
生成AI関連
RAGとは?外部情報を参照して回答する生成AIの仕組み
生成AIの用途は、文章作成、要約、分類、コード生成など多岐にわたります。その中でも、社内文書、FAQ、Web上の情報、業務データなどの外部情報を参照して回答する用途では、RAG(Retrieval-Augmented Generation:検索拡張生成)がよく使われます。RAGでは、「どのLLMを使うか」だけでなく、「どの情報を検索するか」が回答品質を大きく左右します。
このとき重要になるのが、外部情報をどのように探し、どの順序でLLMに渡すかという検索設計です。検索設計は、RAGの回答品質を改善するうえで、モデル選定とは別に検討したい要素です。
これまでのRAGでは、テキスト検索、ベクトル検索、ハイブリッド検索がよく使われてきました。近年はさらに、AIエージェントが検索方針を判断し、必要に応じて複数回の検索や検索結果の評価を行う「エージェント検索」も注目されています。
本記事では、RAGにおける検索設計を整理し、テキスト検索、ベクトル検索、ハイブリッド検索、エージェント検索の違いと使い分けを解説します。
なお、RAGの基本的な仕組みや、なぜRAGが必要かといった全体像については、下記の記事で解説しています。RAGをこれから学ぶ場合は、あわせてご覧ください。
ベクトル検索の前提となるエンベディングの仕組みは、下記の記事で紹介しています。本記事では重複を避け、ベクトル検索の詳細な仕組みよりも、検索設計における位置づけに焦点を当てます。
RAGを用いた生成AIシステムは、大きく「検索」と「生成」の2段階で構成されます。
この流れだけを見ると、検索はLLMに情報を渡すための前処理のように見えるかもしれません。しかし近年はLLMの性能が向上した一方で、外部情報を参照する用途では、回答精度が検索結果の質に左右される場面も増えています。
たとえば、社内規程に関する質問に対して、検索で古い規程だけを取得してしまった場合、LLMは古い情報に基づいて回答する可能性があります。また、質問に関係のない文書しか取得できなかった場合、LLMは取得した文書を無理に使って回答したり、回答不可と判断したり、一般論に寄った回答を生成したりする可能性があります。問い合わせ対応のチャットボットでも、質問に関係のないFAQが多く混ざると、回答の根拠が不明確になります。
