
生成AI関連
生成AI用語・ツール早わかりマップ
生成AIを業務で使い始めると、「社内のルールを聞いても正しく答えてくれない」「最新の情報を知らない」「事実と異なる内容を、もっともらしく回答する」といった場面に直面します。これらは、LLM(大規模言語モデル)が学習済みの知識だけで回答していることに起因します。
こうした課題に対する代表的な解決策が、RAG(Retrieval-Augmented Generation:検索拡張生成)です。RAGは、回答の前に外部の情報を検索し、その内容を根拠としてLLMに渡す仕組みで、企業の生成AI活用では定番の構成になりつつあります。
本記事では、RAGとは何か、なぜ必要なのか、どのような仕組みで動くのかを、これからRAGに取り組む方に向けて整理します。エンベディング、検索設計、構築手順、評価といった個別のテーマには深入りせず、それぞれの関連記事への入り口となる内容を目指します。
なお、生成AIまわりの用語を幅広く整理したい場合は、下記の記事もあわせてご覧ください。
RAGは、Retrieval(検索)とGeneration(生成)を組み合わせた手法です。ユーザーの質問に対して、まず外部の情報源から関連する文書を検索し、その内容をLLMに渡したうえで回答を生成させます。
LLM単体では、モデルが学習した知識の範囲でしか回答できません。RAGは、その回答プロセスに「検索」というステップを追加し、LLMが本来知らない情報に基づいて回答できるようにする仕組みだと考えると理解しやすくなります。
処理の流れは、大きく2つのステップに分かれます。
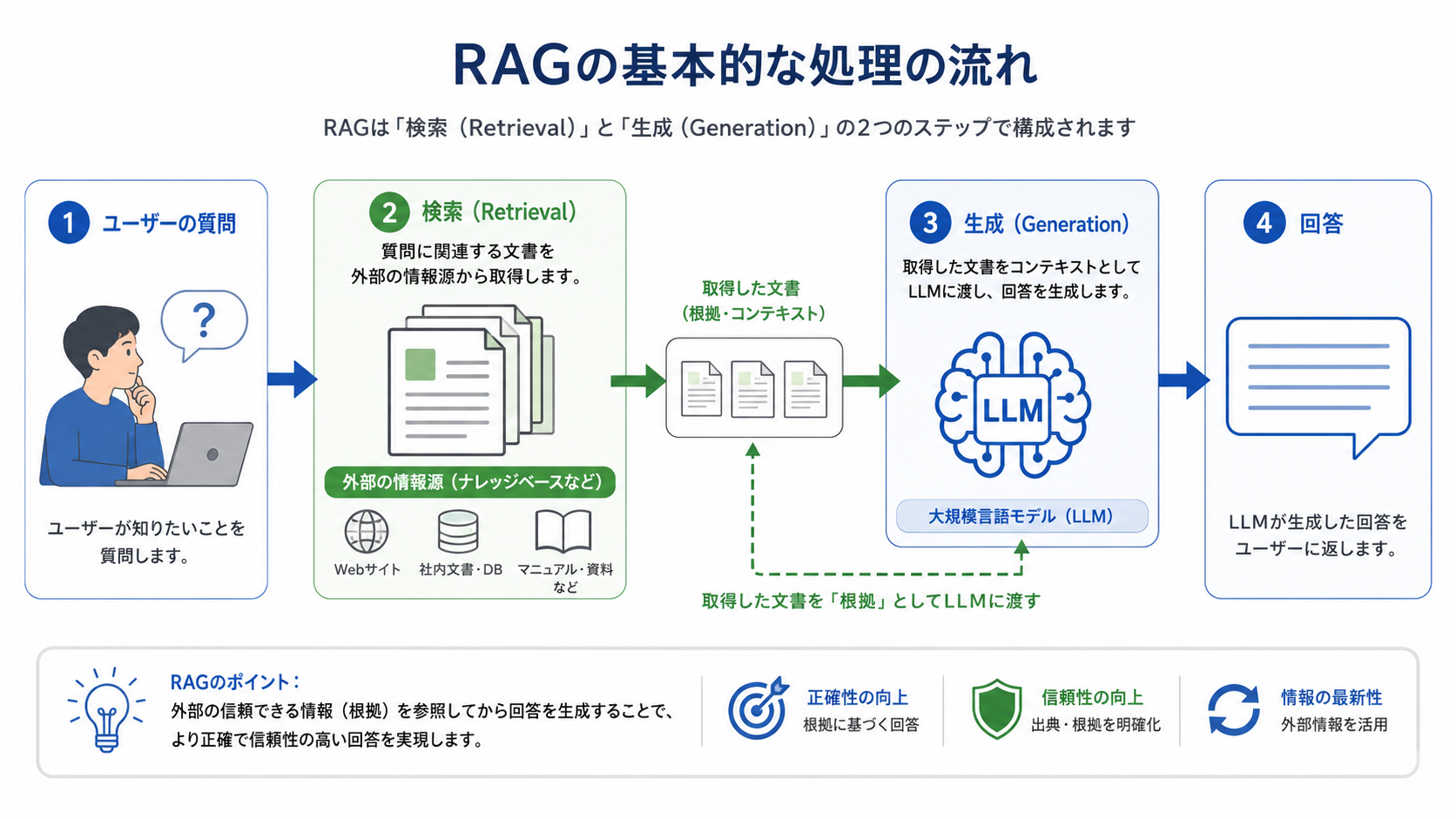
この「検索してから生成する」という流れが、RAGの最も基本的な考え方です。LLMは渡された文書を読んで回答するため、社内文書や最新情報など、モデルが学習していない情報にも対応できるようになります。
RAGの必要性を理解するには、LLM単体が抱える課題を整理するのが近道です。主な課題は次の3つです。
