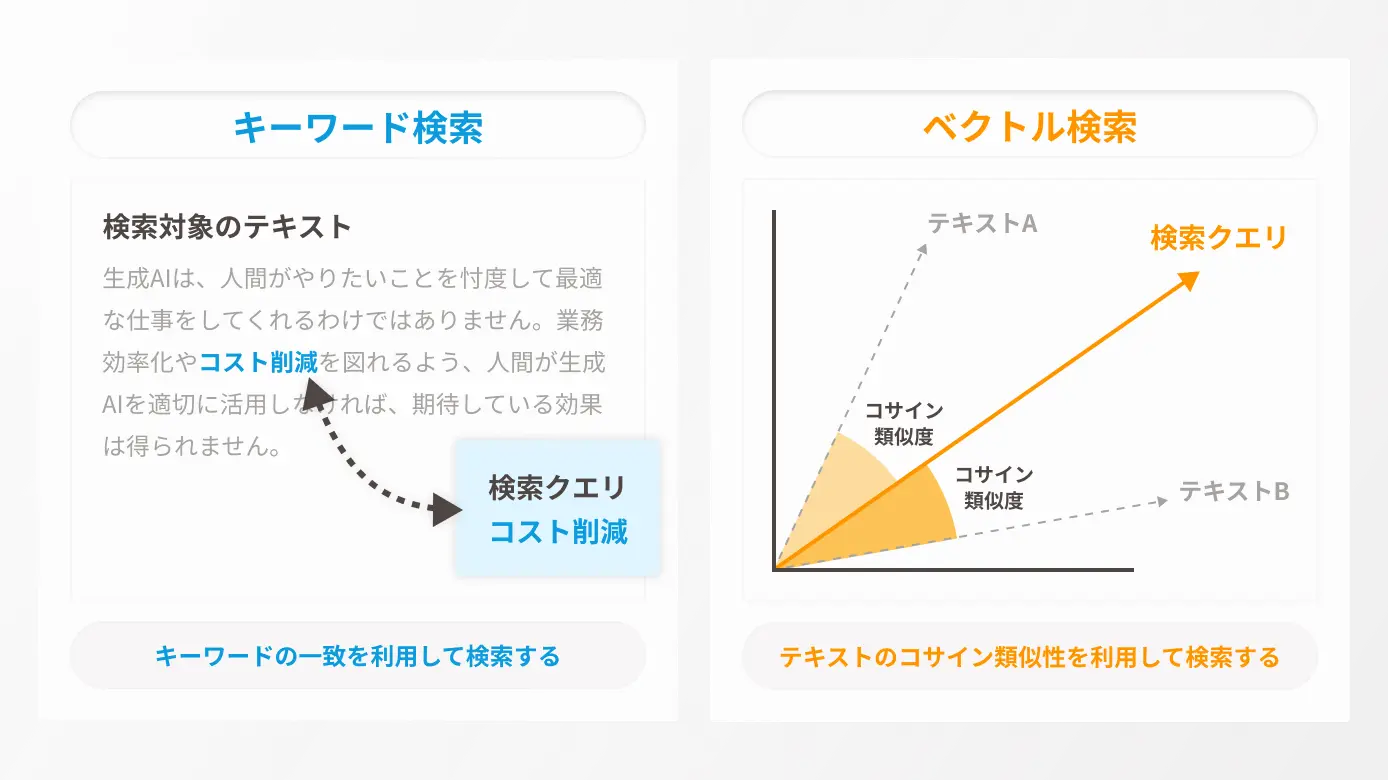
ベクトル検索の導入
ドキュメントデータベースの検索精度を高めるため、「ベクトル検索」技術を導入しました。
ベクトル検索とは、テキストデータを数値ベクトルに変換し、意味的に近い(コサイン類似度が高い)ものを抽出する仕組みです。
一般的なキーワード検索と比べ、文脈や意味の近い情報を見つけやすいという特長があります。
拡張データの改善
マッチング精度をさらに高めるため、拡張データとして利用するドキュメントの構造の最適化や、誤った応答を誘発する可能性のあるドキュメント(例えば「改訂履歴情報」など)の削除を行いました。
以上のような改善によって、より信頼性の高い情報を提供できるようになりました。
AIチャットボットの効果とフィードバック
AIチャットボットによって、以下のような効果が得られました。
必要な情報への迅速なアクセス
従業員が社内の運用に関して疑問を持った際、AIチャットボットに質問することで、即座に回答を得られるようになりました。その結果、「バックオフィス担当者が、質問を受け取り、調査・検討し、回答文を作成して送信する」という一連の業務を大幅に削減することができました。
必要な情報に迅速にアクセスできるようになったことで、社内の運用ルールに対する理解が促進され、組織全体の業務効率が向上しました。
特に、新入社員のオンボーディングが円滑に進むようになった点は、大きな成果と言えます。
ユーザーからの声
ユーザーからは、AIチャットボットについて次のようなフィードバックが寄せられています。
- 先輩や同僚よりも気軽に質問ができるのでありがたい
- 相談相手の時間を奪わずに済むので助かる
- 社内ポータルの該当ページへのリンクを含めて回答されるため、ページを探す手間が無くなった
AIチャットボットの開発を通じて得られた知見と今後の展望
今回の開発を通じて、以下のような重要な知見を得られました。
回答の精度はドキュメント次第
AIチャットボットの回答精度を高めるには、拡張データとして使用するドキュメントの整備が極めて重要であることが分かりました。
情報に不備があったり、構造に曖昧さがあったりすると、回答の精度は大きく低下します。