RAGの検索では、主に次の観点が重要です。
これらは、単に「検索結果を増やす」だけでは解決できません。検索件数を増やせば取りこぼしは減る可能性がありますが、その分ノイズやコストも増えます。検索件数を絞ればノイズは減りますが、必要な文書を取りこぼす可能性があります。
そのため、検索設計では、利用シーンに応じて検索手法を選び、必要に応じて複数の手法を組み合わせることが重要になります。
検索結果や生成結果の評価指標については、下記の記事でも整理しています。
まず、RAGでよく使われる検索手法を整理します。ここでは、テキスト検索、ベクトル検索、エージェント検索、ハイブリッド検索を扱います。
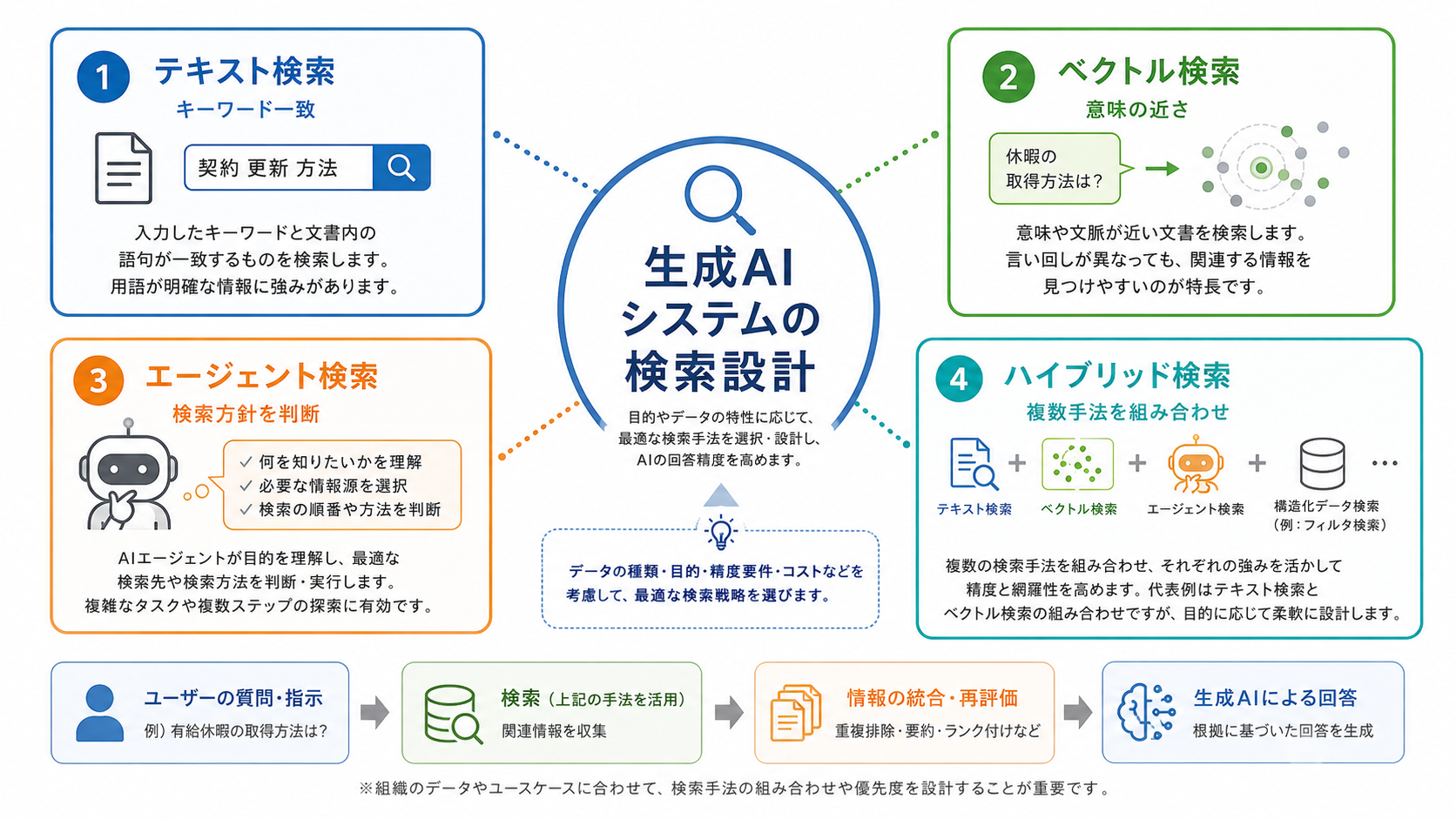
テキスト検索は、キーワードや語句の一致をもとに文書を探す方法です。代表的な例として、全文検索やBM25のような検索アルゴリズムがあります。
テキスト検索は、次のような情報に強い傾向があります。
一方で、表現が異なる場合には検索に失敗しやすいという課題があります。たとえば、「退職手続き」と「離職時の申請」が同じ意味に近くても、キーワードが一致しなければ上位に出ない可能性があります。
ベクトル検索は、文章をエンベディングに変換し、意味的に近い文書を取得する方法です。キーワードが一致していなくても、意味が近い文書を探せる点が特徴です。
エンベディングとベクトル検索の詳しい仕組みは、下記の記事で解説しています。
たとえば、「引っ越ししたときの申請」と質問した場合に、「住所変更届」「通勤経路変更」「住民票の提出」といった関連文書を取得できる可能性があります。これは、表現の一致ではなく意味の近さを利用しているためです。
一方で、ベクトル検索は万能ではありません。型番、コード、日付、短い固有名詞など、文字列としての一致が重要な情報では、テキスト検索の方が適している場合があります。また、意味的には近いものの、ユーザーの質問に対する直接の答えではない文書が上位に出ることもあります。
本記事では、AIエージェントが検索方針を判断し、必要に応じて複数回の検索、検索クエリの再設計、検索結果の評価を行う方式を「エージェント検索(Agent Search)」と呼びます。英語圏では Agentic Search と表記されることも多く、日本語では「エージェンティック検索」「エージェンティックサーチ」などの呼び方も見られます。