LLMは、学習に使われたデータの範囲でしか知識を持ちません。そのため、社内規程、製品マニュアル、業務データといった、一般に公開されていない情報については回答できません。これらの情報は、検索によって都度LLMに渡す必要があります。
LLMには、学習データの収集時点という区切りがあり、それ以降の出来事を知りません。この区切りは知識のカットオフと呼ばれます。最新の情報や頻繁に更新される情報を扱う場合、モデルの学習だけに頼ると古い回答になりかねません。
知識のカットオフについては、下記の記事で詳しく解説しています。
LLMは、事実かどうかにかかわらず、もっともらしい文章を生成することがあります。これはハルシネーションと呼ばれます。RAGでは、検索で取得した文書を根拠として回答させることで、回答の出どころを示しやすくなり、根拠のない回答が生じるリスクを下げる効果が期待できます。
ただし、RAGはハルシネーションを完全になくす仕組みではありません。検索で適切な文書を取得できなかった場合や、取得した文書をLLMが正しく解釈できなかった場合には、誤った回答が生成されることがあります。RAGはハルシネーションのリスクを低減する手段であり、ゼロにするものではないという点は押さえておく必要があります。
これらの課題を整理すると、次のようになります。
| LLM単体の課題 | 内容 | RAGによる対応 |
|---|---|---|
| 非公開情報を知らない | 社内文書や業務データは学習されていない | 検索で関連文書を取得し、文脈として渡す |
| 知識に鮮度の限界がある | 学習時点以降の情報を持たない | 更新された情報源を検索対象にする |
| ハルシネーションが起こる | 根拠のない、もっともらしい回答が生成される | 取得した文書を根拠として提示し、リスクを下げる(完全には防げない) |
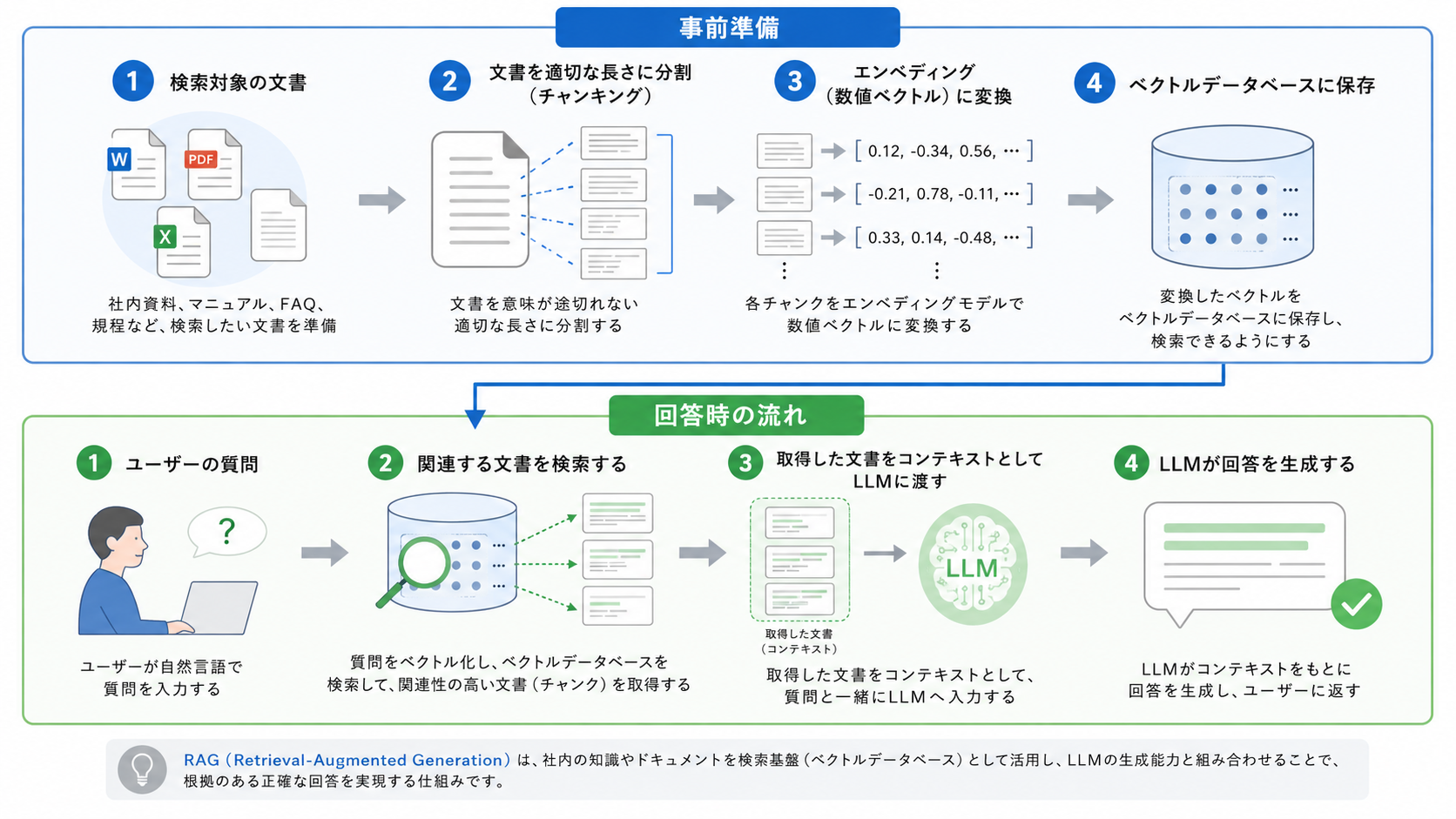
RAGを動かすには、回答時の処理だけでなく、事前の準備が必要です。検索対象の文書を準備する方法は検索手法によって異なりますが、ここではRAGにおいて広く使われている、ベクトル検索を用いる構成を例に説明します。