また、社内特有の専門用語が含まれる場合には、あらかじめ用語を定義するなど、ドメイン知識を正確に生成AIへ伝える工夫も必要です。
生成AIの回答形式には工夫が必要
ユーザーの疑問に的確に答えるには、文章でストレートに回答するだけでは不十分な場合があります。
たとえば、回答候補を箇条書きで示したり、関連ページへのリンクを併せて提示したりすることで、より分かりやすい回答につながることがあります。
また、質問内容が曖昧な場合には、チャットボット側から追加の質問を返すことで、より適切な応答を導くこともできます。
このように、質問の内容に応じて最適な回答形式を選ぶことが重要であると分かりました。
応答履歴の蓄積によるパーソナライズ化
ユーザーごとの応答履歴を蓄積することで、その人の関心や行動傾向を把握しやすくなります。特に、過去のAIチャットボットの回答に対して「良い」「悪い」といったリアクションを得られれば、貴重なフィードバックデータとして活用できます。
こうした履歴データを活かすことで、よりパーソナライズされた、精度の高い回答を提供できる可能性があります。
ユースケースに応じた最適な手法の選定
今回の開発では、RAGと生成AIを組み合わせた手法が高い効果を発揮しました。
一方で、従来型のルールベースのチャットボットや、拡張データを使わずに生成AIへ直接質問する方式が有効なケースも存在します。
また、静的な情報だけでなく外部サービスとの連携が有効な場合には、MCP(Model Context Protocol)を活用し、生成AIと外部システムを統合する手法が効果を発揮すると考えられます。
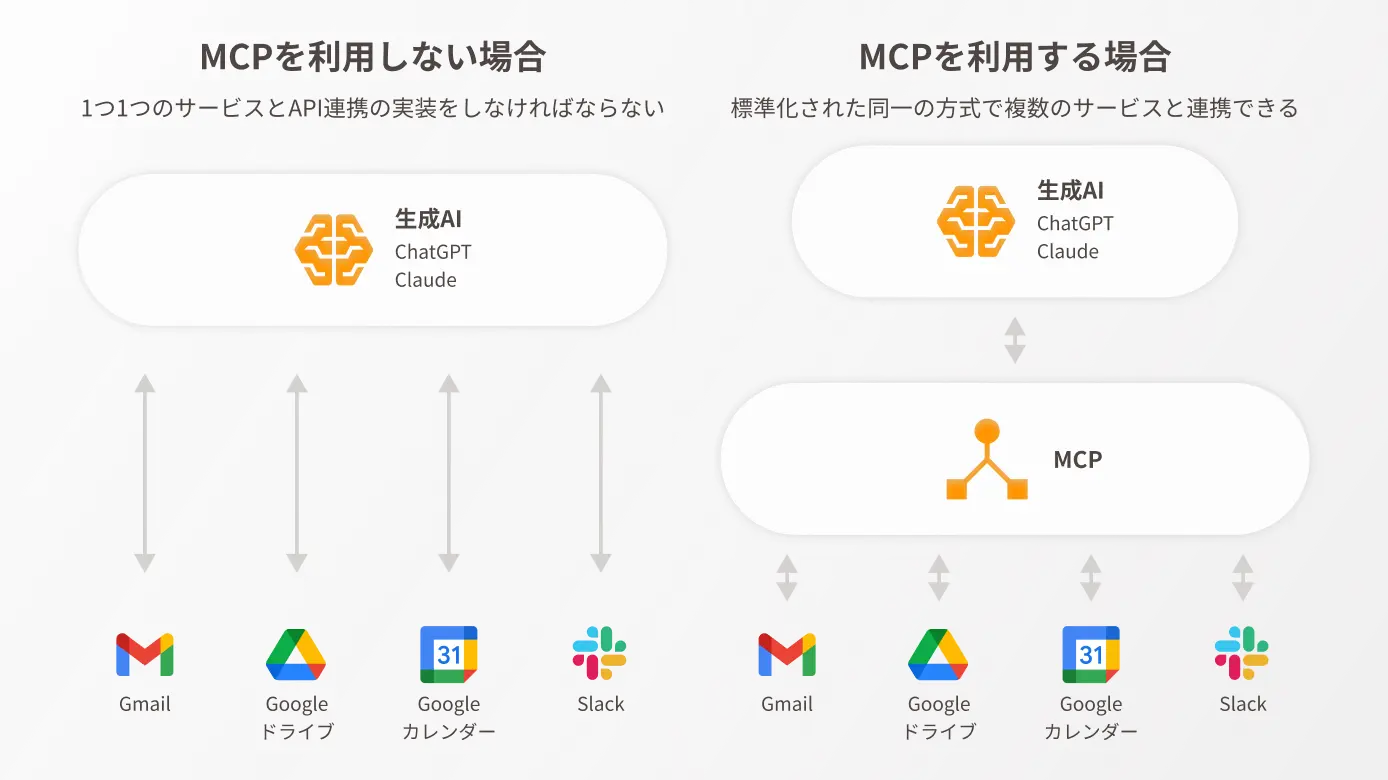
このように、ユースケースに応じて最適な技術や構成を選定することの重要性を、改めて実感しました。
今後は、こうした知見を活かし、より業務に貢献できる実用的なサービスへと発展させていきたいと考えています。
おわりに
今回、RAGと生成AIを活用したAIチャットボットの構築により、社内情報の検索効率を大幅に向上させることができました。
社内のナレッジ活用やDXを推進する企業にとって、RAGは大きな可能性を秘めた手法です。
本事例の詳細についてご関心のある方は、ぜひTech Funまでお気軽にお問い合わせください。