Google Agent Development Kit(ADK)のドキュメントでは、エージェントが検索方法を推論し、検索クエリを動的に構築する考え方が紹介されています。
参考:Grounding agents with data – Agent Development Kit
エージェント検索の特徴は、検索を1回の固定処理として扱わない点です。従来型の検索拡張構成では、ユーザーの質問を受け取ると、あらかじめ決められた検索処理を実行し、その結果をLLMに渡します。一方、エージェント検索では、LLMやエージェントが検索プロセスに関与します。
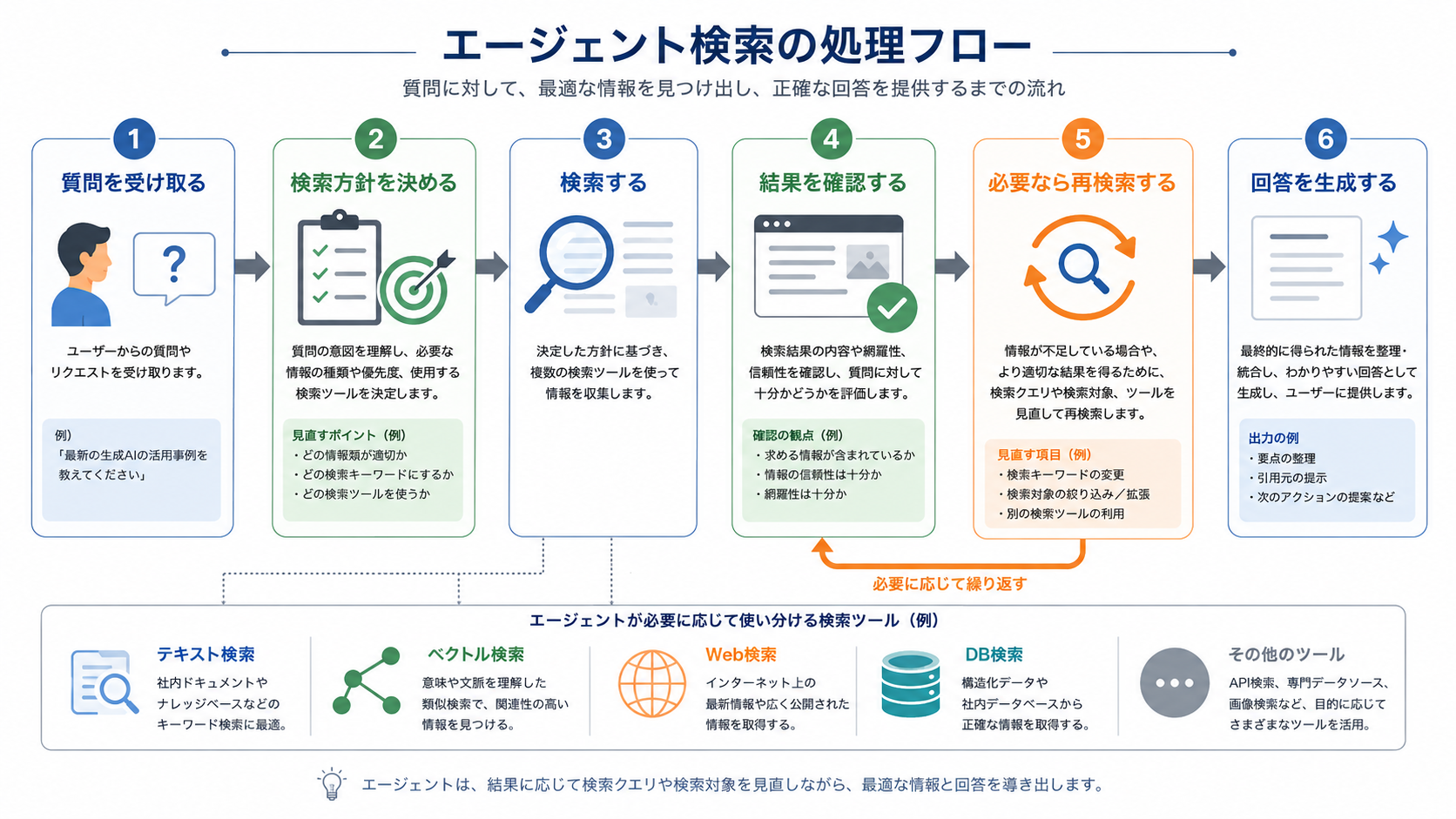
典型的には、次のような流れになります。
重要なのは、エージェント検索が「ベクトル検索の代替」ではないという点です。むしろ、テキスト検索やベクトル検索などのさまざまな検索手段を、エージェントが必要に応じて使い分ける構成と捉える方が自然です。
ただし、エージェントが使える検索手段は、事前に用意された環境、権限、ツールに依存します。たとえば、ChatGPTにGoogle Driveへのアクセス権限を付与すると、エージェントがGoogle Drive内のファイルを参照して調査できる場合があります。しかし、それだけでベクトル検索やリランクが実行されるとは限りません。ベクトル検索を使うには、文書をエンベディング化して検索できる基盤や、その基盤を呼び出すツールが別途必要です。
たとえば、そのような検索基盤やツールが用意されていれば、エージェントは最初にキーワード検索で正式な規程名を探し、その後ベクトル検索で関連する説明資料を探し、さらに検索結果が不足していれば別の検索クエリで調べ直すことができます。このように、用意された検索手段を組み合わせて目的に近づくのがエージェント検索の考え方です。
ハイブリッド検索は、複数の検索手法を組み合わせる方法の総称です。必ずしもテキスト検索とベクトル検索の組み合わせだけを指すわけではありません。
ただし、RAGの文脈では、テキスト検索とベクトル検索を組み合わせる構成をハイブリッド検索と呼ぶことが多くあります。キーワード一致の強さと意味検索の柔軟性を両立しやすいため、実務でもよく使われます。
たとえば、次のような検索が可能になります。