この場合、多くは次のような事前準備を行います。
この準備を済ませておくことで、ユーザーの質問が来たときに、意味の近い文書を素早く検索できるようになります。
ここで登場するエンベディング(埋め込み表現)は、文章の意味を数値ベクトルで表す技術で、意味の近い文書を探すベクトル検索の基盤となります。本記事では内部の仕組みには踏み込まないため、詳しく知りたい場合は、下記の記事をご覧ください。
なお、検索の方法はベクトル検索だけではありません。キーワードの一致で文書を探すテキスト検索など複数の手法があり、それぞれ得意・不得意があります。事前準備の内容も、採用する検索手法によって変わります。
回答時の流れは次のとおりです。
LLMに独自の知識を反映させる方法は、RAGだけではありません。よく比較されるのが、ファインチューニングと、コンテキストにすべての情報を詰め込む方法です。
ファインチューニングは、追加のデータでモデル自体を再学習させ、知識や振る舞いをモデルに取り込む方法です。一方、RAGはモデルを変更せず、必要な情報を回答時に外部から渡します。情報の更新が頻繁な用途では、文書を差し替えるだけで対応できるRAGの方が運用しやすい場面が多くあります。
コンテキストにすべての情報を渡す方法は、対象となる情報が少なければ有効です。ただし、LLMが一度に受け取れる情報量には上限があります。この上限はコンテキストウィンドウと呼ばれ、社内文書全体のように情報量が膨大な場合は、そもそもすべてを渡しきれないことがあります。
仮にコンテキストウィンドウに収まる場合でも、毎回すべてを渡すとコストや処理量が大きくなり、関係のない情報がノイズとなって回答精度が下がることもあります。RAGは、質問に関連する部分だけを検索して渡すことで、これらの問題を緩和します。
| 手法 | 知識の持たせ方 | 向いている場面 |
|---|---|---|
| RAG | 回答時に外部情報を検索して渡す | 情報の更新が多い、対象データが大量にある |
| ファインチューニング | 追加学習でモデル自体に取り込む | 文体や定型的な振る舞いを固定したい |