ハイブリッド検索は、単一の検索手法で精度が出にくい場合の改善策として有効です。ただし、検索結果の統合方法、重み付け、リランクなどをどう設計するかによって品質が変わります。
| 検索手法 | 得意なこと | 注意点 |
|---|---|---|
| テキスト検索 | 固有名詞、型番、コード、明確なキーワードの検索 | 表現ゆれや曖昧な質問に弱い |
| ベクトル検索 | 意味が近い文書の検索、曖昧な質問への対応 | 正確な文字列一致や細かい条件指定に弱い場合がある |
| エージェント検索 | 検索方針の判断、複数回検索、情報源の使い分け | コスト、遅延、再現性、評価の難しさが増える |
| ハイブリッド検索 | 複数の検索手法を組み合わせた検索 | 結果統合やランキング設計が必要 |
ハイブリッド検索とエージェント検索は混同されやすい概念です。どちらも複数の検索手法を扱い、構成によっては検索クエリの変換やリランクなどにAIを使うこともあるためです。ただし、両者は整理する観点が異なります。
ハイブリッド検索は、複数の検索手法を設計した構成に沿って組み合わせる考え方です。テキスト検索とベクトル検索の組み合わせが代表的で、取得した検索結果を統合し、必要に応じてリランクします。クエリ変換やリランクにAIを使う場合もありますが、主な関心は「どの検索手法を固定的な検索構成として組み込み、結果をどう統合するか」にあります。
一方、エージェント検索は、検索プロセスの制御方法です。エージェントが質問の内容や途中の検索結果を見て、検索手法、検索対象、検索クエリ、検索回数、確認すべき観点などを動的に変えます。必要に応じて、ハイブリッド検索をツールの一つとして利用することもあります。
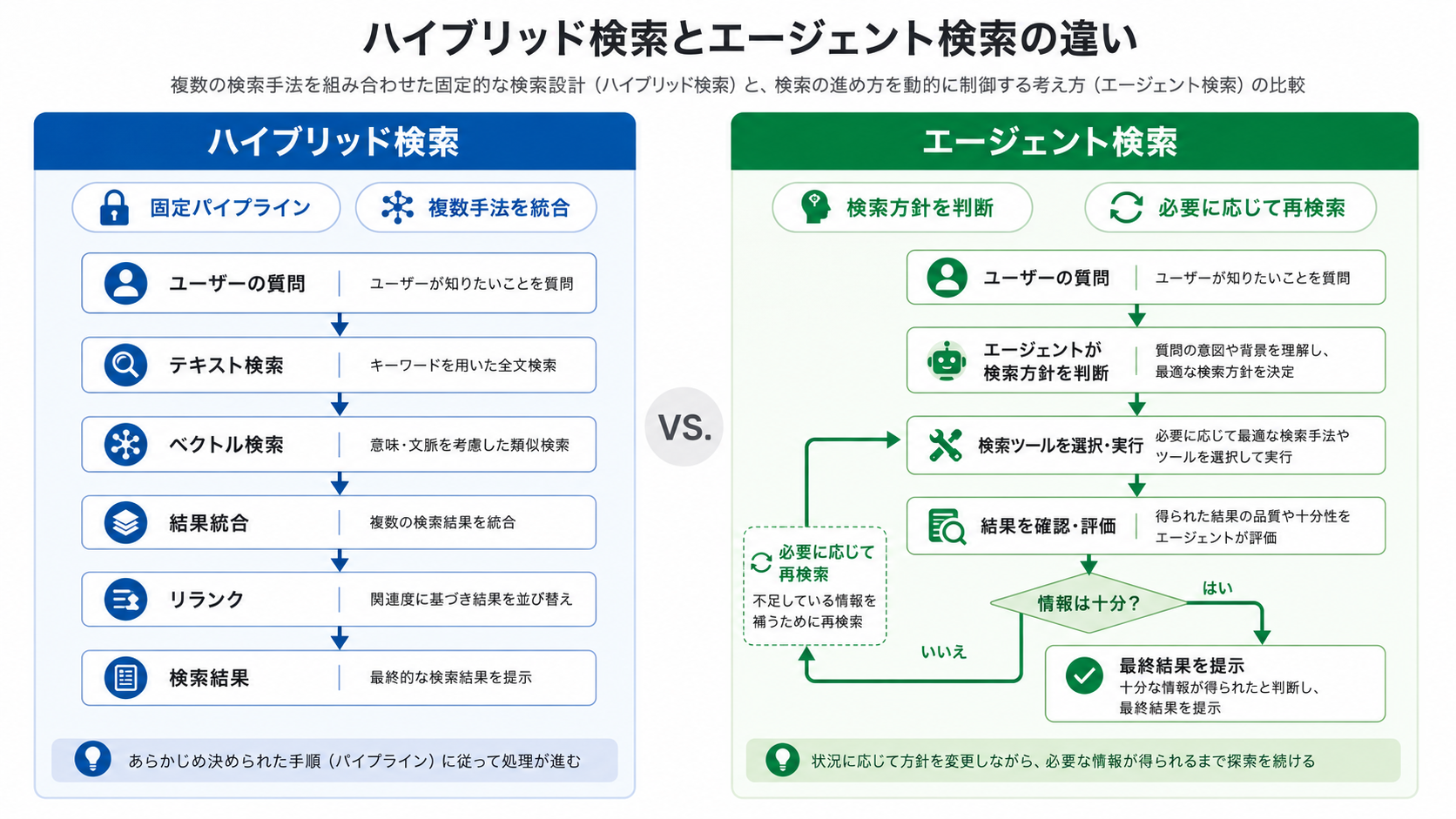
| 観点 | ハイブリッド検索 | エージェント検索 |
|---|---|---|
| 主な目的 | 複数の検索手法を固定的な構成として組み合わせる | 質問や検索結果に応じて検索方針を動的に決める |
| 検索回数 | 設計した検索構成に従う | 必要に応じて複数回実行する |
| 検索クエリ | ユーザー入力、定型変換、AIによる変換など | エージェントが状況に応じて再設計する |
| 利用する検索手段 | 設計した検索構成に従う | テキスト検索、ベクトル検索、Web検索などを動的に利用 |
| 強み | 速度、再現性、運用のしやすさ | 複雑な調査、条件分解、複数情報源の横断 |
| 注意点 | 設計した範囲外の調査には弱い | コスト、遅延、再現性、評価の難しさが増える |
つまり、ハイブリッド検索は「検索エンジンの設計」に近く、エージェント検索は「検索の進め方の設計」に近いと言えます。
実務では、ハイブリッド検索とエージェント検索を対立する選択肢として考える必要はありません。まずテキスト検索やベクトル検索を単体で評価し、必要に応じてハイブリッド検索に発展させ、その上にエージェント検索を載せる構成も有効です。
検索手法の選定では、技術的な新しさよりも、対象業務の性質を優先することが重要です。ここでは、実務での使い分けを整理します。
| 利用シーン | 検索設計の例 | 理由 |
|---|---|---|
| FAQ検索 | テキスト検索またはハイブリッド検索 | 質問と回答の対応が比較的明確で、速度と安定性が重要 |
| 社内文書検索 | ハイブリッド検索 | 表現ゆれと固有名詞の両方に対応しやすい |
| 規程・契約書検索 | テキスト検索またはハイブリッド検索 | 正確な用語、条項、日付、版管理が重要 |
| 技術調査 | エージェント検索 | 複数の文書や情報源を横断し、段階的に調査する必要がある |
| 障害調査 | エージェント検索 | ログ、仕様書、過去チケットなどを順番に確認する必要がある |
※ 上記はあくまで一般的なケースの例です。実際の検索設計は、検索対象のデータ、求められる応答速度、精度要件、運用体制、利用できるツールなどに応じて変わります。
最初からハイブリッド検索やエージェント検索を前提にする必要はありません。まずテキスト検索やベクトル検索を単体で評価すると、検索品質のネックがキーワード一致、意味検索、チャンキング、リランクなどのどこにあるのかを切り分けやすくなります。
そのうえで、単一の検索手法では補いにくい課題が見えてきた場合に、ハイブリッド検索を検討するのが現実的です。
一方で、次のような要件が出てきた場合は、エージェント検索の導入を検討する価値があります。
このようなケースでは、検索を固定パイプラインとして扱うよりも、エージェントに検索方針を判断させる方が適している場合があります。
エージェント検索は柔軟性が高い一方で、導入時に考えるべき点も増えます。