| 全文をコンテキストに渡す | すべての情報を一度に渡す | 参照する情報が少なく、その場限りで完結する |
これらは排他的な選択肢ではなく、組み合わせて使うこともあります。まずは運用のしやすさからRAGを起点に検討するケースが多くなっています。
RAGは、外部の情報を参照して回答する用途で幅広く活用されています。代表的な例は次のとおりです。
いずれも、「組織の中にある情報を、LLMに正しく参照させたい」という点で共通しています。たとえば社内ポータル向けのAIチャットボットでは、ユーザーの問い合わせ文をもとに社内ドキュメントを検索し、関連性の高い資料を踏まえて回答する、といった形でRAGが使われます。
RAGの全体像をつかんだら、次は具体的な検討に進みます。RAGの品質は、「どのLLMを使うか」だけでなく、「どの情報をどう検索するか」に大きく左右されます。
検索の品質を高めるには、テキスト検索、ベクトル検索、ハイブリッド検索といった検索手法の使い分けが重要です。検索手法ごとの特徴や使い分けについては、別の記事で改めて取り上げる予定です。
実際に手を動かして構築してみたい場合は、マネージドサービスを使うと、検索基盤の多くを任せた状態でRAGを試せます。構築手順の例は下記の記事で紹介しています。
そして、構築したRAGが期待どおりに機能しているかを判断するには、評価が欠かせません。何を、どう測ればよいかについては、下記の記事で整理しています。
本記事では、RAGの基本的な考え方を整理しました。
RAGは、生成AIを社内の情報と結びつけ、実務で役立つ回答を得るための基盤となる仕組みです。まずは全体像を押さえたうえで、検索設計や評価といった個別のテーマに進むことで、品質を着実に高めていけます。
Tech Funでは、お客様のフェーズに合わせ、生成AI活用に向けた支援を3つのパックでご提供しています。
生成AIに限らず、Web・業務システム開発やインフラ設計など、技術領域を問わずご相談を承っています。「何から始めれば良いか分からない」という段階でも構いませんので、ぜひお気軽にお問い合わせください。