エージェント検索では、検索、結果確認、再検索、回答生成といった処理が複数回発生します。そのため、固定的な検索構成よりもLLM呼び出し回数や検索回数が増え、コストと応答時間が増加しやすくなります。
特に、顧客向けチャットボットのように応答速度が重要なサービスでは、すべての質問をエージェント検索にするのではなく、複雑な質問だけに限定する設計が現実的です。
固定的な検索パイプラインでは、同じ入力に対して同じ検索処理を実行しやすいため、評価と改善が比較的行いやすくなります。一方、エージェント検索では、エージェントが検索クエリや検索回数を変えるため、挙動のばらつきが増える可能性があります。
そのため、検索ログ、ツール呼び出しログ、取得文書、最終回答を記録し、どのステップで品質が変わったのかを確認できるようにしておく必要があります。
エージェント検索では、複数のツールやデータソースを横断する構成になりやすくなります。そのため、ユーザー権限に応じた検索制御が重要です。
たとえば、社内文書検索であれば、ユーザーが閲覧権限を持たない文書を検索結果に含めてはいけません。業務APIやデータベースに接続する場合も、エージェントが実行できる操作を必要最低限に制限する必要があります。
エージェント検索を導入しても、検索対象の文書が整理されていなければ品質は安定しません。文書の更新管理、不要文書の除外、検索評価データの整備は引き続き重要です。
エージェント検索は、検索基盤の不足をすべて解消する仕組みではありません。むしろ、整理された検索基盤を前提に、複雑な検索プロセスを柔軟に扱うための仕組みとして捉えるのが適切です。
本記事では、RAGの検索設計を、テキスト検索、ベクトル検索、ハイブリッド検索、エージェント検索の観点から整理しました。
RAGの検索設計では、新しい手法を採用すること自体が目的ではありません。ユーザーの質問に対して、必要な根拠を、適切な粒度で、安定して取得できることが重要です。
まずはテキスト検索やベクトル検索を単体で試し、検索品質のネックを把握する。そのうえで、必要に応じてハイブリッド検索で補完し、1回の検索では対応しにくい領域に対してエージェント検索を検討する。この順序で考えると、RAGの検索設計を段階的に改善しやすくなります。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。



